資料分組
目前為止的所有計算都是在表的所有資料或匹配特定的 WHERE 子句的
資料上進行的,提示一下,下面的例子回傳供應商 1003 提供的產品數目

但如果要回傳每個供應商提供的產品數目怎么辦?或者回傳只提供
單項產品的供應商所提供的產品,或回傳提供10個以上產品的供應商怎
么辦?
這就是分組顯身手的時候了,分組允許把資料分為多個邏輯組,以
便能對每個組進行聚集計算
創建分組
分組是在 SELECT 陳述句的 GROUP BY 子句中建立的,理解分組的最好辦
法是看一個例子

上面的 SELECT 陳述句指定了兩個列, vend_id 包含產品供應商的ID,
num_prods 為計算欄位(用 COUNT(*) 函式建立), GROUP BY 子句指
示MySQL按 vend_id 排序并分組資料,這導致對每個 vend_id 而不是整個表
計算 num_prods 一次,從輸出中可以看到,供應商 1001 有 3 個產品,供應商
1002 有 2 個產品,供應商 1003 有 7 個產品,而供應商 1005 有 2 個產品
因為使用了 GROUP BY ,就不必指定要計算和估值的每個組了,系統
會自動完成, GROUP BY 子句指示MySQL分組資料,然后對每個組而不是
整個結果集進行聚集
在具體使用 GROUP BY 子句前,需要知道一些重要的規定,
- GROUP BY 子句可以包含任意數目的列,這使得能對分組進行嵌套,
為資料分組提供更細致的控制, - 如果在 GROUP BY 子句中嵌套了分組,資料將在最后規定的分組上
進行匯總,換句話說,在建立分組時,指定的所有列都一起計算
(所以不能從個別的列取回資料), - GROUP BY 子句中列出的每個列都必須是檢索列或有效的運算式
(但不能是聚集函式),如果在 SELECT 中使用運算式,則必須在
GROUP BY 子句中指定相同的運算式,不能使用別名, - 除聚集計算陳述句外, SELECT 陳述句中的每個列都必須在 GROUP BY 子
句中給出, - 如果分組列中具有 NULL 值,則 NULL 將作為一個分組回傳,如果列
中有多行 NULL 值,它們將分為一組, - GROUP BY 子句必須出現在 WHERE 子句之后, ORDER BY 子句之前,
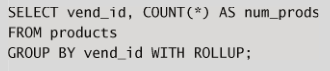
使用 ROLLUP 使用 WITH ROLLUP 關鍵字,可以得到每個分組以
及每個分組匯總級別(針對每個分組)的值,如下所示
過濾分組
除了能用 GROUP BY 分組資料外,MySQL還允許過濾分組,規定包括
哪些分組,排除哪些分組,例如,可能想要列出至少有兩個訂單的所有
顧客,為得出這種資料,必須基于完整的分組而不是個別的行進行過濾
HAVING 非常類似于 WHERE ,事實上,目前為止所
學過的所有型別的 WHERE 子句都可以用 HAVING 來替代,唯一的差別是
WHERE 過濾行,而 HAVING 過濾分組
HAVING 支持所有 WHERE 運算子 在第6章和第7章中,我們學習
了 WHERE 子句的條件(包括通配符條件和帶多個運算子的子
句),所學過的有關 WHERE 的所有這些技術和選項都適用于
HAVING ,它們的句法是相同的,只是關鍵字有差別

這條 SELECT 陳述句的前3行類似于上面的陳述句,最后一行增加了
HAVING 子句,它過濾 COUNT(*) >=2 (兩個以上的訂單)的那些
分組,
正如所見,這里 WHERE 子句不起作用,因為過濾是基于分組聚集值而
不是特定行值的
HAVING 和 WHERE 的差別 這里有另一種理解方法, WHERE 在資料
分組前進行過濾, HAVING 在資料分組后進行過濾,這是一個重
要的區別, WHERE 排除的行不包括在分組中,這可能會改變計
算值,從而影響 HAVING 子句中基于這些值過濾掉的分組
那么,有沒有在一條陳述句中同時使用 WHERE 和 HAVING 子句的需要呢?
事實上,確實有,假如想進一步過濾上面的陳述句,使它回傳過去12個月
內具有兩個以上訂單的顧客,為達到這一點,可增加一條 WHERE 子句,過
濾出過去12個月內下過的訂單,然后再增加 HAVING 子句過濾出具有兩個
以上訂單的分組
為更好地理解,請看下面的例子,它列出具有 2 個(含)以上、價格
為 10 (含)以上的產品的供應商

分組和排序
雖然 GROUP BY 和 ORDER BY 經常完成相同的作業,但它們是非常不同
的,表13-1匯總了它們之間的差別

表13-1中列出的第一項差別極為重要,我們經常發現用 GROUP BY 分
組的資料確實是以分組順序輸出的,但情況并不總是這樣,它并不是SQL
規范所要求的,此外,用戶也可能會要求以不同于分組的順序排序,僅
因為你以某種方式分組資料(獲得特定的分組聚集值),并不表示你需要
以相同的方式排序輸出,應該提供明確的 ORDER BY 子句,即使其效果等
同于 GROUP BY 子句也是如此
不要忘記 ORDER BY 一般在使用 GROUP BY 子句時,應該也給
出 ORDER BY 子句,這是保證資料正確排序的唯一方法,千萬
不要僅依賴 GROUP BY 排序資料
檢索總計訂單價格大于等于 50 的訂
單的訂單號和總計訂單價格

SELECT子句順序
下面回顧一下 SELECT 陳述句中子句的順序,表13-2以在 SELECT 陳述句中
使用時必須遵循的次序,列出迄今為止所學過的子句


我們學習了如何用SQL聚集函式對資料進行匯總計算,
本章講授了如何使用 GROUP BY 子句對資料組進行這些匯總計算,回傳每
個組的結果,我們看到了如何使用 HAVING 子句過濾特定的組,還知道了
ORDER BY 和 GROUP BY 之間以及 WHERE 和 HAVING 之間的差異,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/84263.html
標籤:MySQL
下一篇:MySQL必知必會--使用子查詢