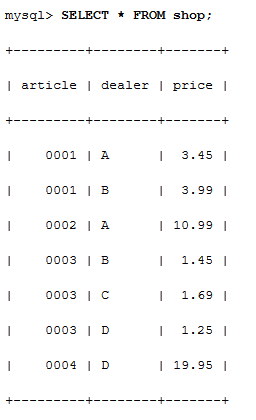
有一張shop比表 3個欄位分別是物品 , 經銷商,價格.
然后手冊中給了一個這樣的例子和解答
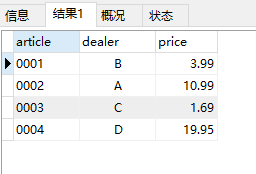
這是按它給的SQL陳述句得到的查詢結果.
問題:這個結果是怎么產生的?試了一下,這里的where字句用IN得到的查詢也是一樣的,那么怎么能用=呢,怎么解釋?
uj5u.com熱心網友回復:
實在是搞不懂它怎么實作的
uj5u.com熱心網友回復:
in 后面可以跟多個數值,也可以只跟一個值。
本例子中,max 函式已經限定了回傳值,只有一個,所以用in 也可以。
uj5u.com熱心網友回復:
這個查詢SQL是一個包含子查詢的模式,select * from a where a.XXX ...(select max(b.xxx) from b...)。
因為子查詢回傳的是一個max的結果,即一個值,所以可以使用“a.XXX=”,也可以用“a.XXX in”。當然使用等號查詢更快點。
uj5u.com熱心網友回復:
參考 3 樓 splendid_java 的回復: 這個查詢SQL是一個包含子查詢的模式,select * from a where a.XXX ...(select max(b.xxx) from b...)。
關于這個例子我還是沒有懂,如果子查詢只回傳一個值,只回傳一個max的結果,那整個查詢也只會回傳一行記錄啊,顯然這里回傳了4行記錄,不就是說明回傳了4個max值嗎?
uj5u.com熱心網友回復:
參考 2 樓 wmxcn2000 的回復: in 后面可以跟多個數值,也可以只跟一個值。
可我怎么看都覺得是回傳個4個max值呢,不然怎么查出4行記錄的呢?
uj5u.com熱心網友回復:
還不太會用,不知道怎么給各位發私信求解答,只能給各位丟個板磚看能不能收到了
uj5u.com熱心網友回復:
用in是不對的,比如A商品最高價是10塊,B商品的次高價也是10塊,用in就會把那個低的10塊也取出來
這種陳述句想理解它沒什么別的好辦法,就只能多做多想,時間長了就會了。
日常作業中,如果沒有把握,那就測驗,通過結果檢查寫的對不對
或者避免寫復雜sql,利用外部語言分解復雜的需求,使用簡單sql解決復雜問題
uj5u.com熱心網友回復:
參考 6 樓 f45056231p 的回復: 還不太會用,不知道怎么給各位發私信求解答,只能給各位丟個板磚看能不能收到了
我想你還是沒理解子查詢的含義,子查詢與主表逐一按照article欄位進行比對,取該article對應的最大值,不是整個表的最大值。
count(distinct article),有幾個值,查詢結果就會出現幾條記錄。理解?
uj5u.com熱心網友回復:
因為子查詢的max和where確定通過dealer分組來獲取每組dealer不同的最大值,max的值每次獲取的時候肯定是只有一條的,所以可以用=,因為子查詢相當于分組功能,所以每組都會有一個最大值。查詢結果就會有這么幾條
uj5u.com熱心網友回復:
參考 5 樓 f45056231p 的回復: Quote: 參考 2 樓 wmxcn2000 的回復:
在子查詢中,有一個條件 是 s1.xx = s2.xx ,這就是說 s1 表中每一行,都全這樣計算一下,每次回傳一個值。 所以結果可能是 4 行資料。
uj5u.com熱心網友回復:
參考 10 樓 wmxcn2000 的回復: Quote: 參考 5 樓 f45056231p 的回復: Quote: 參考 2 樓 wmxcn2000 的回復:
那既然是這樣,但為何可以用=呢?
uj5u.com熱心網友回復:
參考 10 樓 wmxcn2000 的回復: Quote: 參考 5 樓 f45056231p 的回復: Quote: 參考 2 樓 wmxcn2000 的回復:
而且這個條件 s1.xx = s2.xx ,s1和s2都是指的同一個表shop啊,這個運算式怎么理解?
uj5u.com熱心網友回復:
s1 表中有 4 。
首先,取出第 1 行, xx 列的值也就有了,price 也有了,到子查詢中,做一個查詢,取到了 max(price) ,再拿這個值 和 s1.price 做比較,條件成立,留下這行,不成立,直接放棄 。
再取 第 2 行。
再取 第 3 行。
4
5
6
10000
uj5u.com熱心網友回復:
參考 13 樓 wmxcn2000 的回復: s1 表中有 4 。
我無法理解的幾點:
1.在有子查詢的情況下,這比如這條例子,它的執行順序?比如:先from(兩個from一起?),where(哪個先?),最后select(哪個先),這個執行順序?
2.就按你們所說的,子查詢的那句是有4個回傳值,是不是相當于把shop表對自身做了一次笛卡爾積,那后面那個where條件變成了兩個shop表的聯接條件?那max()的分組條件在哪呢?
3.=和in ,如果子查詢有4個回傳值,怎么么能用=呢?不該是只能用in嗎?
uj5u.com熱心網友回復:
參考 8 樓 splendid_java 的回復: Quote: 參考 6 樓 f45056231p 的回復:
還是沒懂,大佬過來幫忙看下我的新回復,可能是我沒把我想問的描述清楚
uj5u.com熱心網友回復:
參考 15 樓 f45056231p 的回復: Quote: 參考 8 樓 splendid_java 的回復: Quote: 參考 6 樓 f45056231p 的回復:
指出一點,對于這個疑問,你不理解的根本原因在于你是用一個靜態的思維去分析這個sql,建議先看看執行計劃(explain 你的sql)。
uj5u.com熱心網友回復:
參考 14 樓 f45056231p 的回復: 我無法理解的幾點:
參考 16# 的建議,研究一下執行計劃,好多東西,自然就明白 了。
uj5u.com熱心網友回復:
參考 16 樓 splendid_java 的回復: Quote: 參考 15 樓 f45056231p 的回復: Quote: 參考 8 樓 splendid_java 的回復: Quote: 參考 6 樓 f45056231p 的回復:
謝謝各位,找到了一點眉目,略懂了,原來嵌套查詢的子查詢分相關和非相關的,這條是相關子查詢,子查詢需要跟據主查詢而不斷的執行而回傳結果供主查詢使用,而不像我想的都是非相關的,子查詢只執行一次.
其他博客的原話
1.:非相關子查詢是獨立于外部查詢的子查詢,子查詢總共執行一次,執行完畢后將值傳遞給外部查詢,并且它是優先于外部查詢先執行的,他執行了再執行外部。
2.相關子查詢的執行依賴于外部查詢的資料,外部查詢執行一行,子查詢就執行一次。并且是外部先查詢一次,然后再執行一次內部查詢!
這些我能理解了
那么我的問題來了:
1.是不是這樣理解:那我說的這個例子中,就意味著主查詢和子查詢都執行了7次,主查詢每查詢一次,獲得一個結果集,然后按子查詢的where條件篩選,回傳一個max(),那總共回傳了7個max值,另外3個有重復值是自動被過濾了嗎
uj5u.com熱心網友回復:
參考 17 樓 wmxcn2000 的回復: Quote: 參考 14 樓 f45056231p 的回復:
大佬,來看一下我的新問題.
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/86752.html
標籤:MySQL
上一篇:有效時間演算法
下一篇:求助,時間戳列轉為日期再插入一列