

?桔妹導讀:定位是所有LBS服務的基礎服務,在滴滴的業務場景下,定位主要是指各類終端設備的位置,包括手機、單車、行車記錄儀、車機端等,作為底層服務,在滴滴日均提供700億次定位服務,支撐著平臺的各類業務,
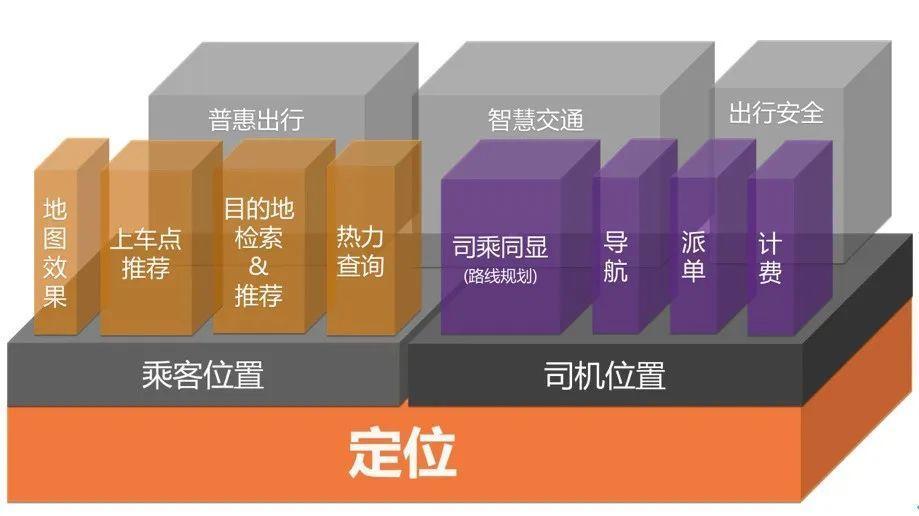
今天給大家分享的是機器學習在滴滴網路定位中的實踐作業,會重點介紹三階段的演進:無監督模型、有監督回歸模型、端到端CNN模型,
1. 什么是網路定位
目前定位技術主要包括GPS、網路定位、慣性航位推算、MM(地圖匹配)、視覺定位等,GPS是最為人熟知的定位技術,是依靠設備與衛星互動來獲取經緯度的方式,GPS精度高,但有冷啟動耗時長、耗電大、遮擋場景不可用等缺點,在滴滴場景下,乘客和司機在有遮擋的場景下,例如室內、高架下等,GPS通常處于不可用狀態,這時就需要有其他定位技術作為GPS的補充,使得乘客發單、司機導航等服務依然可用,其中最主要的補充便是網路定位,
室內類場景雖然有遮擋,但設備通常可以掃描到Cell(基站)和Wifi串列,而且Cell和Wifi設備位置相對穩定,連接其上的設備可以借其定位,這就產生了網路定位,網路定位包括wifi定位和基站定位,是指基于終端掃描到的wifi或基站串列進行的定位技術,Wifi的接入設備通常稱為AP(Acess Point),方便起見,下文將AP和基站統稱為AP,
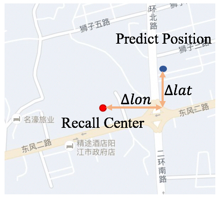
網路定位通常采用的是指紋定位技術,是一個根據query匹配指紋庫資訊,并計算得到坐標位置的程序,如下圖所示,網路定位系統主要包括離線建庫和在線定位兩個階段,
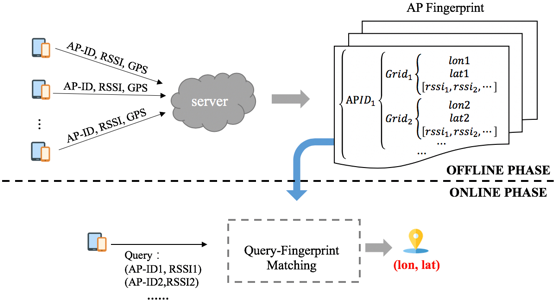
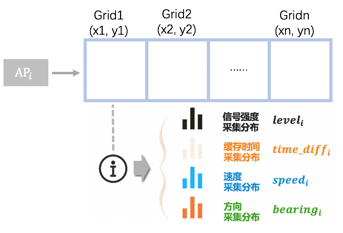
離線建庫主要是基于有GPS時的采集資料,建指紋庫的程序,指紋庫中記錄AP的各類資訊在不同地理網格內的采集資料分布,如下圖所示,
在線階段,根據線上query匹配指紋庫資訊,并計算得到坐標位置,
本文介紹的主要是在線定位部分,即query匹配指紋庫、計算坐標位置,
2. 網路定位匹配演算法迭代
在線定位演算法共經歷了無監督概率模型、有監督回歸模型、端到端CNN模型三次大的迭代,前兩個階段的網路定位主要包括網格召回、網格排序、網格平滑三步,如下圖圖一所示,端到端CNN模型去除了網格排序和網格平滑,基于一個召回中心點,直接回歸位置坐標,如下圖圖二所示,
▍2.1 無監督概率模型
網路定位要完成在線AP與離線AP指紋庫的匹配,是聯合概率計算的程序,以AP指紋庫的信號強度分布為例,看下網格概率計算程序,
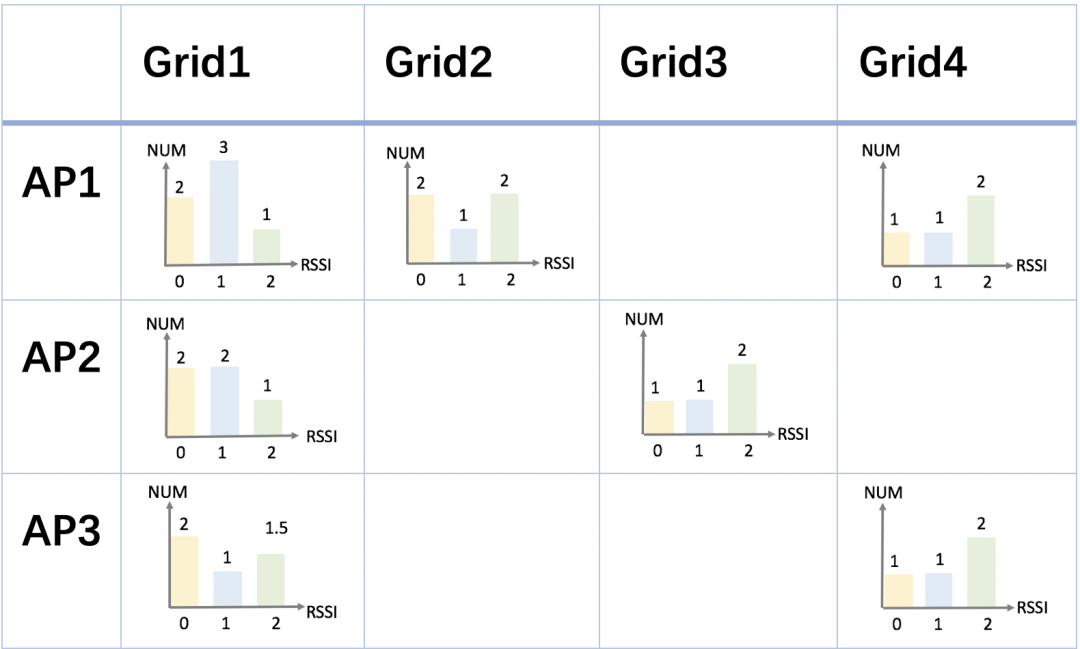
縱軸為采集資料中的AP編號,橫軸為空間網格編碼,相交點表示每個AP在對應網格中的采集信號強度分布,空值表示AP在對應的位置無采集資料,
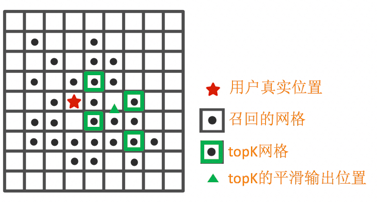
以一個實時定位query資訊:(AP1:RSSI=1,AP3:RSSI=0)為例,介紹網格召回、排序、平滑的程序,
召回階段,基于掃描到的AP1和AP3,可以召回Grid1、Grid2、Grid4;
排序階段,結合離線AP庫,基于獨立性假設和貝葉斯公式,計算各網格的權重:
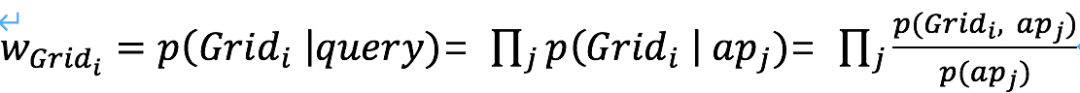
 表示觀測到的APj的資訊,以信號強度RSSI單一特征為例,上例中,
表示觀測到的APj的資訊,以信號強度RSSI單一特征為例,上例中,
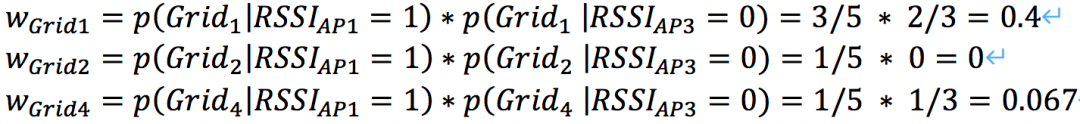
網格平滑階段,基于上述的統計概率,排序獲取TopK個網格,采用爬山法求解最優坐標:
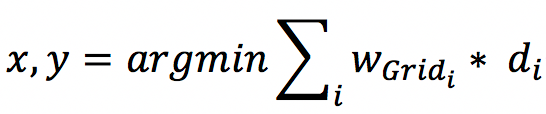
其中,
為預測位置到 的距離,
的距離,
▍2.2 有監督回歸模型
無監督概率模型的方法,思路清晰易懂,易實作,是早期網路定位的主要方式,但有以下問題:
-
聯合概率的方式對采集資訊不充分的位置不友好,例如上例
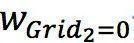
-
難以擬合多維特征,尾部badcase較嚴重
-
技術目標無法得到直接優化,天花板較低
出于對以上問題的思考,整體流程仍保持網格召回、排序、平滑三階段,我們將網格排序升級為有監督回歸模型,通過引入多元特征和顯式的優化目標,實作對網格的更精準打分,
Label:待預測網格與真實位置的位置偏差,回歸任務,
特征工程:構建近百維特征,主要包含AP特征,網格特征,前文資訊等,
模型選擇:一期上線GBDT模型;二期對比了GBDT、FM、DeepFM、FM+GBDT等,最終線上最優融合模型結構如下,
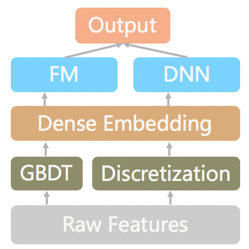
原始特征中的稠密特征和低維稀疏特征經過GBDT進行特征組合、交叉;GBDT輸出的葉子節點編號與高維稀疏特征經過DeepFM網路,最終輸出網格與真值的位置偏差,
TopK網格平滑:預測偏差距離從小到大排序,截取TopK網格;爬山法,梯度下降求解最優坐標,
▍2.3 端到端CNN模型
有監督模型在特征利用、模型結構、優化目標等方面提供了更大的操作空間,可以極大地打開天花板,上線后定位精度等指標取得了顯著的收益,
但該方法仍有以下問題:
-
每個網格孤立刻畫,資訊采集時的不均衡、有偏的問題無法有效解決
-
TopK平滑層與排序層割裂,無法聯合優化,且引入部分人工超參
對于以上問題,考慮以下解決方案:
-
CNN網路:充分利用空間資訊的區域相關性,增強特征的提取能力
-
端到端網路:合并排序與平滑層,改為直接回歸位置坐標,目標更統一,減少人工超參
最終,整體網路結構如下:

下面以基站定位為例,介紹該結構的實作細節,
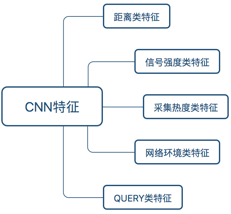
首先介紹下輸入特征的構建:
-
Wide網路特征:表達Query資訊的Wide特征共十幾維
-
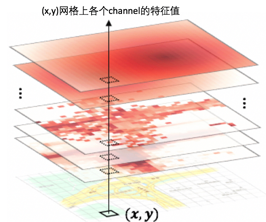
CNN特征圖的構建:
-
召回中心:采集熱度較高的TopN網格的經緯度中位數作為圖的中心點,
-
特征圖構建:選取C維圖特征,每一維特征為一個channel;基于召回中心,構建M*M解析度的特征圖,
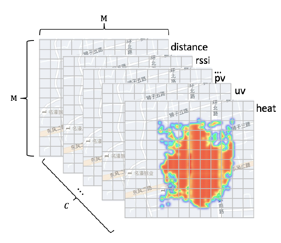
網路結構:在CNN網路部分,采用多尺度卷積核提取特征后,經過兩個卷積+池化層后,將特征圖打平,Wide部分稀疏特征經過embedding后,與稠密特征級聯,兩部分tensor級聯后經過全連接層,最終輸出與召回中心點的位置偏差,
Label與Loss:label為真實位置與召回中心位置的偏移dx和dy,召回中心點+預測偏移即得預測位置,loss最初使用的是經緯度的L2 loss:
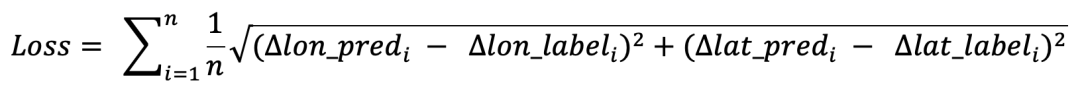
考慮到經緯度在球面上表達距離的差異,我們改為了使用球面距離偏差作為label,也獲得了穩定的收益:
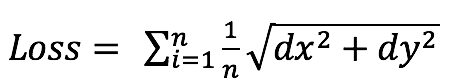 ,dx和dy表示真實空間距離
,dx和dy表示真實空間距離
CNN模型在線上AB實驗取得了顯著的收益,已全量上線,CNN端到端模型升級了資訊的表達方式,由單網格、結構化的資訊表達改為了Image的表達方式,配合cnn網路結構,獲取了效果的顯著提升;并且將幾十甚至幾百個網格的預測問題改為了單次位置回歸問題,雖然模型復雜度有所增加,但整體性能基本持平,
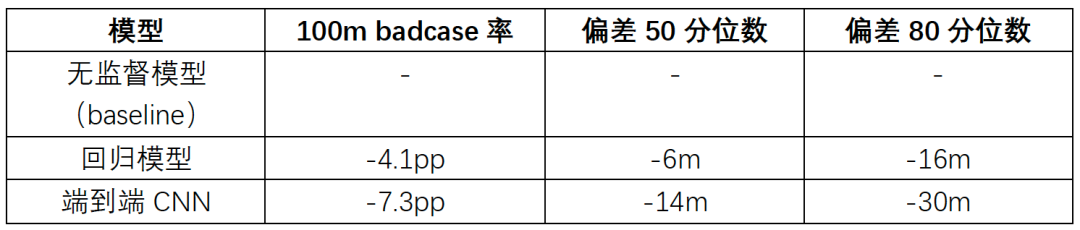
▍2.4 線上效果
網路定位三階段的模型先后上線進行了AB對比實驗,以基站定位三個主要技術指標為例,對比結果如下表所示:
3. 總結與展望
本文總結了定位策略團隊在網路定位演算法側的作業,介紹了無監督概率模型、有監督回歸模型、端到端CNN的演進及其中的思考,
無GPS時的定位仍面臨著很多困難,未來我們將在以下方面持續探索:
-
模型效果優化:
目前CNN模型在基礎資訊利用、召回等方面仍有較大優化空間,
-
性能問題:
考慮線上性能,在基礎資訊和網路結構上做了很多刪減,期望通過更優的召回策略、蒸餾剪枝等平衡效果與性能,
-
5G技術:
5G的天然優勢(高頻率、高密度、低延時)也必定會帶來定位精度的顯著提升,相關調研作業正在進行,
-
復雜場景定位:
對于室內、地下停車場等典型復雜場景,網路定位面臨著真值獲取難、移動ap等難點,細分場景也逐漸向模型化方向演進,
以上就是滴滴網路定位近期作業的實踐介紹,歡迎隨時交流,
本文作者

2017年加入滴滴,目前從事地圖定位演算法方向,多年LBS領域演算法研究作業,在滴滴先后從事猜你想去、上下車點推薦、定位演算法等方向的開發作業,

2018年加入滴滴,主要從事網路定位、慣導推算等方向的演算法開發作業,

201#8年加入滴滴,主要從事網路定位、融合定位等方向的演算法開發作業,
團隊招聘
滴滴地圖與公交事業群定位團隊負責為滴滴平臺上的司乘雙方提供精準的定位服務,構建出行基礎設施,發揮平臺的大資料優勢,應用概率統計、機器學習、深度學習等技術,在GPS質量優化、網路定位、慣導推算、融合定位等細分方向上持續深耕,以技術驅動用戶體驗的提升,團隊長期招聘演算法工程師,包括機器學習、慣導推算等方向,歡迎有興趣的小伙伴加入,可投遞簡歷至 [email protected],郵件請郵件主題請命名為「姓名-應聘部門-應聘方向」,
延伸閱讀



內容編輯 | Charlotte&Teeo
聯系我們 | [email protected]

滴滴技術 出品
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/76046.html
標籤:大數據
上一篇:大資料作業