前言
資料科學部為想從事大資料方向學習的小伙伴總結了一下大資料的學習路線,供大家學習參考,由于大資料是一個基礎門檻較高就業前景較好的學習方向,所以打算學習大資料的小伙伴要加油啦!
大資料學習路線:
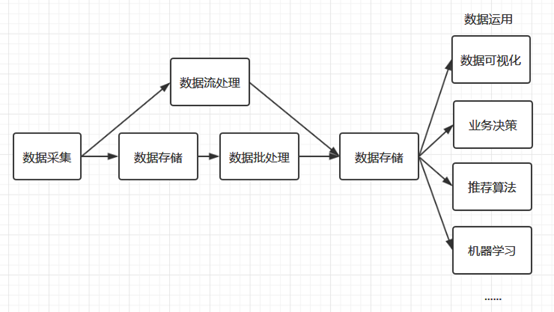
首先我要了解大資料處理流程:
第一步:資料收集
第二部:資料存盤
第三步:資料分析
第四步:資料應用
資料收集
大資料處理的第一步是資料的收集,現在的中大型專案通常采用微服務架構進行分布式部署,所以資料的采集需要在多臺服務器上進行,且采集程序不能影響正常業務的開展,基于這種需求,就衍生了多種日志收集工具,如 Flume 、Logstash等,它們都能通過簡單的配置完成復雜的資料收集和資料聚合,
資料存盤
收集到資料后,下一個問題就是:資料該如何進行存盤?我們通常熟知的就是把資料存入MySQL、Oracle等傳統的關系型資料庫,這些傳統的資料庫的特點是能夠快速存盤結構化的資料,并支持隨機訪問,但大資料的資料結構通常是半結構化(如日志資料)、甚至是非結構化的(如視頻、音頻資料),為了解決海量半結構化和非結構化資料的存盤,衍生了 Hadoop HDFS 、KFS、GFS 等分布式檔案系統,它們都能夠支持結構化、半結構和非結構化資料的存盤,并可以通過增加機器進行橫向擴展,
分布式檔案系統完美地解決了海量資料存盤的問題,但是一個優秀的資料存盤系統需要同時考慮資料存盤和訪問兩方面的問題,比如你希望能夠對資料進行隨機訪問,這是傳統的關系型資料庫所擅長的,但卻不是分布式檔案系統所擅長的,那么有沒有一種存盤方案能夠同時兼具分布式檔案系統和關系型資料庫的優點,基于這種需求,就產生了 HBase、MongoDB,
資料分析
大資料處理最重要的環節就是資料分析,資料分析通常分為兩種:批處理和流處理,
批處理:對一段時間內海量的離線資料進行統一的處理,對應的處理框架有 Hadoop MapReduce、Spark、Flink 等;
流處理:對運動中的資料進行處理,即在接收資料的同時就對其進行處理,對應的處理框架有 Storm、Spark Streaming、Flink Streaming 等,
批處理和流處理各有其適用的場景,時間不敏感或者硬體資源有限,可以采用批處理;時間敏感和及時性要求高就可以采用流處理,隨著服務器硬體的價格越來越低和大家對及時性的要求越來越高,流處理越來越普遍,如股票價格預測和電商運營資料分析等,
資料應用
資料分析完成后,接下來就是資料應用的范疇,這取決于你實際的業務需求,比如你可以將資料進行可視化展現,或者將資料用于優化你的推薦演算法,這種運用現在很普遍,比如短視頻個性化推薦、電商商品推薦、頭條新聞推薦等,當然你也可以將資料用于訓練你的機器學習模型,這些都屬于其他領域的范疇,都有著對應的框架和技術堆疊進行處理,這里就不一一贅述,
學習路線
學習大資料門檻相對較高,首先要有一定的語言基礎
1.java
大資料框架大多采用 Java 語言進行開發,并且幾乎全部的框架都會提供 Java API ,Java 是目前比較主流的后臺開發語言,所以網上免費的學習資源也比較多,
2.scala
Scala 是一門綜合了面向物件和函式式編程概念的靜態型別的編程語言,它運行在 Java 虛擬機上,可以與所有的 Java 類別庫無縫協作,著名的 Kafka 就是采用 Scala 語言進行開發的,
為什么需要學習 Scala 語言 ? 這是因為當前最火的計算框架 Flink 和 Spark 都提供了 Scala 語言的介面,使用它進行開發,比使用 Java 8 所需要的代碼更少,且 Spark 就是使用 Scala 語言進行撰寫的,學習 Scala 可以幫助你更深入的理解 Spark,
Linux基礎
通常大資料框架都部署在 Linux 服務器上,所以需要具備一定的 Linux 知識,
構建工具
這里需要掌握的自動化構建工具主要是 Maven,Maven 在大資料場景中使用比較普遍,主要在以下三個方面:
1.管理專案 JAR 包,幫助你快速構建大資料應用程式;
2.不論你的專案是使用 Java 語言還是 Scala 語言進行開發,提交到集群環境運行時,都需要使用 Maven 進行編譯打包;
3.大部分大資料框架使用 Maven 進行原始碼管理,當你需要從其原始碼編譯出安裝包時,就需要使用到 Maven,
框架學習
我們對框架進行簡單的分類總結:
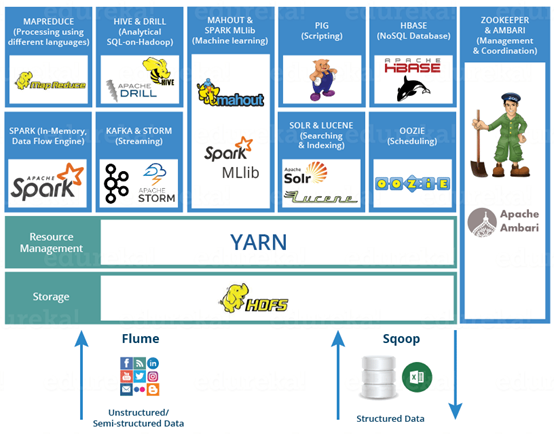
日志收集框架:Flume 、Logstash、Kibana
分布式檔案存盤系統:Hadoop HDFS
資料庫系統:Mongodb、HBase
分布式計算框架:
- 批處理框架:Hadoop MapReduce
- 流處理框架:Storm
- 混合處理框架:Spark、Flink
查詢分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
集群資源管理器:Hadoop YARN
分布式協調服務:Zookeeper
資料遷移工具:Sqoop
任務調度框架:Azkaban、Oozie
集群部署和監控:Ambari、Cloudera Manager
上面列出的都是比較主流的大資料框架,社區都很活躍,學習資源也比較豐富,建議從 Hadoop 開始入門學習,因為它是整個大資料生態圈的基石,其它框架都直接或者間接依賴于 Hadoop ,接著就可以學習計算框架,Spark 和 Flink 都是比較主流的混合處理框架,Spark 出現得較早,所以其應用也比較廣泛, Flink 是當下最火熱的新一代的混合處理框架,其憑借眾多優異的特性得到了眾多公司的青睞,兩者可以按照你個人喜好或者實際作業需要進行學習,
開發工具
這里推薦一些大資料常用的開發工具:
Java IDE:IDEA 和 Eclipse 都可以,從個人使用習慣而言,更傾向于 IDEA ;
VMware Workstation:在學習程序中,你可能經常要在虛擬機上搭建服務和集群,
MobaXterm:大資料的框架通常都部署在服務器上,這里推薦使用 MobaXterm 進行連接,同樣是免費開源的,支持多種連接協議,支持拖拽上傳檔案,支持使用插件擴展;
Translate Man:一款瀏覽器上免費的翻譯插件 (谷歌和火狐均支持),它采用谷歌的翻譯介面,準確性非常高,支持劃詞翻譯,可以輔助進行官方檔案的閱讀,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/8654.html
標籤:大數據
上一篇:選方向?大資料的職位你了解多少