分庫分表之第五篇
- 9.案例
- 9.1.需求描述
- 9.2.資料庫設計
- 9.3.環境說明
- 9.4.環境準備
- 9.4.1.mysql主從同步(windows)
- 9.4.2.初始化資料庫
- 9.5.實作步驟
- 9.5.1搭建maven工程
- 9.5.2 分片配置
- 9.5.3 添加商品
- 9.5.4 查詢商品
- 9.5.5 統計商品
- 10. 總結
9.案例
9.1.需求描述
電商平臺商品串列展示,每個串列項中除了包含商品基本資訊、商品描述資訊之外,還包括了商品所屬的店鋪資訊,如下 :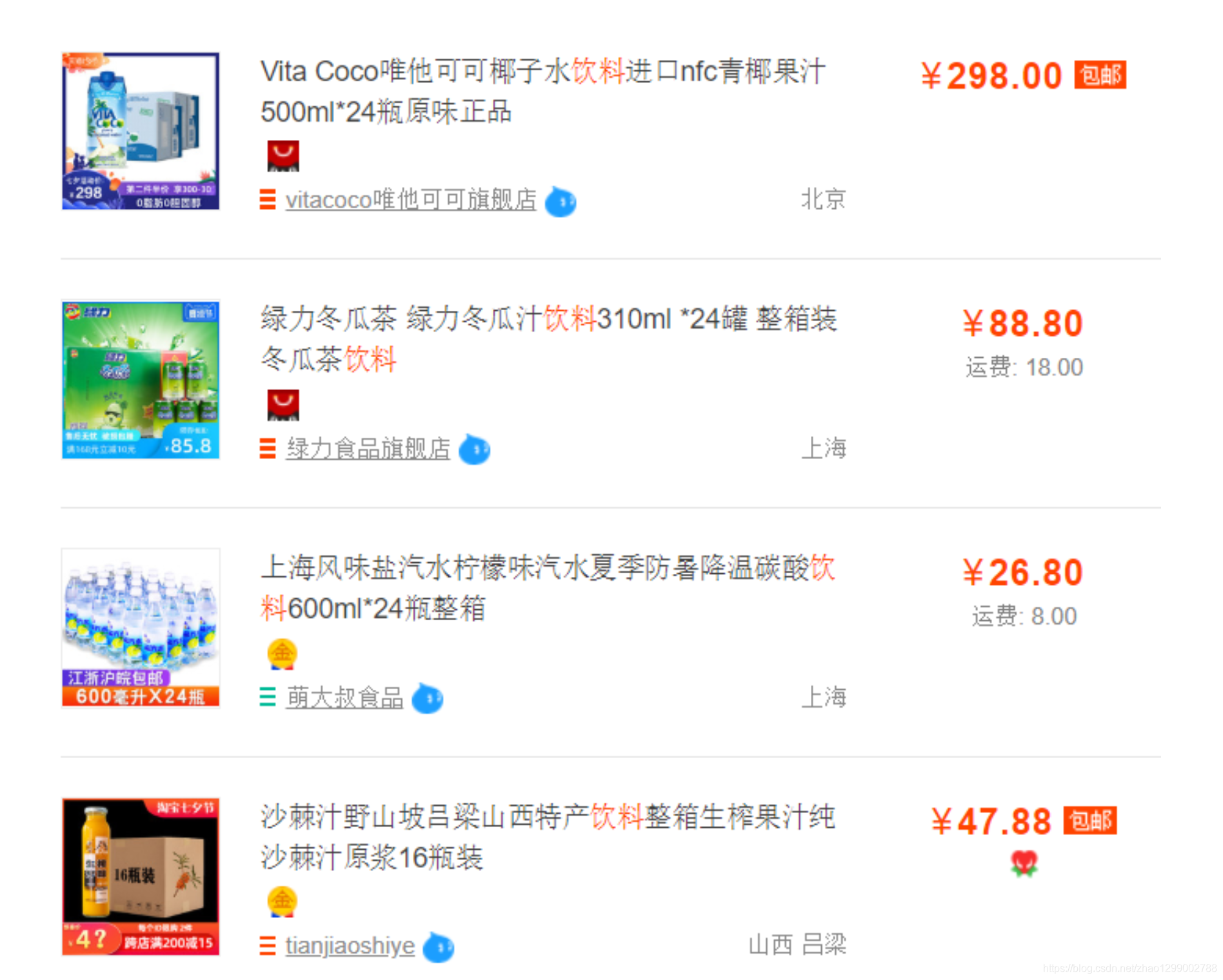
本案例實作功能如下:
1、添加商品
2、商品分頁查詢
3、商品統計
9.2.資料庫設計
資料庫設計如下,其中商品與店鋪資訊之間進行了垂直分庫,分為了PRODUCT_DB(商品庫)和STORE_DB(店鋪庫);商品資訊還進行了垂直分表,分為了商品基本資訊(product_info)和商品描述資訊(product_descript),地理區域資訊(region)作為公共表,冗余在兩庫中 :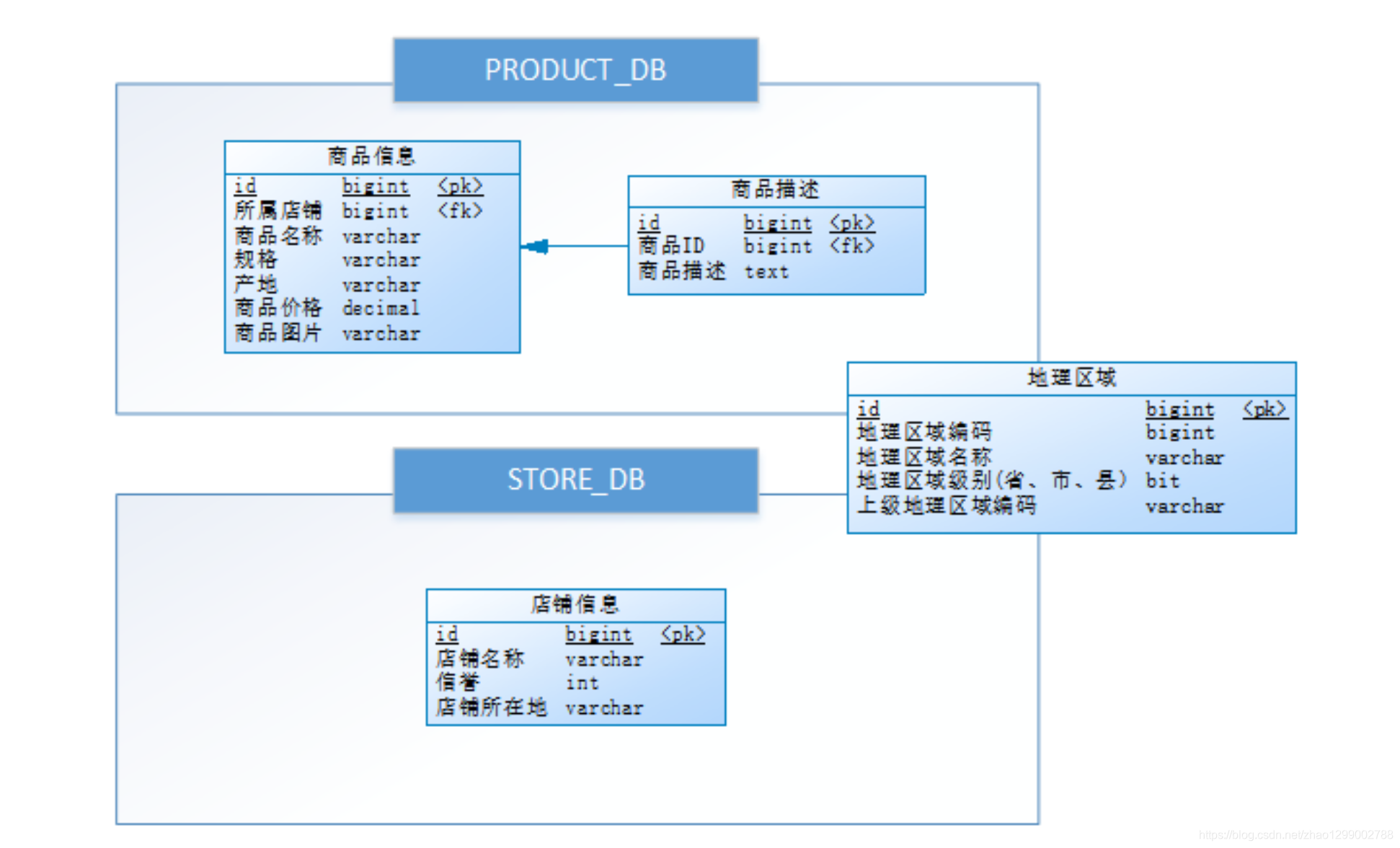
考慮到商品資訊的資料增長性,對PRODUCT_DB(商品庫)進行了水平分庫,分片鍵使用店鋪id,分片策略為店鋪 ID%2 + 1,因此商品描述資訊對所屬店鋪ID進行了冗余;
對商品基本資訊(product_info)和商品描述資訊(product_descript)進行水平分表,分片鍵使用商品id,分片策略為 商品ID%2 + 1,并將為這兩個表設定為系結表,避免笛卡爾積join;
為避免主鍵沖突,ID生成策略采用雪花演算法來生成全域唯一ID,最終資料庫設計為下圖: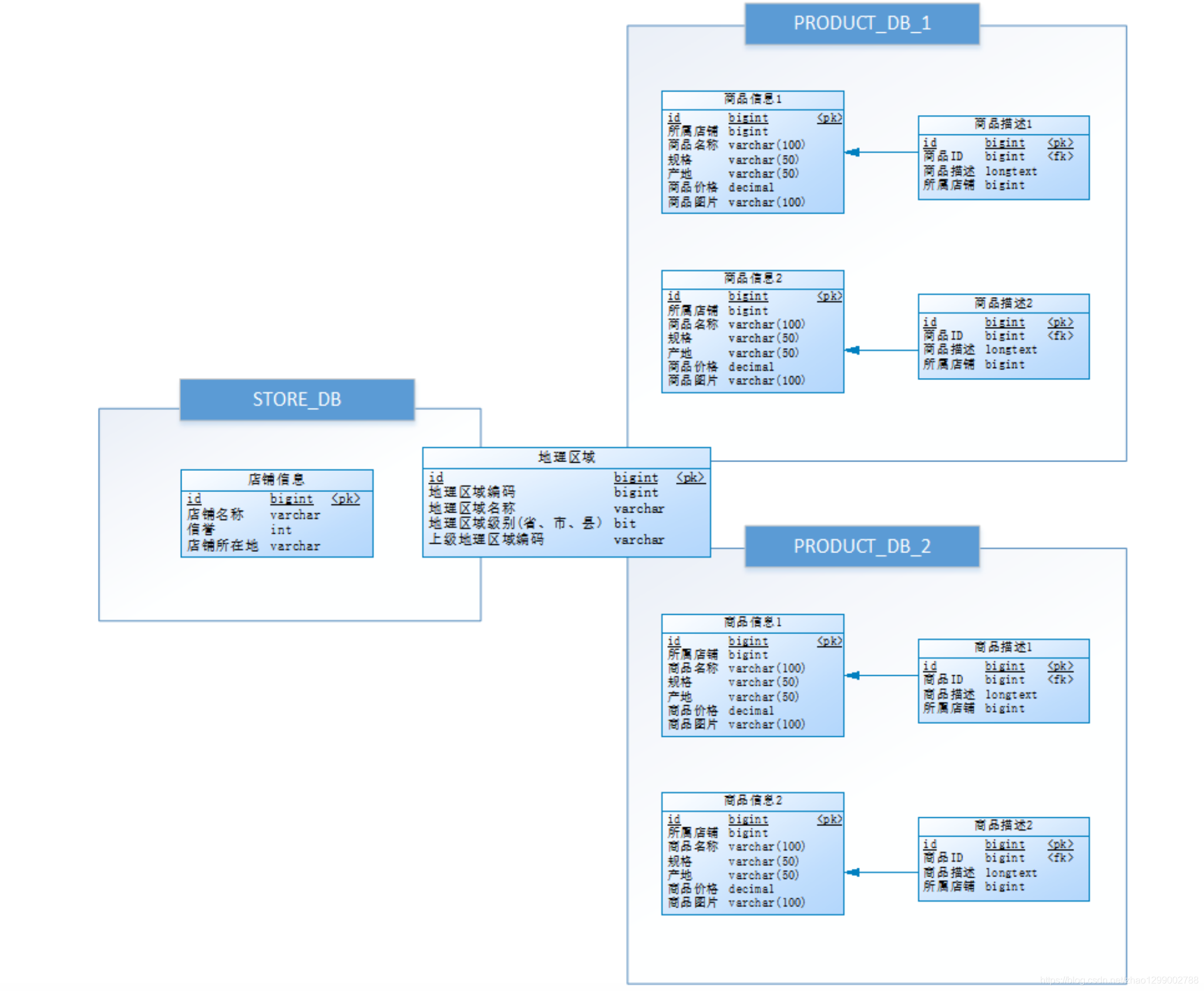
要求使用讀寫分離來提升性能,可用性,
9.3.環境說明
- 作業系統 :win10
- 資料庫 :MySQL-5.7.25
- JDK :64位 jdk1.8.0_201
- 應用框架 :spring-bbot-2.1.3.RELEASE,MyBatis3.5.0
- Sharding-JDBC :sharding-jdbc-spring-boot-starter-4.0.0-RC1
9.4.環境準備
9.4.1.mysql主從同步(windows)
參考讀寫分離章節,對以下庫進行主從同步配置 :
# 設定需要同步的資料庫
binlog‐do‐db=store_db
binlog‐do‐db=product_db_1
binlog‐do‐db=product_db_2
9.4.2.初始化資料庫
創建store_db資料庫,并執行以下腳本創建表 :
DROP TABLE IF EXISTS `region`; CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理區域編碼',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理區域名稱',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理區域級別(省、市、縣)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '上級地理區域編碼',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `region` VALUES (1, '110000', '北京', 0, NULL); INSERT INTO `region` VALUES (2, '410000', '河南省', 0, NULL); INSERT INTO `region` VALUES (3, '110100', '北京市', 1, '110000'); INSERT INTO `region` VALUES (4, '410100', '鄭州市', 1, '410000');
DROP TABLE IF EXISTS `store_info`; CREATE TABLE `store_info` (
`id` bigint(20) NOT NULL COMMENT 'id',
`store_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '店鋪名稱',
`reputation` int(11) NULL DEFAULT NULL COMMENT '信譽等級',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '店鋪所在地',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `store_info` VALUES (1, 'XX零食店', 4, '110100'); INSERT INTO `store_info` VALUES (2, 'XX飲品店', 3, '410100');
創建product_db_1、product_db_2資料庫,并分別對兩庫執行以下腳本創建表:
DROP TABLE IF EXISTS `product_descript_1`; CREATE TABLE `product_descript_1` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述',`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id', PRIMARY KEY (`id`) USING BTREE,
INDEX `FK_Reference_2`(`product_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `product_descript_2`; CREATE TABLE `product_descript_2` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述', `store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
PRIMARY KEY (`id`) USING BTREE,
INDEX `FK_Reference_2`(`product_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `product_info_1`; CREATE TABLE `product_info_1` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '商品名稱',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '規
格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'產地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品價格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'商品圖片',
PRIMARY KEY (`product_info_id`) USING BTREE,
INDEX `FK_Reference_1`(`store_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `product_info_2`; CREATE TABLE `product_info_2` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '商品名稱',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '規
格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'產地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品價格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'商品圖片',
PRIMARY KEY (`product_info_id`) USING BTREE,
INDEX `FK_Reference_1`(`store_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `region`;
CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id', `region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理區域編碼',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理區域名稱',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理區域級別(省、市、縣)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '上級地理區域編碼',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `region` VALUES (1, '110000', '北京', 0, NULL); INSERT INTO `region` VALUES (2, '410000', '河南省', 0, NULL); INSERT INTO `region` VALUES (3, '110100', '北京市', 1,