
Netflix(Nasdaq NFLX),也就是網飛公司,成立于1997年,是一家在線影片[租賃]提供商,主要提供Netflix超大數量的[DVD]并免費遞送,總部位于美國加利福尼亞州洛斯蓋圖,1999年開始訂閱服務,2009年,該公司可提供多達10萬部DVD電影,并有1千萬的訂戶,2007年2月25日,Netflix宣布已經售出第10億份DVD,
Netflix已經連續五次被評為顧客最滿意的網站,可以通過PC、TV及iPad、iPhone收看電影、電視節目,可通過[Wii],[Xbox360],[PS3]等設備連接TV,Netflix是全球領先的經營在線業務公司,它成功地把傳統的影像租賃業務和現代化的市場營銷手段、先進的IT網路技術結合起來,從而開創了在線影像租賃的新局面,Netflix通過整合其自身的營銷手段和最近的IT網路技術,成功地改變了消費習慣和打造了自己的品牌優勢,
Netflix在2011年開始探索自制內容的舉動并不被看好,直到2013年,其首部自制劇《紙牌屋》取得爆紅后,輿論沖擊及股票下滑的趨勢才得以扭轉,這也讓Netflix成功打響了平臺自制內容的第一炮,

2019 年 7 月 4 日,網飛的原創劇《怪奇物語》第三季開播,一如往常地一口氣放出 12 集,再次掀起話題熱潮,取得這樣的成功,網飛自然是高興不已,7 月 8 日,這家通常并不愛自夸成績的公司表示,有近 4100 萬家庭在四天之內觀看了《怪奇物語》最新季,超過 1800 萬家庭已經把整 8 集全部刷完,如果需要對比資料的話,4 月份 HBO 發布的《權力的游戲》最終季首播集觀看人數為 1740 萬,

在持續推動創新技術更新的同時,Netflix確保始終如一的出色的用戶體驗絕非易事,如何才能確信更新系統的時候不會影響用戶的使用?而且實際上如何得到更多的反饋,可以對系統進行不斷地改進也是一個巨大的挑戰,
最終,Netflix公司通過對設備的資料進行采集,使用來自設備的實時日志作為事件源,得到了大量的資料,通過實時的大資料了解和量化了用戶設備,最終成功的近乎無縫地處理了視頻的瀏覽和回放,完美的解決了這些問題,
下面我們來具體了解一下:
系統架構
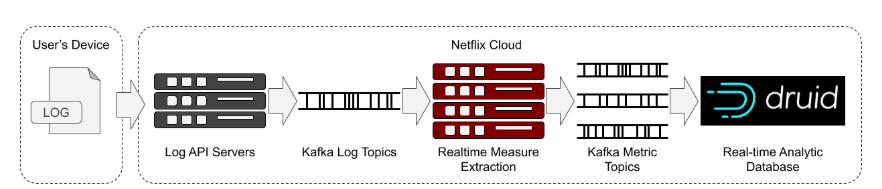
如上圖,整個系統架構通過對用戶設備日志收集,通過kafka的訊息傳遞,最終存盤在Druid中,
一旦有了這些資料,就將它們存入資料庫,這里使用的是實時分析資料庫Druid,
每項資料流均標有關于所用設備型別的匿名詳細資訊,例如,該設備是智能電視,iPad還是Android手機,這使得能夠根據各個方面對設備進行分類并查看資料,反過來,這又使我們能夠定向的分析僅影響特定人群的問題,例如應用程式的版本,特定型別的設備或特定國家/地區,
可通過儀表板或臨時查詢立即使用此聚合資料進行查詢,還可以連續檢查指標是否有警報信號,例如新版本是否正在影響某些用戶或設備的播放或瀏覽,這些檢查用于警告負責的團隊,他們可以盡快解決該問題,
在軟體更新期間,為部分用戶啟用新版本,并使用這些實時指標來比較新版本與以前版本的性能,指標中的任何問題都會使我們立刻發現并中止更新,并將那些使新版本直接恢復到先前版本,
由于每秒需要處理超過200萬個事件,因此將其放入可以快速查詢的資料庫是一個非常艱巨的任務,我們需要一個擁有足夠的性能與多維度查詢的資料庫,來處理每天產生超過1,150億行的資料,在Netflix,最終選擇利用Apache Druid來應對這一挑戰,
Druid(德魯伊)

Druid是一個分布式的支持實時分析的資料存盤系統,通俗一點:高性能實時分析資料庫,
Apache Druid是一個高性能的實時分析資料庫,它是為需要快速查詢和提取的作業流而設計的,德魯伊在即時資料可視性,即席查詢,運營分析和處理高并發方面表現出色,” — druid.io
因此,Druid非常適合現在我們面臨的這種用例,事件資料的攝取頻率非常高,具有大資料量和快速查詢要求,
Druid不是關系資料庫,但是某些概念是可移植的,我們有資料源,而不是表,與關系資料庫一樣,這些是表示為列的資料的邏輯分組,Druid的Join性能目前還不是很優秀,因此,我們需要確保每個資料源中都包含我們要過濾或分組依據的任何列,
資料源中主要有三類列-時間,維度和指標,
德魯伊中的一切都取決于時間,每個資料源都有一個timestamp列,它是主要的磁區機制,維度是可用于過濾,查詢或分組依據的值,指標是可以匯總的值,幾乎總是數字,
我們假設資料由時間戳作為鍵,Druid可以對存盤,分配和查詢資料的方式進行一些優化,從而使我們能夠將資料源擴展到數萬億行,并且仍然可以實作查詢回應時間在十毫秒內,
為了達到這種級別的可伸縮性,Druid將存盤的資料劃分為多個時間塊,時間塊的持續時間是可配置的,可以根據您的資料和用例選擇適當的持續時間,對于我們的資料和用例,我們使用1小時時間塊,時間塊內的資料存盤在一個或多個段中,每個段都保存有所有資料行,這些行均落在其時間戳鍵列所確定的時間塊內,可以配置段的大小,以使行數或段檔案的總大小有上限,
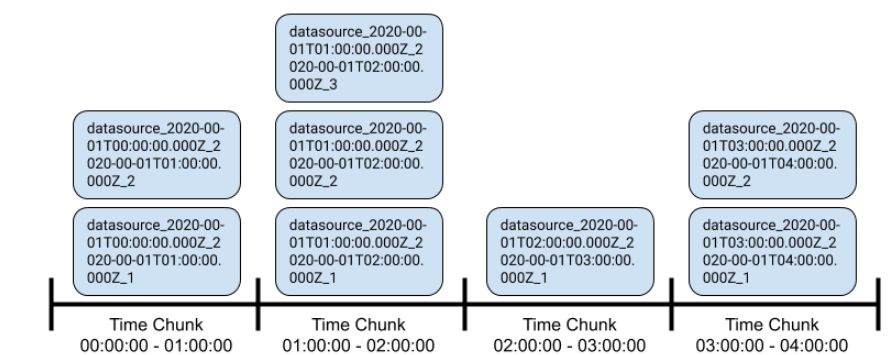
查詢資料時,Druid將查詢發送到集群中所有包含查詢范圍內時間塊的分段的節點,每個節點在將中間結果發送回查詢代理節點之前,都會對所保存的資料進行并行處理,代理將執行最終合并和聚合,然后再將結果集發送回客戶端,
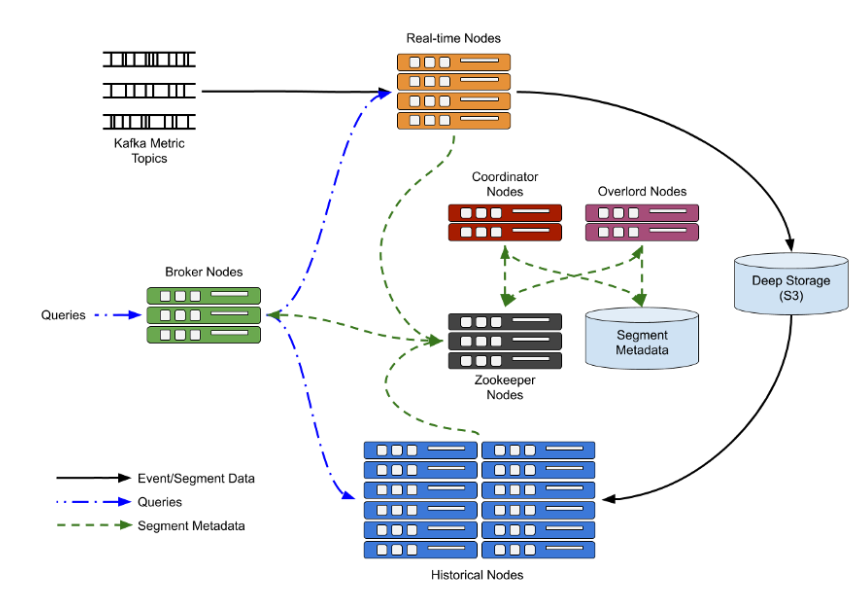
攝取資料
把資料實時插入到此資料庫,這些事件(在本例中為指標)不是從單個記錄插入到資料源中,而是從Kafka流中讀取,每個資料源使用1個主題,在Druid中,我們使用Kafka索引編制任務,該任務創建了多個在實時節點中間管理者之間分布的索引編制作業器,
這些索引器中的每一個都訂閱該主題,并從流中讀取其事件共享,索引器根據攝入規范從事件訊息中提取值,并將創建的行累積在記憶體中,一旦創建了行,就可以對其進行查詢,到達索引器仍在填充一個段的時間塊的查詢將由索引器本身提供,由于索引編制任務實際上執行兩項作業,即攝取和現場查詢,因此及時將資料發送到“歷史節點”以更優化的方式將查詢作業分擔給歷史節點非常重要,
Druid可以在提取資料時對其進行匯總,以最大程度地減少需要存盤的原始資料量,匯總是一種匯總或預聚合的形式,在某些情況下,匯總資料可以極大地減少需要存盤的資料大小,從而有可能將行數減少幾個數量級,但是,減少存盤量確實要付出一定的代價:我們失去了查詢單個事件的能力,只能以預定義的查詢粒度進行查詢,對于我們的用例,我們選擇了1分鐘的查詢粒度,
在提取期間,如果任何行具有相同的維度,并且它們的時間戳在同一分鐘內(我們的查詢粒度),則這些行將被匯總,這意味著通過將所有度量值加在一起并增加一個計數器來合并行,因此我們知道有多少事件促成了該行的值,這種匯總形式可以顯著減少資料庫中的行數,從而加快查詢速度,因為這樣我們就可以減少要操作和聚合的行,
一旦累積的行數達到某個閾值,或者該段已打開太長時間,則將這些行寫入段檔案中并卸載到深度存盤中,然后,索引器通知協調器段已準備好,以便協調器可以告訴一個或多個歷史節點加載該段,一旦將段成功加載到“歷史”節點中,就可以從索引器中將其卸載,并且歷史記錄節點現在將為所有針對該資料的查詢提供服務,
資料管理
就像您想象的那樣,隨著維數基數的增加,在同一分鐘內發生相同事件的可能性降低,管理基數以及因此匯總,是獲得良好查詢性能的有力手段,
為了達到所需的攝取速率,我們運行了許多索引器實體,即使在索引任務中合并了相同行的匯總,在相同的索引任務實體中獲得所有相同行的機會也非常低,為了解決這個問題并實作最佳的匯總,我們安排了一個任務,在將給定時間塊的所有段都移交給歷史節點之后運行,
計劃的壓縮任務從深度存盤中獲取所有分段以進行時間塊化,并執行映射/縮小作業以重新創建分段并實作完美的匯總,然后,由“歷史記錄”節點加載并發布新的細分,以替換并取代原始的,較少匯總的細分,在我們的案例中,通過使用此額外的壓縮任務,我們發現行數提高了2倍,
知道何時收到給定時間塊的所有事件并不是一件容易的事,可能有關于Kafka主題的遲到資料,或者索引器可能會花一些時間將這些片段移交給“歷史”節點,為了解決此問題,我們在運行壓縮之前強加了一些限制并執行檢查,
首先,我們丟棄任何非常遲到的資料,我們認為這太舊了,無法在我們的實時系統中使用,這樣就可以確定資料的延遲時間,其次,壓縮任務是有延遲地安排的,這給了段足夠的時間以正常流程分流到歷史節點,最后,當給定時間塊的計劃壓縮任務開始時,它查詢段元資料以檢查是否還有任何相關段仍在寫入或移交,如果有,它將等待幾分鐘后重試,這樣可以確保所有資料都由壓縮作業處理,
如果沒有這些措施,我們發現有時會丟失資料,開始壓縮時仍要寫入的段將被具有更高版本的新壓縮的段覆寫,因此具有優先權,這有效地洗掉了尚未完成移交的那些段中包含的資料,
查詢方式
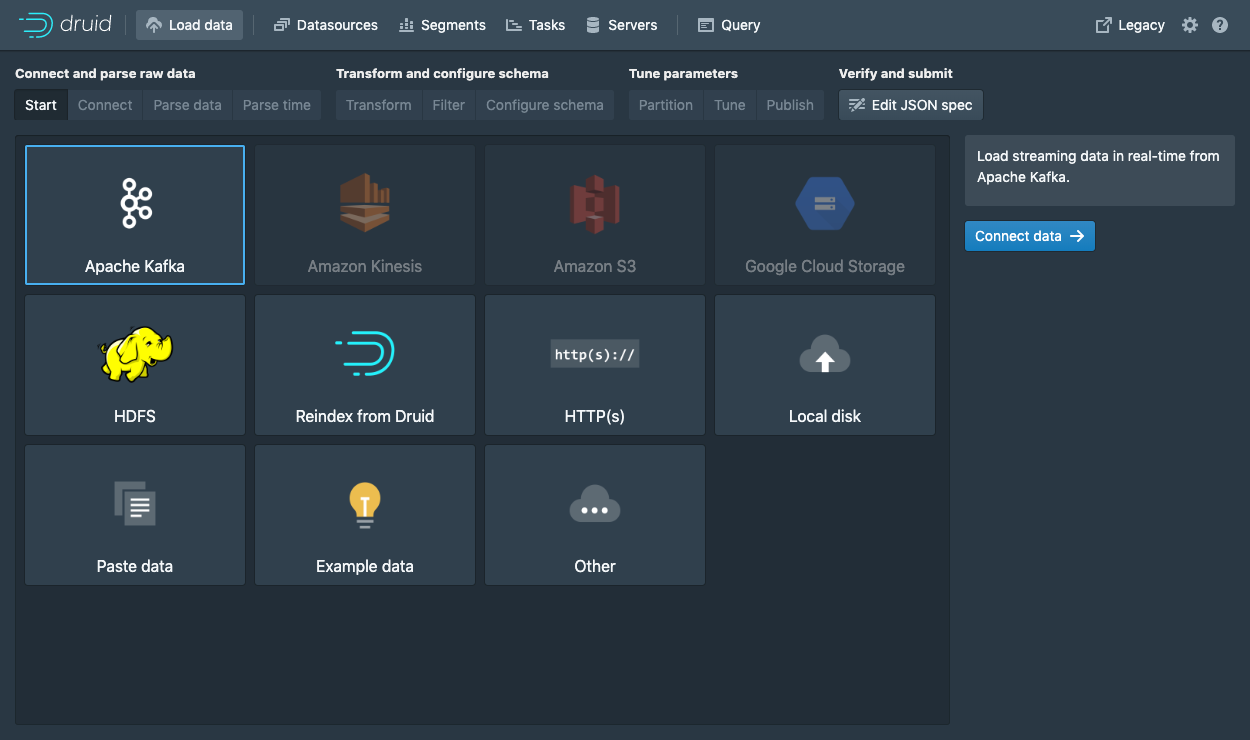
Druid支持兩種查詢語言:Druid SQL和原生查詢,在后臺,Druid SQL查詢被轉換為本地查詢,原生查詢作為JSON提交到REST端點,這是我們使用的主要機制,
對集群的大多數查詢都是由自定義內部工具(例如儀表板和警報系統)生成的,這些系統最初旨在與我們內部開發的開源時間序列資料庫Atlas一起使用,因此,這些工具使用Atlas Stack查詢語言,
為了加快采用Druid查詢的速度并實作對現有工具的重用,我們添加了一個轉換層,該層接受Atlas查詢,將其重寫為Druid查詢,發布查詢并將結果重新格式化為Atlas結果,這個抽象層使現有工具可以按原樣使用,并且不會為用戶訪問我們的Druid資料存盤中的資料創建任何額外的學習曲線,
調整
在調整群集節點的配置時,我們以很高的速度運行了一系列可重復和可預測的查詢,以便獲得每個給定配置的回應時間和查詢吞吐量的基準,這些查詢旨在隔離集群的各個部分,以檢查查詢性能是否有所改善或降低,
例如,我們針對最新資料運行了有針對性的查詢,同樣,對于更長的持續時間,但只有較舊的資料可以確保我們僅查詢“歷史”節點以測驗快取配置,再次使用按非常高的基數維度分組的查詢,以檢查結果合并是如何受到影響的,我們繼續調整并運行這些基準測驗,直到對查詢性能感到滿意為止,
在這些測驗中,我們發現調整緩沖區的大小,執行緒數,查詢佇列長度和分配給查詢快取的記憶體對查詢性能產生了有效影響,但是,引入壓縮作業將占用我們匯總不良的細分,并以完美匯總將它們重新壓縮,這對查詢性能產生了更大的影響,
我們還發現,在歷史節點上啟用快取非常有好處,而在代理節點上啟用快取則沒有那么多,太多了,我們不使用代理上的快取,這可能是由于我們的用例所致,但是我們幾乎進行的每個查詢都未命中代理上的快取,這可能是因為查詢通常包含最新資料,因為這些資料始侄訓到達,因此不會包含在任何快取中,
摘要
經過多次迭代,針對我們的用例和資料速率進行了調整和定制,德魯伊已被證明具有我們最初希望的能力,
我們已經能夠使用功能強大且可用的系統,但是還有更多作業要做,我們的攝入量和攝入率不斷提高,查詢的數量和復雜性也在不斷增加,隨著更多團隊實作這些詳細資料的價值,我們經常添加更多指標和維度,從而推動系統更加努力地作業,我們必須繼續監視和調整,以保持查詢性能,
目前,我們每秒接收超過200萬個事件,并查詢超過1.5萬億行,以深入了解我們的用戶如何體驗該服務,所有這些都有助于我們保持高質量的Netflix體驗,同時實作不斷的創新,
實時流式計算與流媒體的碰撞才剛剛開始,而Druid作為一款極易上手的高性能實時查詢資料庫,也會得到越來越多的廣泛使用,
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算”
獲取《Druid實時大資料分析》電子書,請在公號后臺回復 “Druid”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/8611.html
標籤:大數據