前言
夜深人靜的時候,打開云音樂,點上一曲攀登,帶上真無線藍牙耳機,瞬間燃到爆,鍵盤打字如飛倦意全無,
分片規則
這幾天有人問我,dble和MyCat到底有什么不同,其實dble作為MyCAT的同門,吸收了MyCat的精華,同時也相應的做了一些減法,只支持MySQL顯得更加的純粹,所以選擇對比學習兩者我覺得挺好,
前面我們學習了schema.xml檔案的配置,我們能獨立的把邏輯庫和邏輯表搭建起來,讓資料表跟隨我們的定義規則(取模)進行分布,今天我們介紹具體的分片演算法,dble相對于mycat來說,是做了一些減法的,比如一致hash演算法就沒有,而是使用了jumpstringhash代替了一致性hash,具體原因可以參考文章dble 沿用 jumpstringhash,移除 Mycat 一致性 hash 原因
hash磁區演算法- stringhash磁區演算法
- enum磁區演算法
- numberrange磁區演算法
- patternrange磁區演算法
- date磁區演算法
- jumpstringhash演算法
HASH磁區演算法
Hash磁區演算法是一種比較典型而且常用的演算法,要使用HASH磁區演算法需要在rule.xml中定義兩個部分,
磁區規則定義
如下所示,使用tableRule標簽定義,name對應的是規則的名字,而rule標簽中的columns則對應的分片欄位,這個欄位必須和表中的欄位一致,algorithm則代表了執行分片函式的名字,
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
磁區演算法定義
如下所示,使用function標簽定義磁區演算法,name代表演算法的名字,演算法的名字要和上面的tableRule中的標簽相對應,class:指定磁區演算法實作類,property指定了對應磁區演算法的引數,不同的演算法引數不同,
<function name="rang-long" >
<property name="mapFile">auto-sharding-long.txt</property>
...
</function>
partitionCount:指定磁區的區間數,具體為 C1 +C2 + ... + CnpartitionLength:指定各區間長度,具體區間劃分為 [0, L1), [L1, 2L1), ..., [(C1-1)L1, C1L1), [C1L1, C1L1+L2), [C1L1+L2, C1L1+2L2), ... 其中,每一個區間對應一個資料節點,
測驗Hash磁區演算法
1.在啟動的時候,兩個陣列點乘做運算,得到取模數,
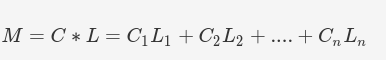
2.兩個陣列進行叉乘,得出物理磁區表,
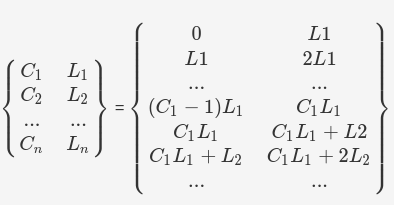
3.根據where條件的值來落入實際分片
select * from shareding_key = 999;
先根據分片鍵取出999,按照公式1的計算結果除取模,然后得到的值落到2計算出來的分片中,
4.舉個簡單的例子:
<property name="partitionCount">2,3</property>
<property name="partitionLength">100,50</property>
根據公式1
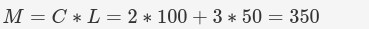
也就是傳進來的值需要對350取模,
根據公式2,物理磁區為

999對350取模,正好是299,落在250-300這個區間里面,也就是第4個區間,
接下來我們實際來測驗一下,我們在rule.xml中設定如下:
<tableRule name="rule_hash">
<rule>
<columns>id</columns>
<algorithm>func_hash_test</algorithm>
</rule>
</tableRule>
<function name="func_hash_test" >
<property name="partitionCount">2,3</property>
<property name="partitionLength">100,50</property>
</function>
我們通過公式2算出有5個分片,所以在schema.xml中設定table屬性如下:
<table name="hash_test" primaryKey="id" rule="rule_hash" dataNode="dn1,dn2,dn3,dn4,dn5"/>
5.創建表測驗
我們先使用shell創建1000行資料,在創建表,通過load data語法將我們shell產生的檔案進行匯入,
for i in {1..1000}
do
echo $i'|name'$[i]'' >>a1.txt
done
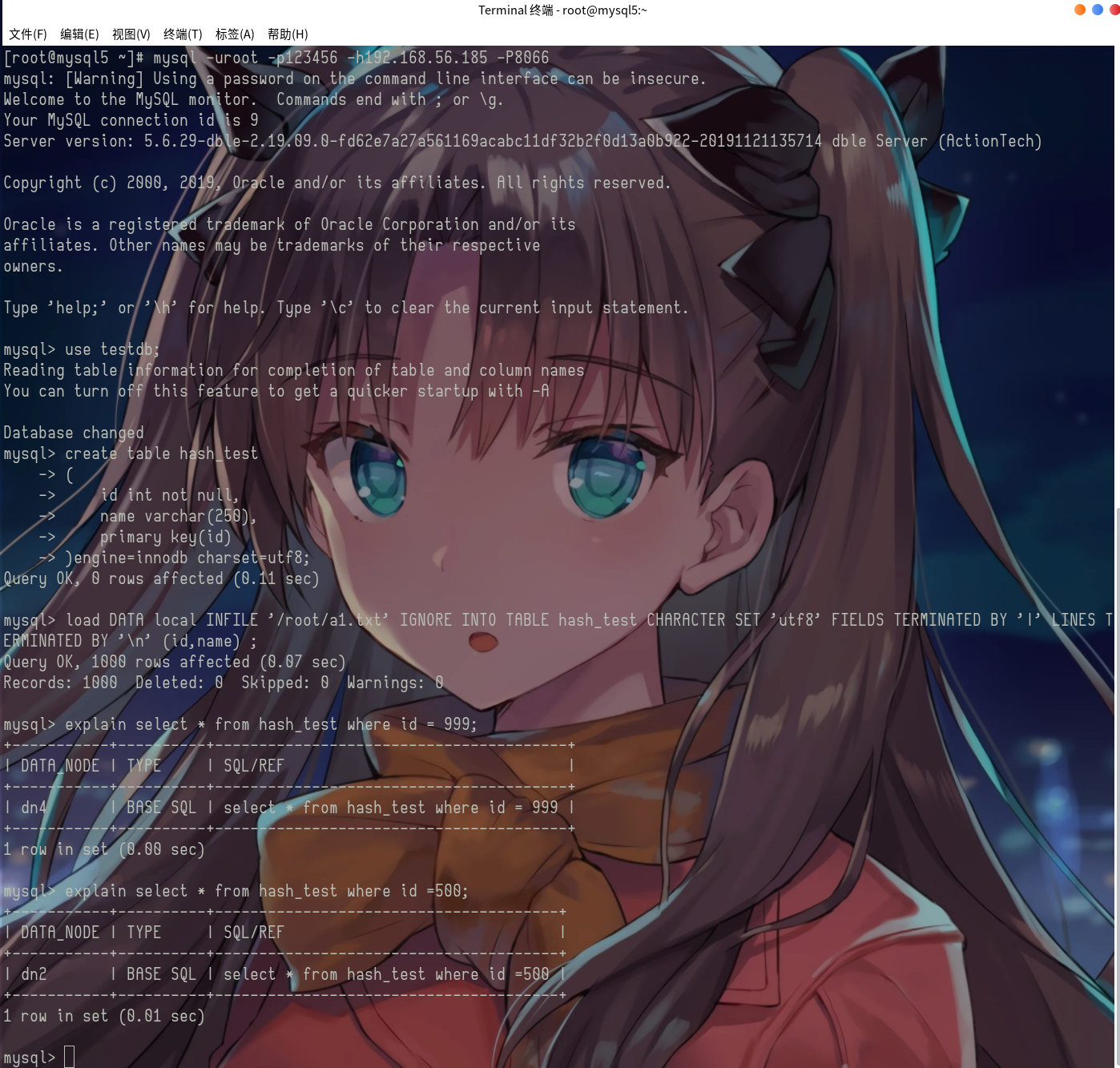
請原諒我作為一個GEEK,把桌面和終端完美結合成二次元是標配,
這里可以看到我們查詢999這個資料,會自動到dn4這個分片上進行查詢,再比如我們查500,500對350取模是150,150是落在第二個磁區里面的,
6.另一個例子
<property name="partitionCount">2</property>
<property name="partitionLength">1000</property>
此時C _L=2_1000=2000,將對2000進行取模,
同時將劃分如下的磁區:

注意事項
- M不能大于2880,2880的原因是這樣的:2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 18, 20, 24, 30, 32, 36, 40, 45, 48, 60, 64, 72, 80, 90, 96, 120, 144, 160, 180, 192, 240, 288, 320, 360, 480, 576, 720, 960, 1440是2880的約數,這樣預分片擴容方便,
- N必須要等于schema.xml中使用該磁區演算法的邏輯表的dataNode屬性指定的DataNode數量之和,比如我們上面這個演算法是5個磁區,但是如果你在邏輯表的dataNode屬性中設定磁區個數小于5,dataNode="dn1,dn2,dn3,dn4",則dble就會報錯,
partition size : 5 > table datanode size : 4 please make sure table datanode size = function partition size - $C_n$和$L_n$的個數必須相等,
- 磁區欄位必須為整型欄位,如果是其他型別,要求值可轉化為數字,
- 當partitionLength為1時,hash磁區演算法退化為求模演算法,M及N均為partitionCount的值,
- NULL作為分片列的值的時候資料的結果恒落在0號節點(第一個節點上),建議最好不要讓這種情況出現,強制設定分片鍵為not null,
后記
今天學習了分片演算法Hash,后續將繼續分享其他的演算法,謝謝支持!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/89039.html
標籤:MySQL
上一篇:大小寫轉換