
KafkaCenter是什么
KafkaCenter是一個針對Kafka的一站式,解決方案,用于Kafka集群的維護與管理,生產者和消費者的監控,以及Kafka部分生態組件的使用,
對于Kafka的平臺化,一直缺少一個成熟的解決方案,之前比較流行的kafka監控方案,如kafka-manager提供了集群管理與topic管理等等功能,但是對于生產者、消費者的監控,以及Kafka的新生態,如Connect,KSQL還缺少回應的支持,Confluent Control Center功能要完整一些,但卻是非開源收費的,
對于Kafka的使用,一直都是一個讓人頭疼的問題,由于實時系統的強運維特性,我們不得不投入大量的時間用于集群的維護,kafka的運維,比如:
- 人工創建topic,特別費力
- 相關kafka運維,監控孤島化
- 現有消費監控工具監控不準確
- 無法拿到Kafka 集群的summay資訊
- 無法快速知曉集群健康狀態
- 無法知曉業務對team kafka使用情況
- kafka管理,監控工具稀少,沒有一個好的工具我們直接可以使用
- 無法快速查詢topic訊息
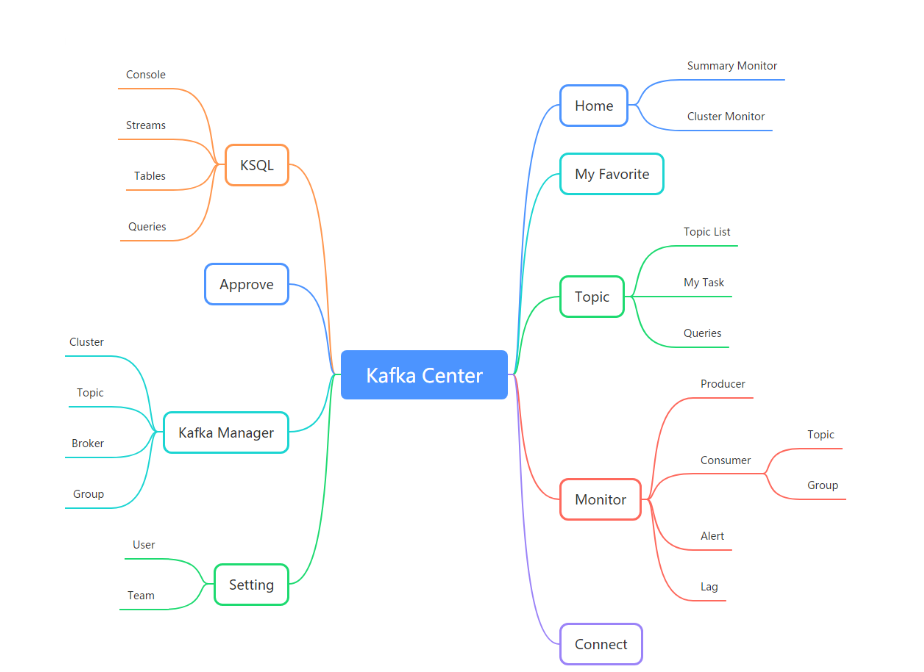
功能模塊介紹
- Home-> 查看平臺管理的Kafka Cluster集群資訊及監控資訊
- Topic-> 用戶可以在此模塊查看自己的Topic,發起申請新建Topic,同時可以對Topic進行生產消費測驗,
- Monitor-> 用戶可以在此模塊中可以查看Topic的生產以及消費情況,同時可以針對消費延遲情況設定預警資訊,
- Connect-> 實作用戶快速創建自己的Connect Job,并對自己的Connect進行維護,
- KSQL-> 實作用戶快速創建自己的KSQL Job,并對自己的Job進行維護,
- Approve-> 此模塊主要用于當普通用戶申請創建Topic,管理員進行審批操作,
- Setting-> 此模塊主要功能為管理員維護User、Team以及kafka cluster資訊
- Kafka Manager-> 此模塊用于管理員對集群的正常維護操作,
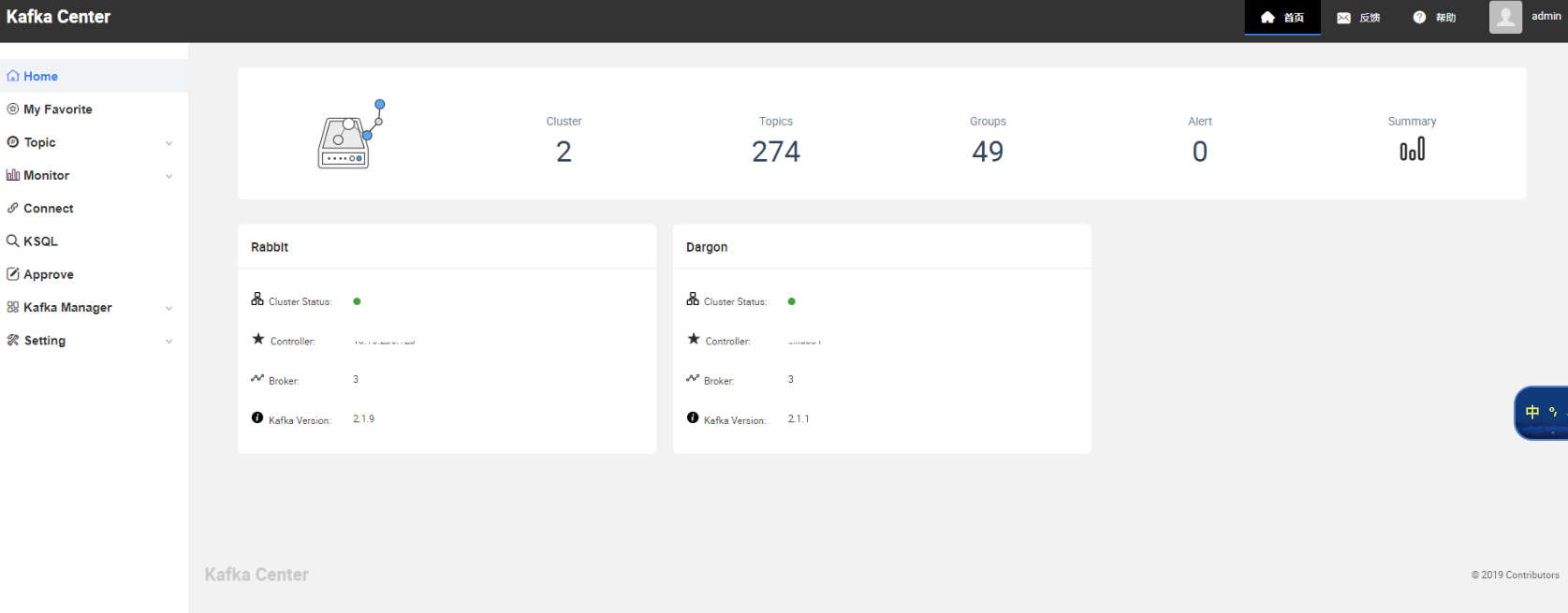
系統截圖:
安裝與入門
安裝需要依賴 mysql es email server
| 組件 | 是否必須 | 功能 |
|---|---|---|
| mysql | 必須 | 配置資訊存在mysql |
| elasticsearch(7.0+) | 可選 | 各種監控資訊的存盤 |
| email server | 可選 | Apply, approval, warning e-mail alert |
1、初始化
在MySQL中執行sql建表
-- Dumping database structure for kafka_center
CREATE DATABASE IF NOT EXISTS `kafka_center` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
USE `kafka_center`;
-- Dumping structure for table kafka_center.alert_group
CREATE TABLE IF NOT EXISTS `alert_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cluster_id` int(11) NOT NULL,
`topic_name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`consummer_group` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`consummer_api` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`threshold` int(11) DEFAULT NULL,
`dispause` int(11) DEFAULT NULL,
`mail_to` varchar(1000) COLLATE utf8_bin NOT NULL DEFAULT '',
`webhook` varchar(1000) COLLATE utf8_bin NOT NULL DEFAULT '',
`create_date` datetime DEFAULT NULL,
`owner_id` int(11) DEFAULT NULL,
`team_id` int(11) DEFAULT NULL,
`disable_alerta` tinyint(1) DEFAULT 0,
`enable` tinyint(1) NOT NULL DEFAULT 1,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.cluster_info
CREATE TABLE IF NOT EXISTS `cluster_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_bin NOT NULL,
`zk_address` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`broker` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`create_time` datetime DEFAULT NULL,
`comments` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`enable` int(11) DEFAULT NULL,
`broker_size` int(4) DEFAULT 0,
`kafka_version` varchar(10) COLLATE utf8_bin DEFAULT '',
`location` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`graf_addr` varchar(255) COLLATE utf8_bin DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.ksql_info
CREATE TABLE IF NOT EXISTS `ksql_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cluster_id` int(11) DEFAULT NULL,
`cluster_name` varchar(255) DEFAULT NULL,
`ksql_url` varchar(255) DEFAULT NULL,
`ksql_serverId` varchar(255) DEFAULT NULL,
`version` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.task_info
CREATE TABLE IF NOT EXISTS `task_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cluster_ids` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`location` varchar(20) COLLATE utf8_bin NOT NULL DEFAULT '',
`topic_name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`partition` int(11) DEFAULT NULL,
`replication` int(11) DEFAULT NULL,
`message_rate` int(50) DEFAULT NULL,
`ttl` int(11) DEFAULT NULL,
`owner_id` int(11) DEFAULT NULL,
`team_id` int(11) DEFAULT NULL,
`comments` varchar(1000) COLLATE utf8_bin NOT NULL DEFAULT '',
`create_time` datetime DEFAULT NULL,
`approved` int(11) DEFAULT NULL,
`approved_id` int(11) DEFAULT NULL,
`approved_time` datetime DEFAULT NULL,
`approval_opinions` varchar(1000) COLLATE utf8_bin DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.team_info
CREATE TABLE IF NOT EXISTS `team_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`own` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.topic_collection
CREATE TABLE IF NOT EXISTS `topic_collection` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`cluster_id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`type` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.topic_info
CREATE TABLE IF NOT EXISTS `topic_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cluster_id` int(11) NOT NULL,
`topic_name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`partition` int(11) DEFAULT NULL,
`replication` int(11) DEFAULT NULL,
`ttl` bigint(11) DEFAULT NULL,
`config` varchar(512) COLLATE utf8_bin DEFAULT NULL,
`owner_id` int(11) DEFAULT NULL,
`team_id` int(11) DEFAULT NULL,
`comments` varchar(1000) COLLATE utf8_bin NOT NULL DEFAULT '',
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.user_info
CREATE TABLE IF NOT EXISTS `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`real_name` varchar(255) COLLATE utf8_bin DEFAULT '',
`email` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`role` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '100',
`create_time` datetime DEFAULT NULL,
`password` varchar(255) COLLATE utf8_bin DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- Data exporting was unselected.
-- Dumping structure for table kafka_center.user_team
CREATE TABLE IF NOT EXISTS `user_team` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`team_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
2、配置
相關配置位于application.properties
可對埠 日志等資訊做一些修改
server.port=8080
debug=false
# 設定session timeout為6小時
server.servlet.session.timeout=21600
spring.security.user.name=admin
spring.security.user.password=admin
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/kafka_center?useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.maximum-pool-size=15
spring.datasource.hikari.pool-name=KafkaCenterHikariCP
spring.datasource.hikari.max-lifetime =30000
spring.datasource.hikari.connection-test-query=SELECT 1
management.health.defaults.enabled=false
public.url=http://localhost:8080
connect.url=http://localhost:8000/#/
system.topic.ttl.h=16
monitor.enable=true
monitor.collect.period.minutes=5
monitor.elasticsearch.hosts=localhost:9200
monitor.elasticsearch.index=kafka_center_monitor
#是否啟用收集執行緒指定集群收集
monitor.collector.include.enable=false
#收集執行緒指定location,必須屬于remote.locations之中
monitor.collector.include.location=dev
collect.topic.enable=true
collect.topic.period.minutes=10
# remote的功能是為了提高lag查詢和收集,解決跨location網路延遲問題
remote.query.enable=false
remote.hosts=gqc@localhost2:8080
remote.locations=dev,gqc
#發送consumer group的lag發送給alert service
alert.enable=false
alert.dispause=2
alert.service=
alert.threshold=1000
alter.env=other
#是否開啟郵件功能,true:啟用,false:禁用
mail.enable=false
spring.mail.host=
[email protected]
# oauth2
generic.enabled=false
generic.name=oauth2 Login
generic.auth_url=
generic.token_url=
generic.redirect_utl=
generic.api_url=
generic.client_id=
generic.client_secret=
generic.scopes=
3、運行
推薦使用docker
docker run -d -p 8080:8080 --name KafkaCenter -v ${PWD}/application.properties:/opt/app/kafka-center/config/application.properties xaecbd/kafka-center:2.1.0
不用docker
$ git clone https://github.com/xaecbd/KafkaCenter.git
$ cd KafkaCenter
$ mvn clean package -Dmaven.test.skip=true
$ cd KafkaCenter\KafkaCenter-Core\target
$ java -jar KafkaCenter-Core-2.1.0-SNAPSHOT.jar
4、查看
訪問http://localhost:8080 管理員用戶與密碼默認:admin / admin
功能介紹
Topics
用戶可以在此模塊完成Topic查看,已經申請新建Topic,同時可以對Topic進行生產消費測驗,
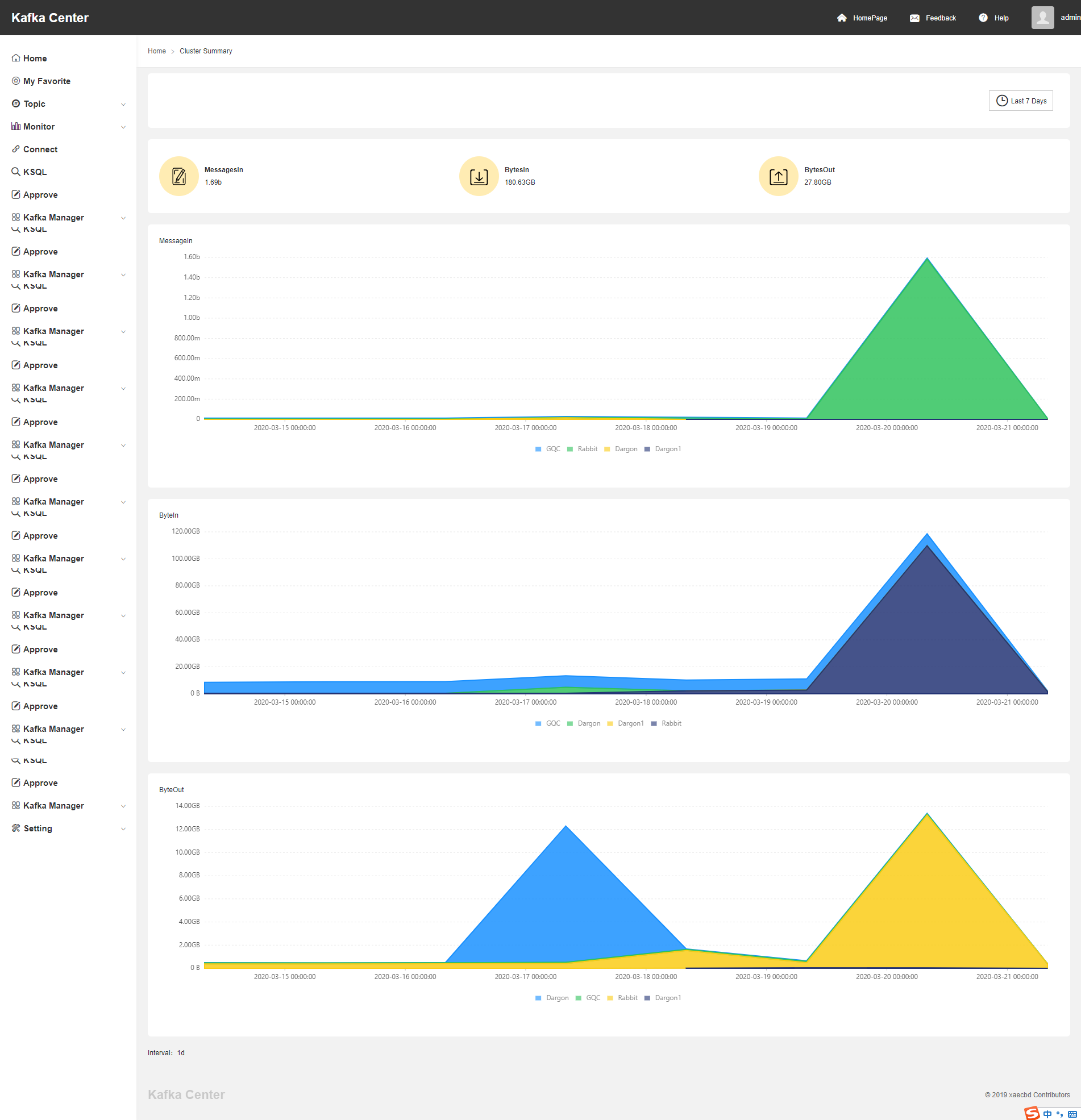
Monitor
用戶可以在此模塊中可以查看Topic的生成以及消費情況,同時可以針對消費延遲情況設定預警資訊,
Alerts
此模塊用于維護預警資訊,用戶可以看到自己所有預警資訊,管理員可以看到所有人的預警資訊,
Kafka Connect
實作用戶快速創建自己的Connect Job,并對自己的Connect進行維護,
KSQL
實作用戶快速創建自己的KSQL Job,并對自己的Job進行維護,
Approve
此模塊主要用于當普通用戶申請創建Topic 或者Job時,管理員進行審批操作,
Setting
此模塊主要功能為管理員維護User、Team以及kafka cluster資訊
Cluster Manager
此模塊用于管理員對集群的正常維護操作,
Home
這里是一些基本的統計資訊
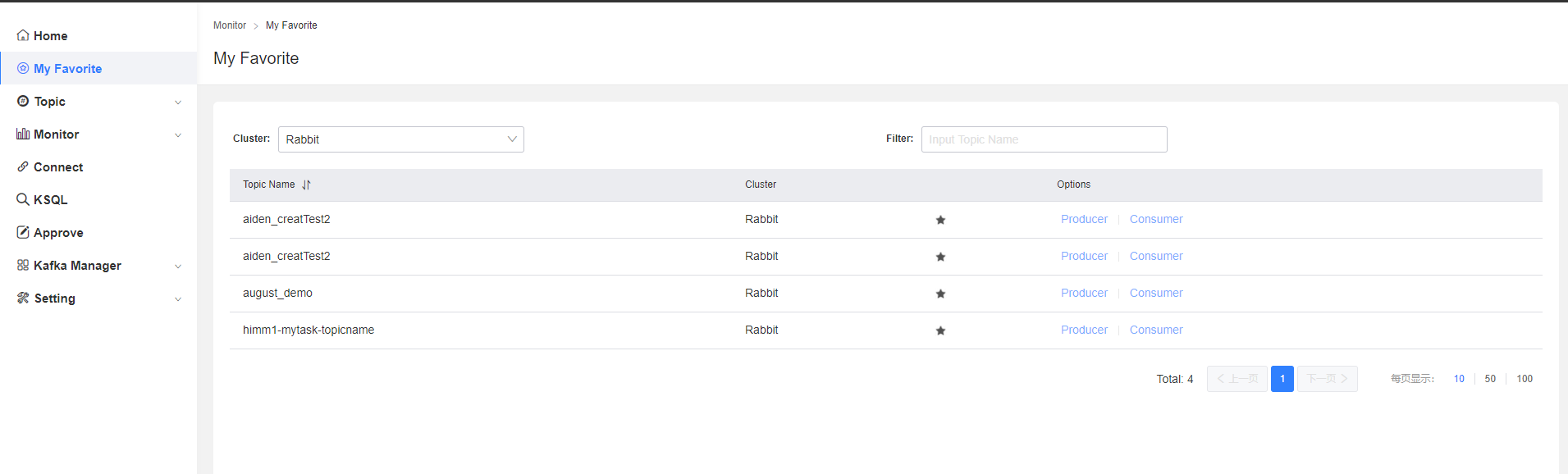
My Favorite
集群與topic串列
Topic
這里是一些topic的管理功能
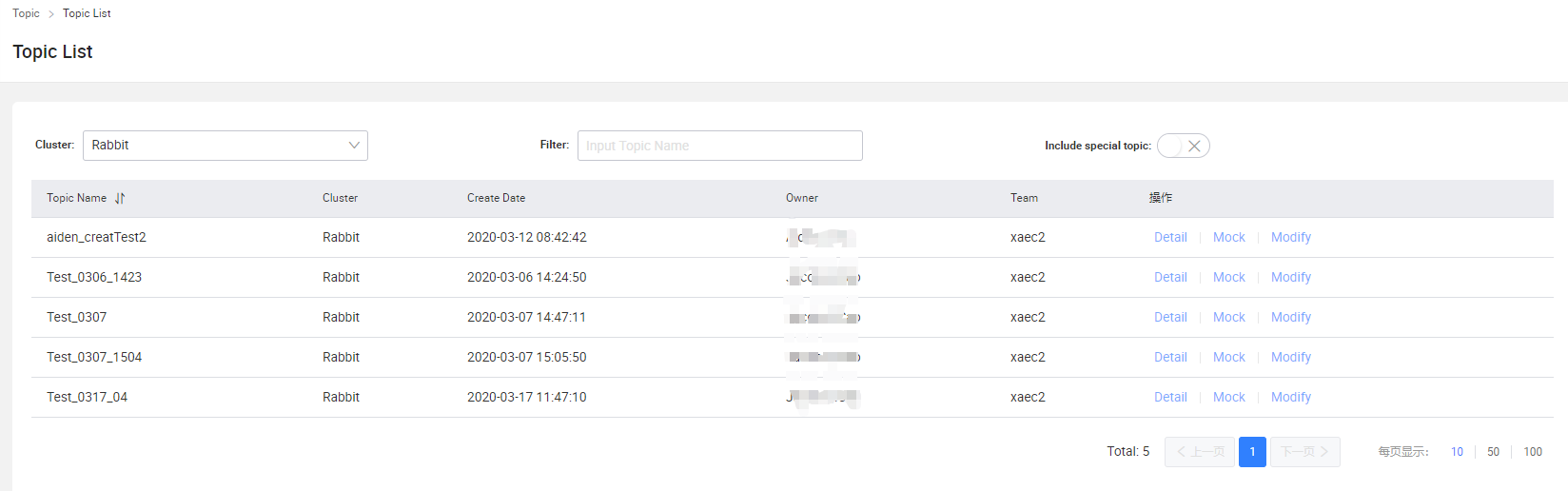
Topic List
操作范圍:
用戶所屬Team的所有Topic
- Topic -> Topic List -> Detail 查看Topic的詳細資訊
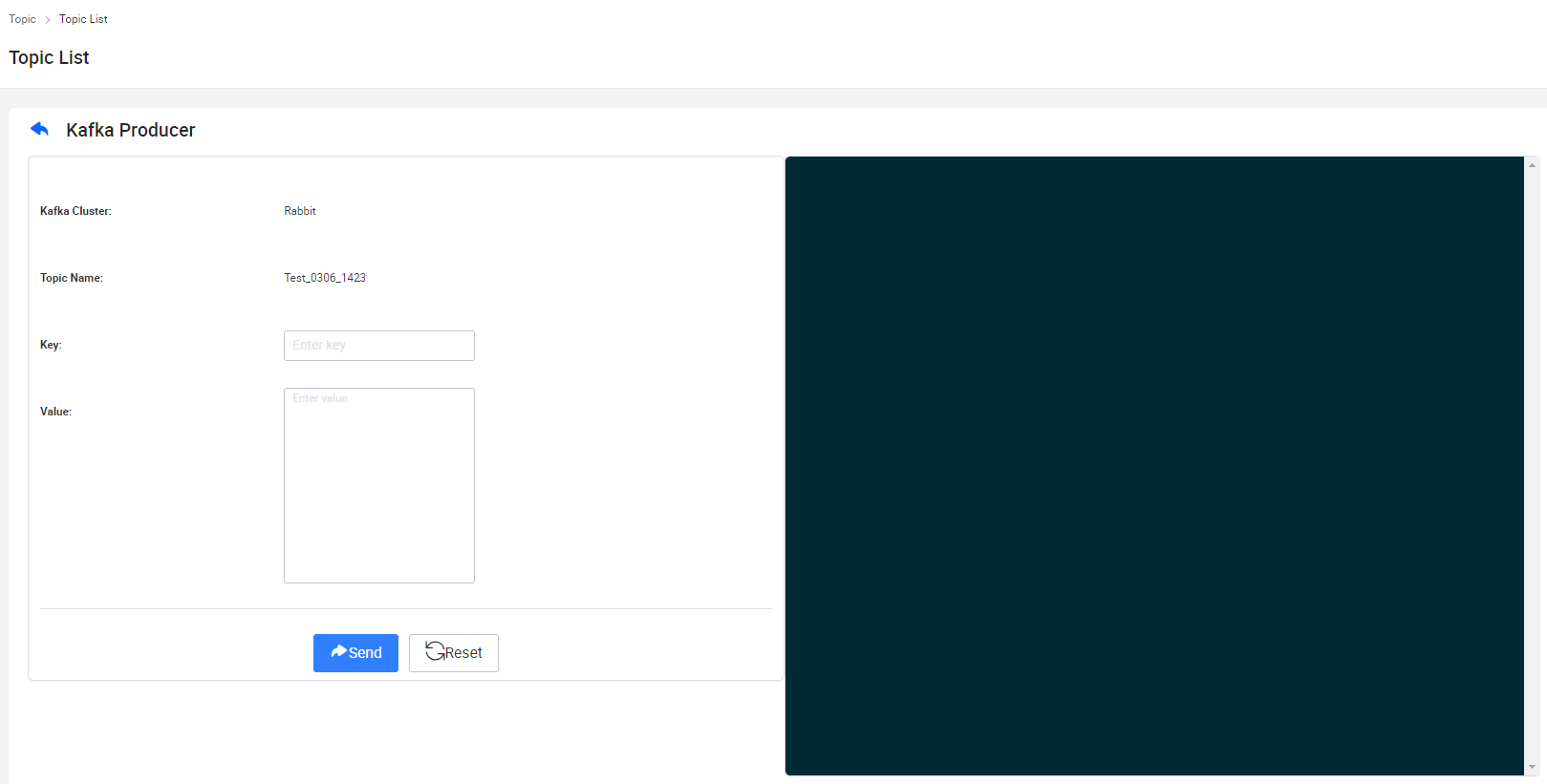
- Topic -> Topic List -> Mock 對Topic進行生產測驗
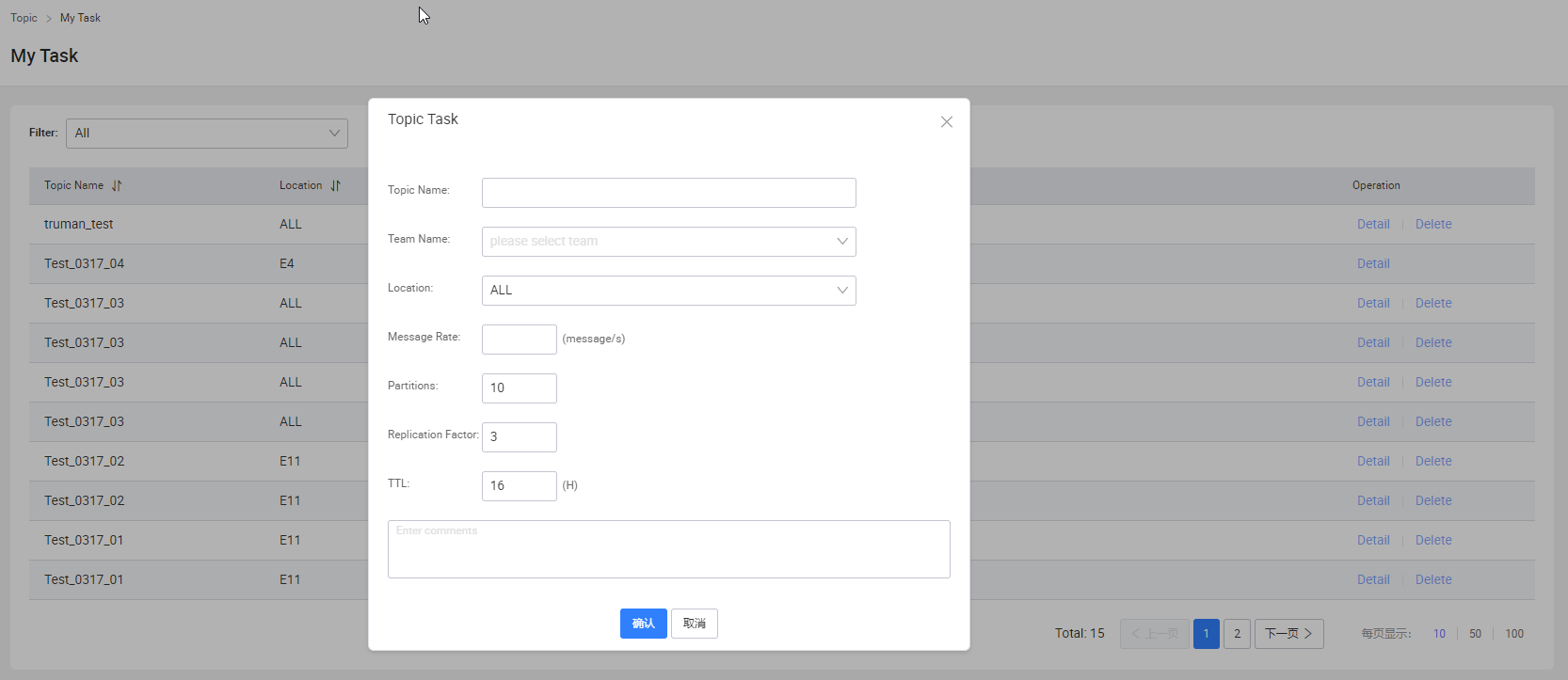
申請創建topic
Important: admin不能申請task,普通用戶必須先讓管理員新建team后,將用戶加入指定team后,才可以申請task,
操作范圍:
用戶所屬Team的所有Task
-
Topic -> My Task -> Detail 查看申請的Task資訊
-
Topic -> My Task -> Delete 洗掉被拒絕或待審批的Task
-
Topic -> My Task -> Edit 修改被拒絕的Task
-
Topic -> My Task -> Create Topic Task 創建Task
- 按照表單各欄位要求填寫資訊
- 點擊確認,提交申請
審批結果:
- 審批通過:Topic將會被創建在管理員指定的集群
- 審批拒絕:用戶收到郵件,回傳到My Task,點擊對應Task后面的Edit,針對審批意見進行修改
Topic命名規則:
只能包含:數字、大小寫字母、下劃線、中劃線、點;長度大于等于3小于等于100,
不推薦:下劃線開頭;
可對所有Topic進行消費測驗
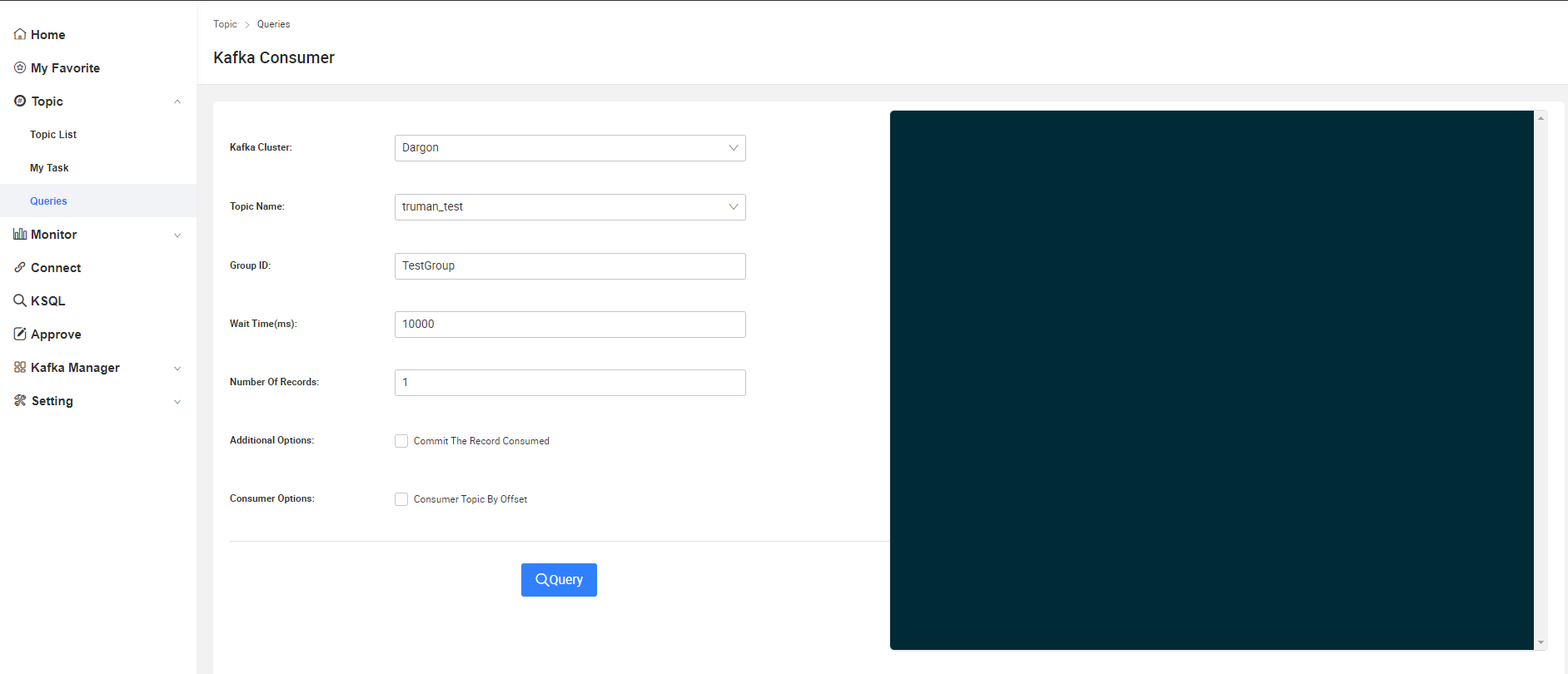
Monitor
監控模塊
生產者監控
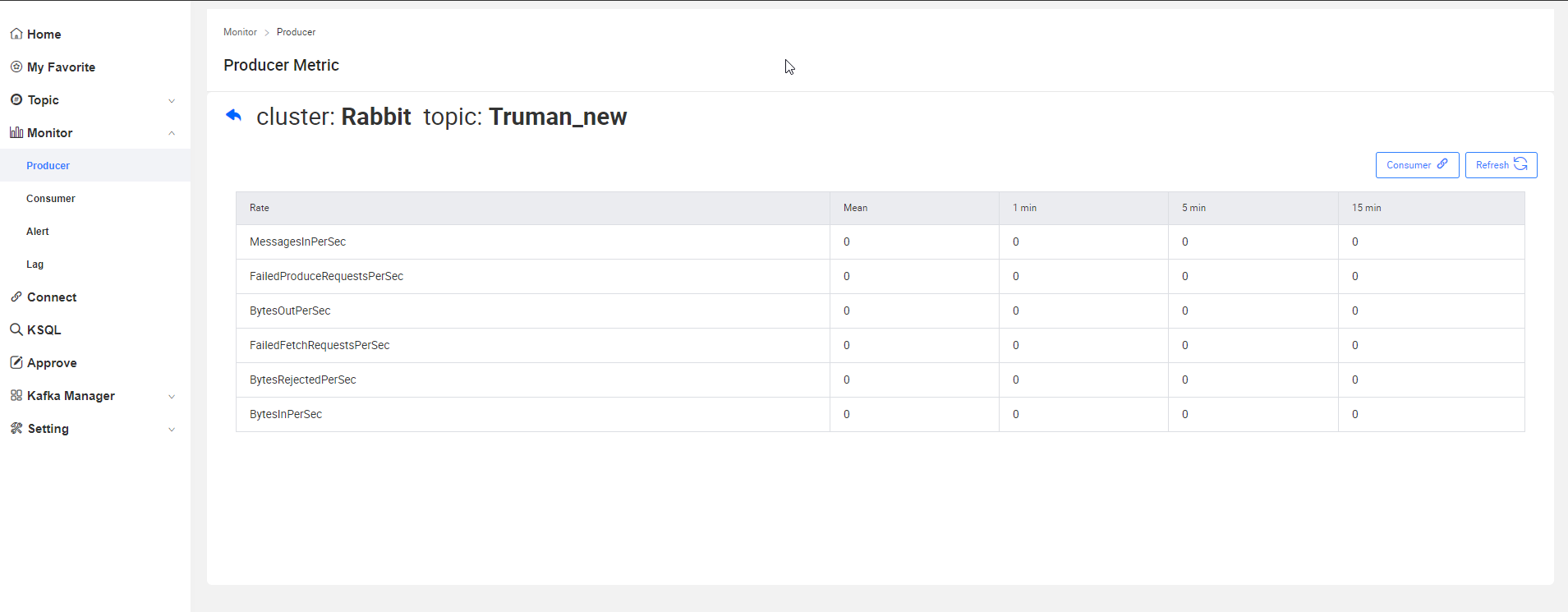
消費者監控
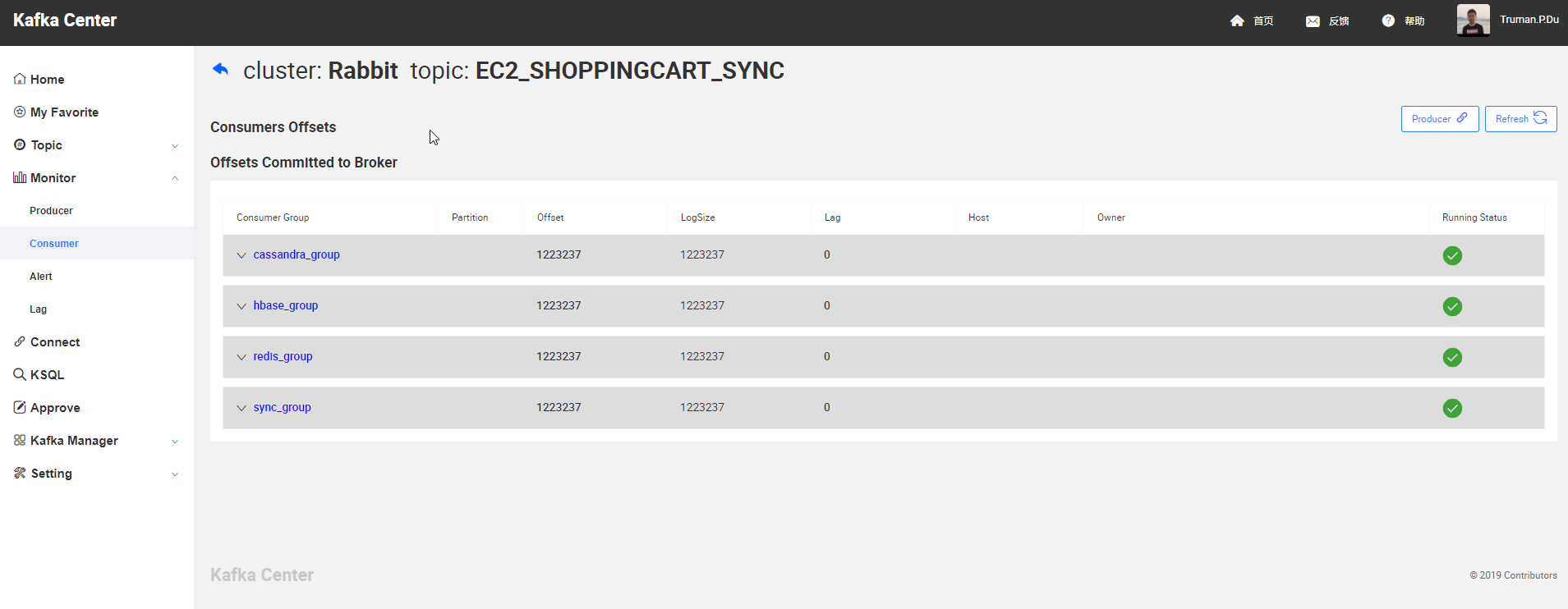
訊息積壓
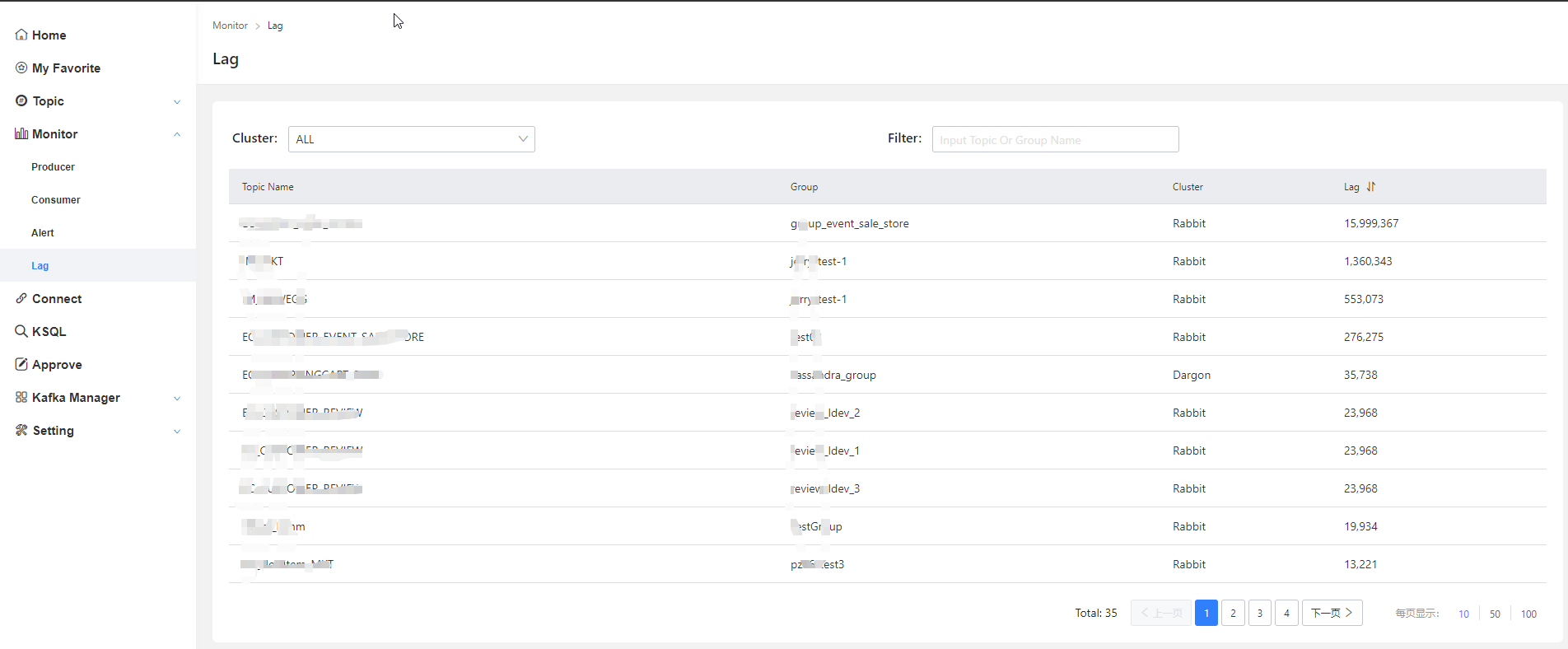
報警功能
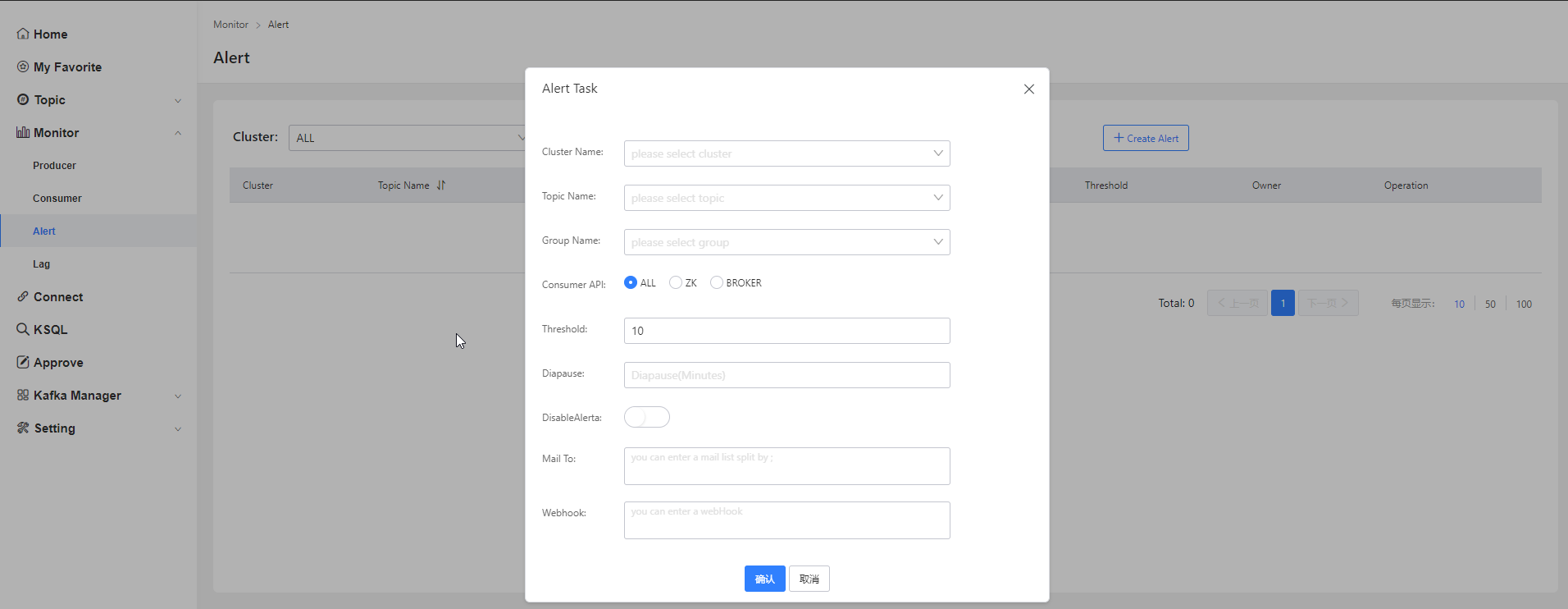
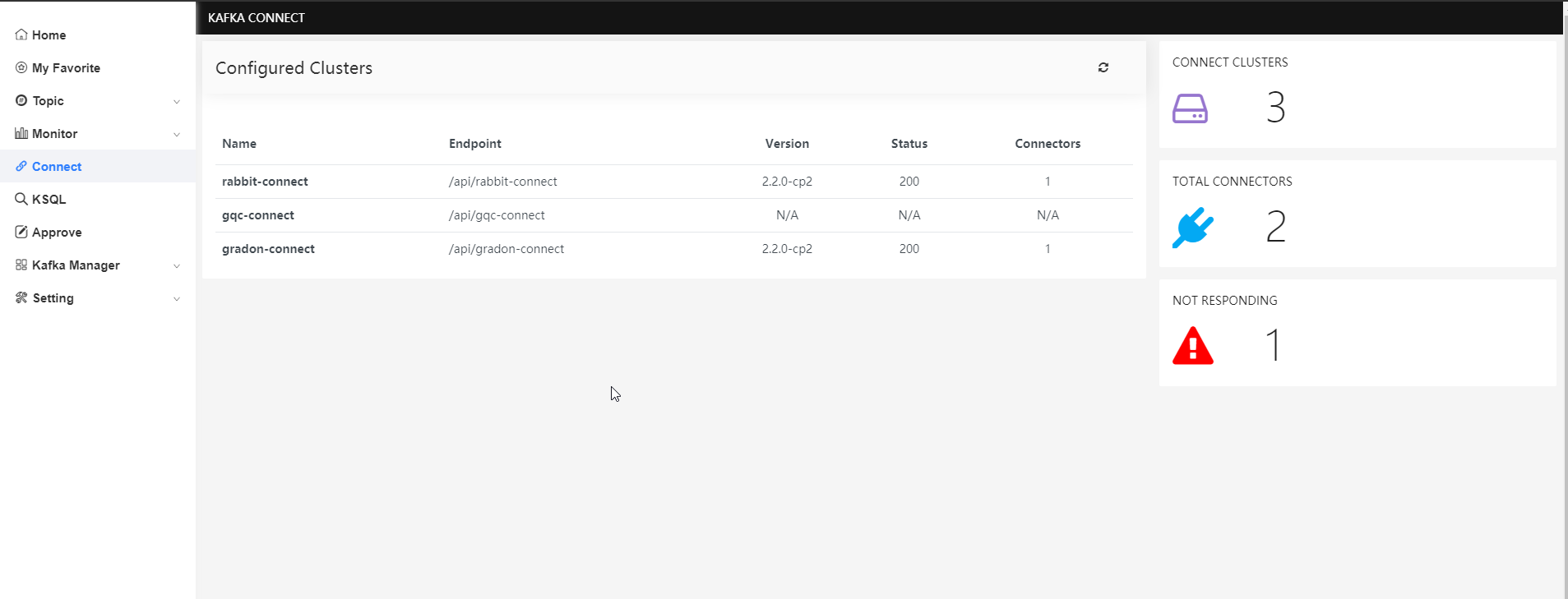
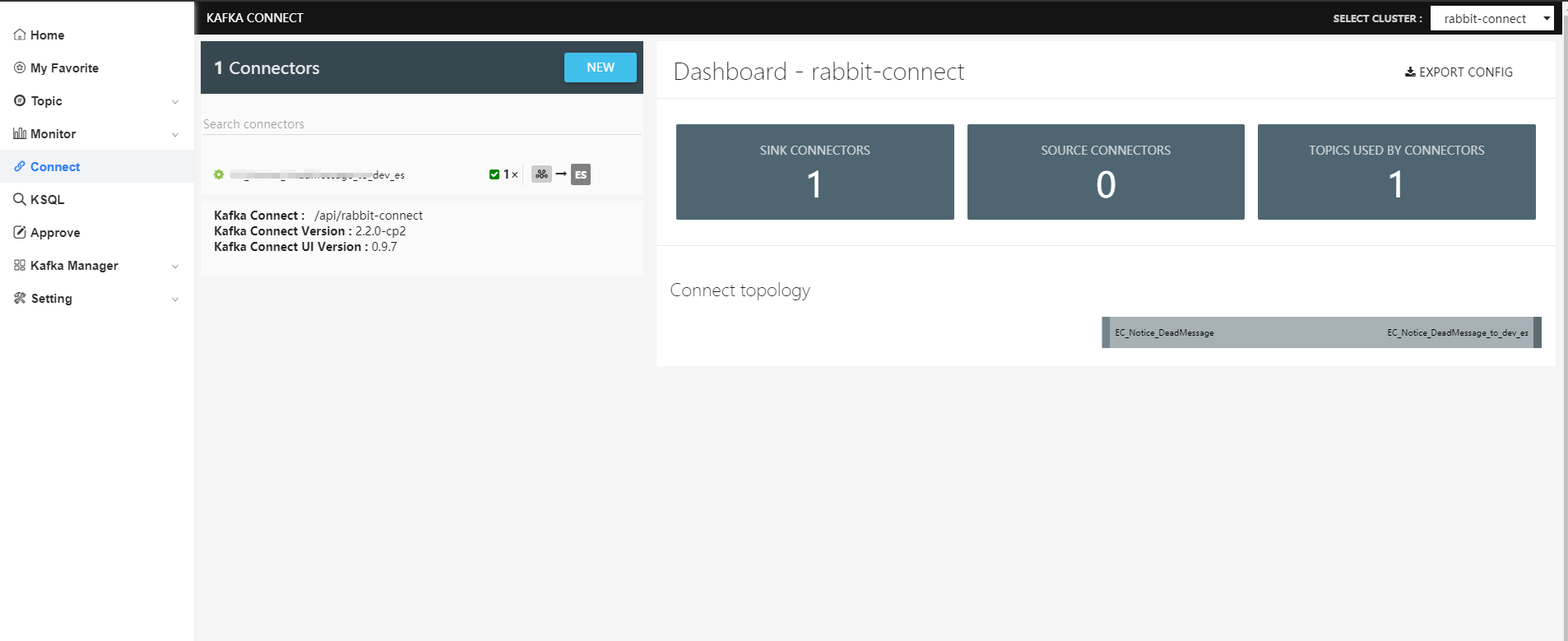
Connect
這里是一些Connect的操作
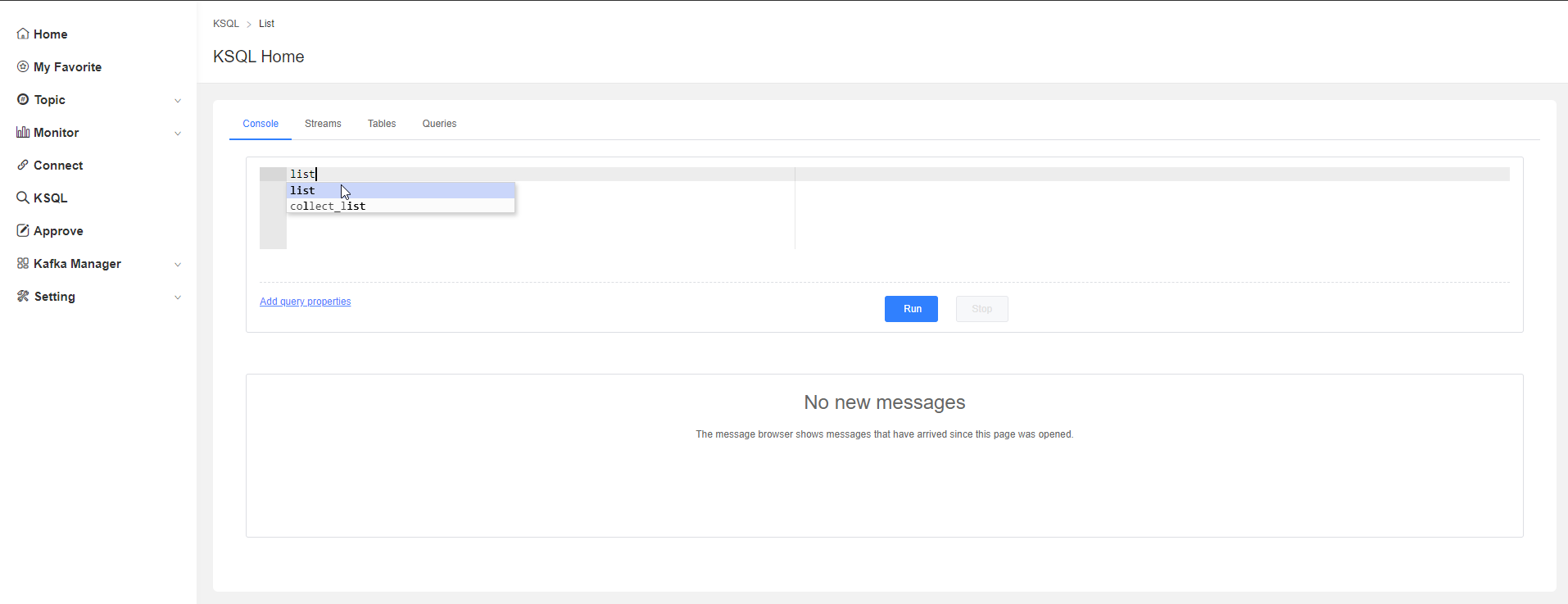
KSQL
可以進行KQL的查詢操作
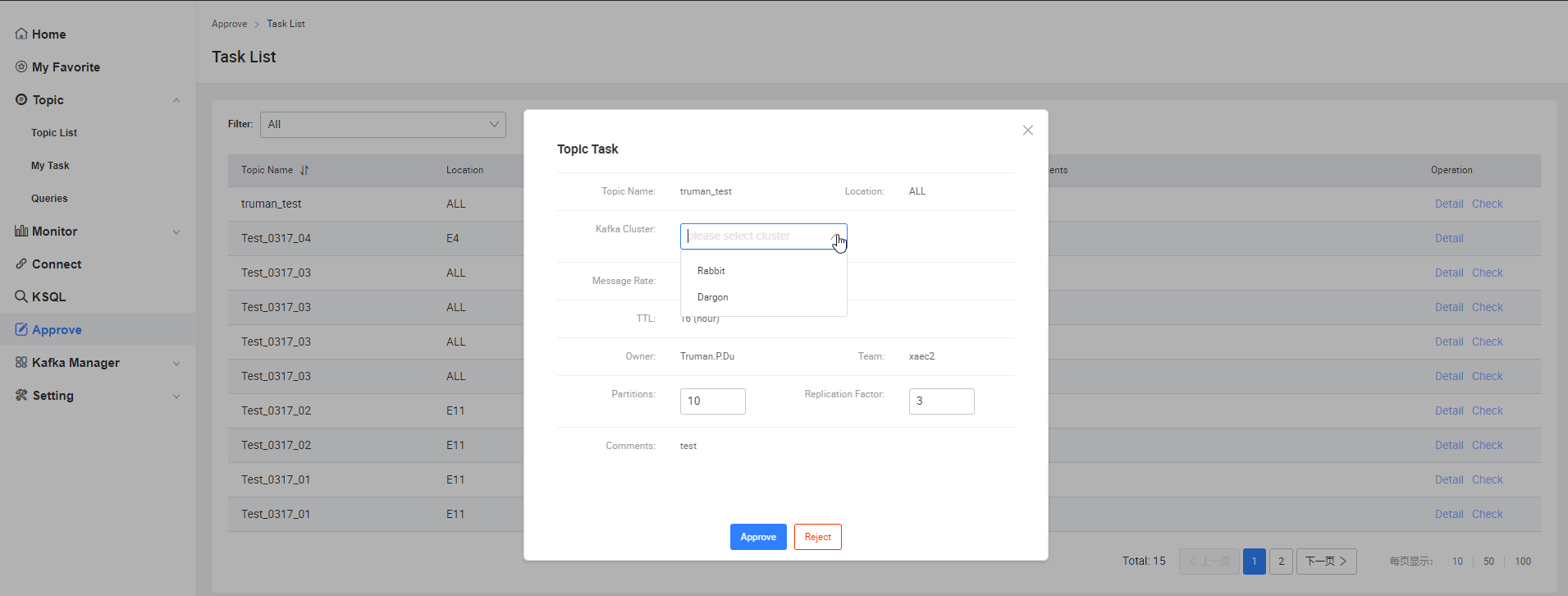
Approve
這里主要是管理員做一些審核操作
- Approve->check 審批用戶的Task
- 根據用戶選擇的location指定cluster
- 檢查用戶設定的partition和replication大小是否合理,如不合理做出調整
- 檢查其他欄位是否合理,如需要拒絕該申請,點擊Reject并填寫意見,
Kafka Manager
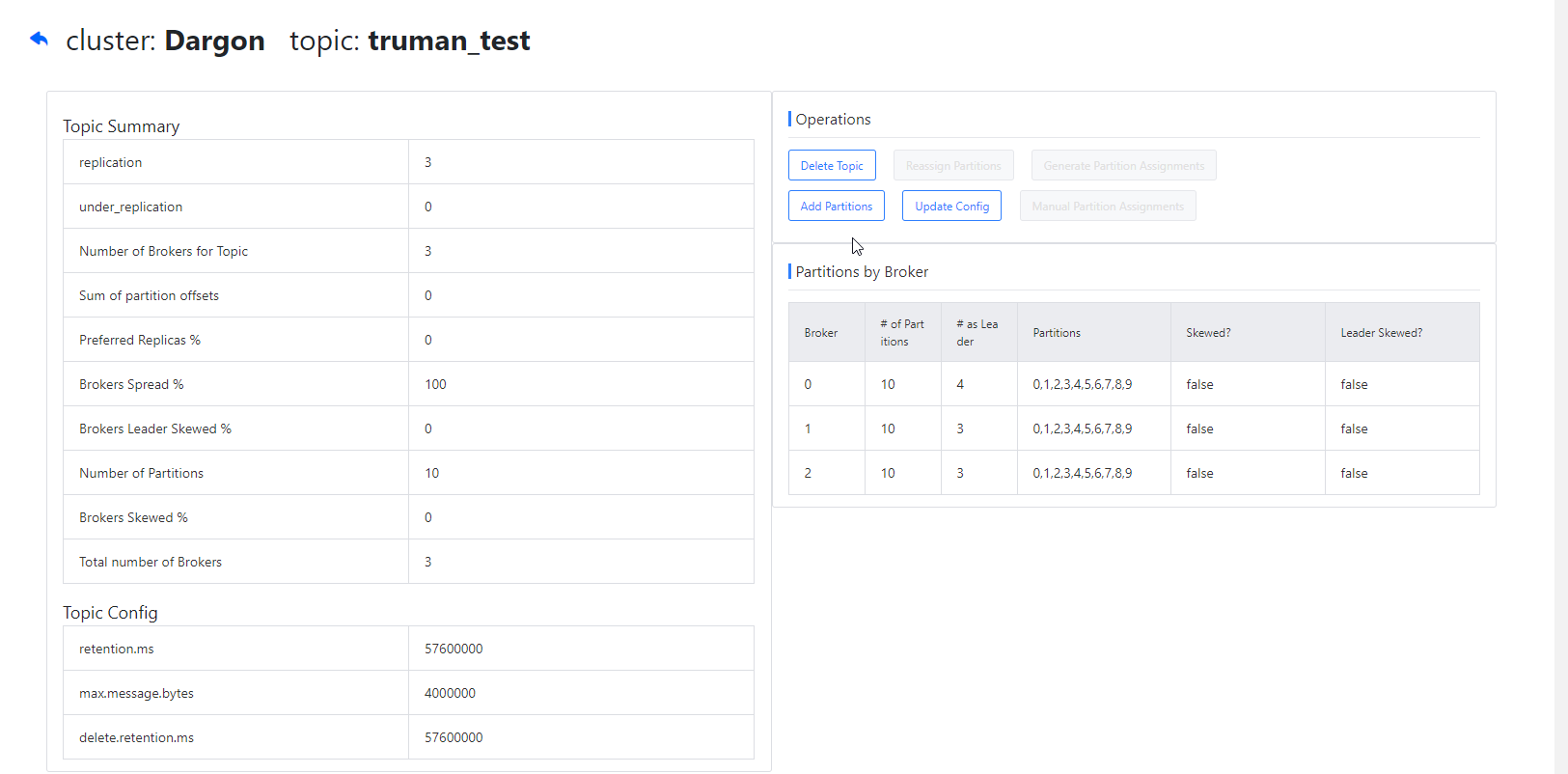
Topic管理
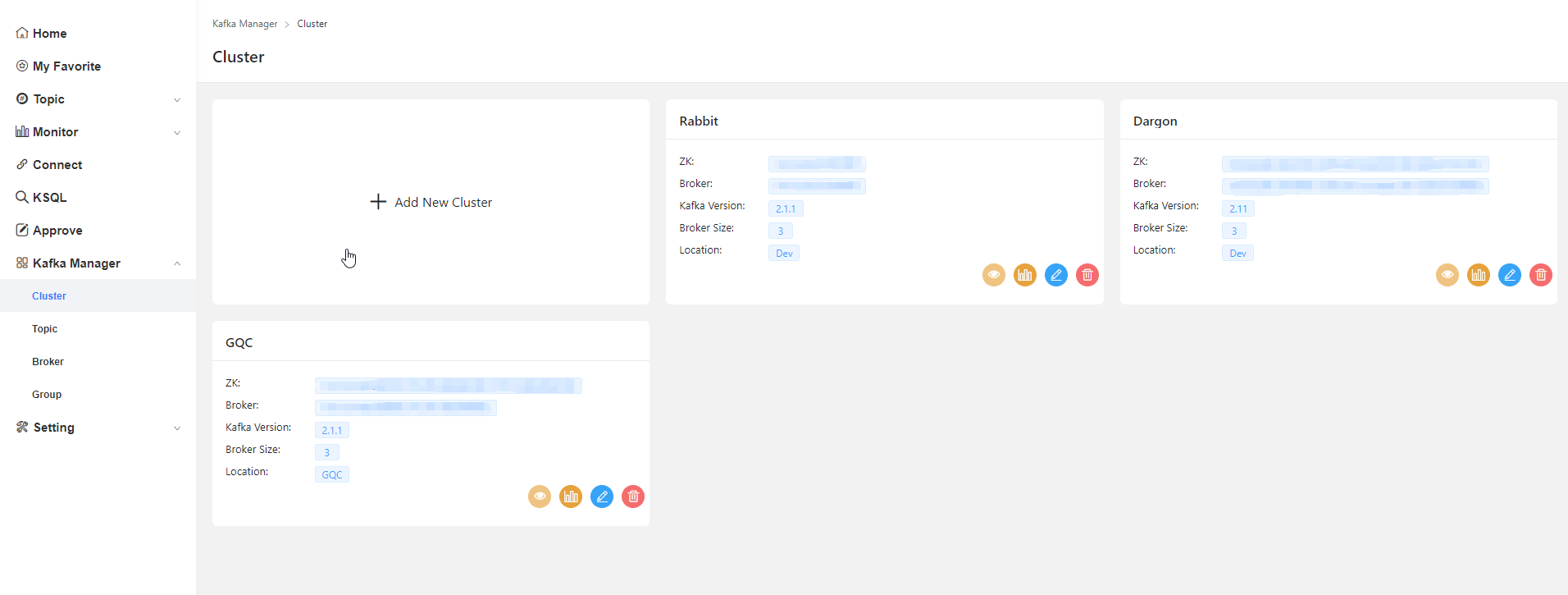
Cluster管理
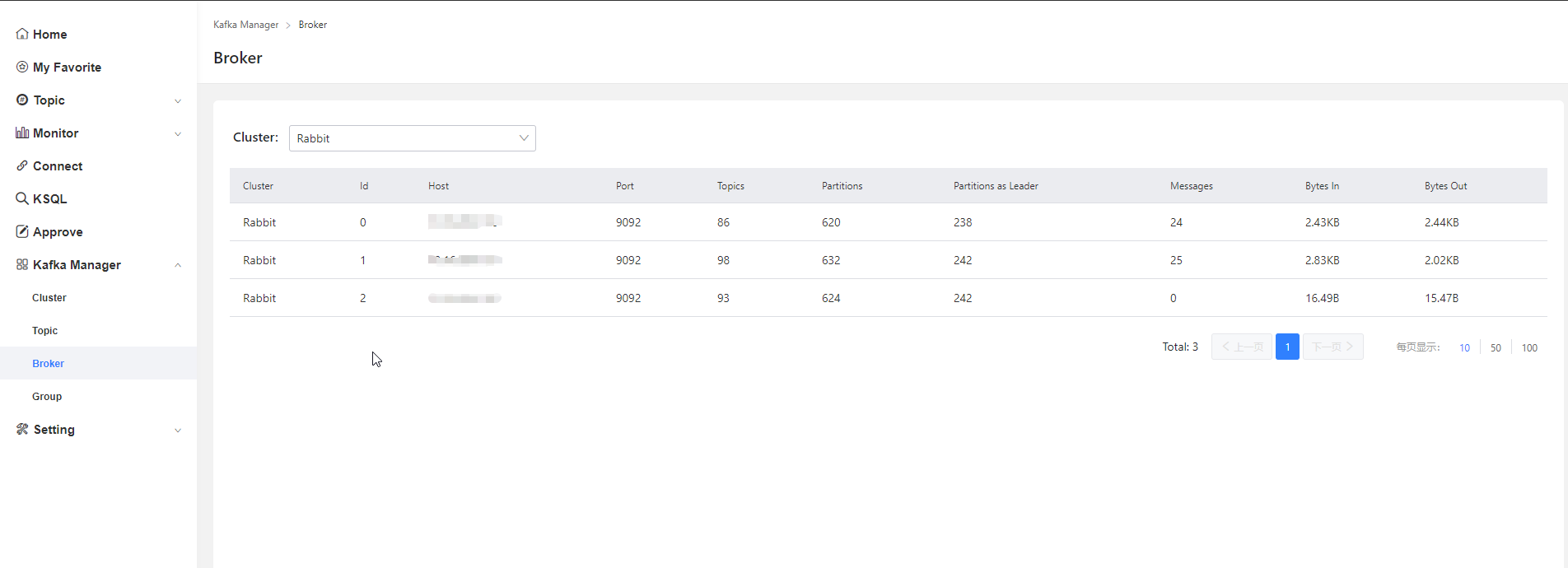
broker管理
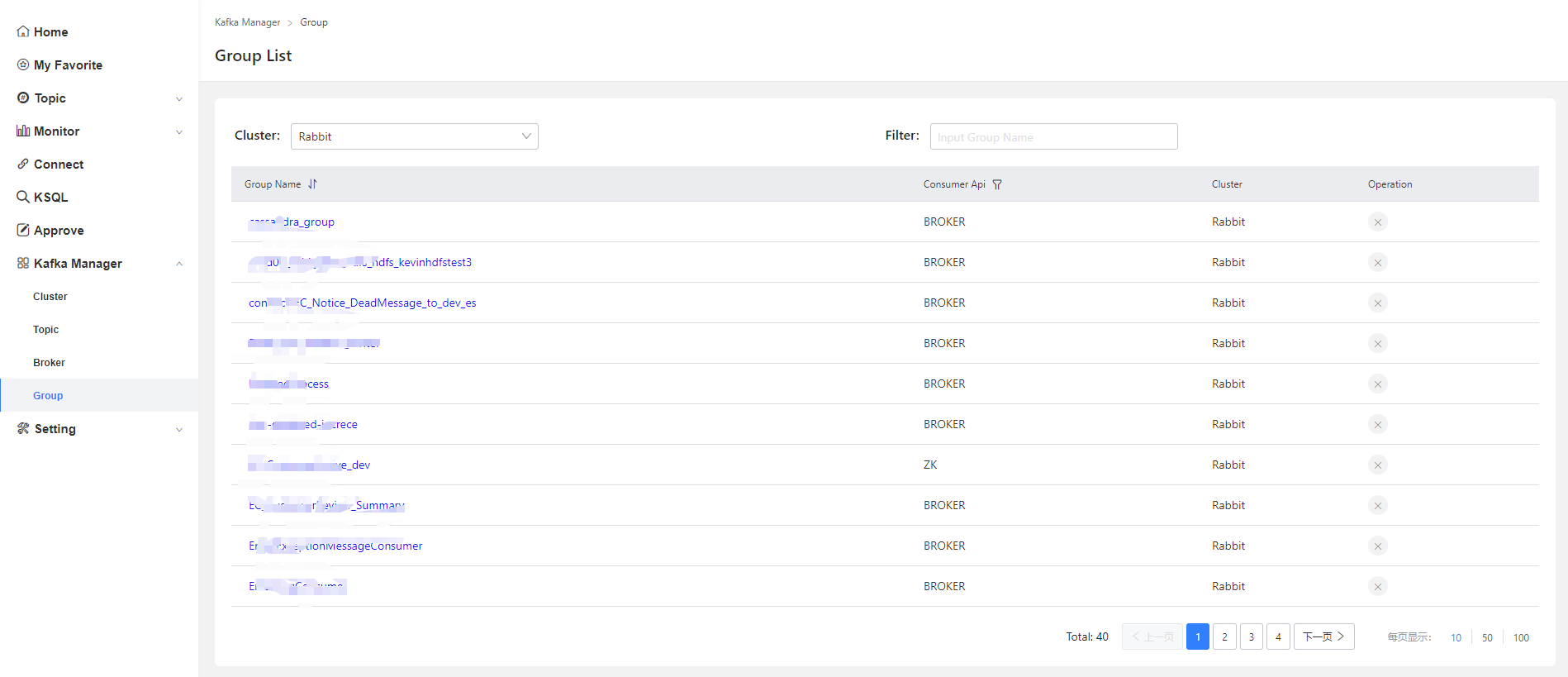
group管理
Setting
這些主要是用戶的一些設定
KafkaCenter還是一個非常不錯的kafka管理工具,可以滿足大部分需求,
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/8647.html
標籤:大數據