關聯查詢
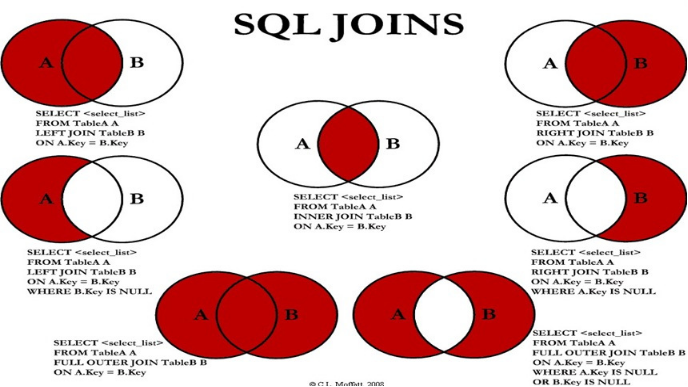
1、內連接:實作A∩B
select 欄位串列 from A表 inner join B表 on 關聯條件 where 等其他子句;
2、左外連接
#實作查詢結果是A select 欄位串列 from A表 left join B表 on 關聯條件 where 等其他子句; #實作A - A∩B select 欄位串列 from A表 left join B表 on 關聯條件 where 從表關聯欄位 is null and 等其他子句;
3、右外連接
#實作查詢結果是B select 欄位串列 from A表 right join B表 on 關聯條件 where 等其他子句; #實作B - A∩B select 欄位串列 from A表 right join B表 on 關聯條件 where 從表關聯欄位 is null and 等其他子句;
4、用union代替全外連接
#實作查詢結果是A∪B #用左外的A,union 右外的B select 欄位串列 from A表 left join B表 on 關聯條件 where 等其他子句 union select 欄位串列 from A表 right join B表 on 關聯條件 where 等其他子句; #實作A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B) #使用左外的 (A - A∩B) union 右外的(B - A∩B) select 欄位串列 from A表 left join B表 on 關聯條件 where 從表關聯欄位 is null and 等其他子句 union select 欄位串列 from A表 right join B表 on 關聯條件
UNION規則
UNION中的每個查詢必須包含相同的列、運算式或聚集函式(不過,各個列不需要以相同的次序列出),
列資料型別必須兼容:型別不必完全相同,但必須是DBMS可以隱含轉換的型別(例如,不同的數值型別或不同的日期型別),
實際上,UNION在需要組合多個表的資料時也很有用,即使是有不匹配列名的表,在這種情況下,可以將UNION與別名組合,檢索一個結果集,
5、自連接:同一張表,通過取別名的方式來虛擬成兩張表
select 欄位串列 from 表名 別名1 inner/left/right join 表名 別名2 on 別名1.關聯欄位 = 別名2的關聯欄位 where 其他條件
6大子句順序
(1)from:從哪些表中篩選
(2)where:從表中篩選的條件
(3)group by:分組依據
(4)having:在統計結果中再次篩選
(5)order by:排序
降序:desc 升序:要么默認,要么加asc
雖然ORDER BY子句似乎只是最后一條SELECT陳述句的組成部分,但實際上DBMS將用它來排序所有SELECT陳述句回傳的所有結果,
(6)limit:分頁
limit m,n
m = (第幾頁 - 1)*每頁的數量
n = 每頁的數量
group by與分組函式
可以使用GROUP BY子句將表中的資料分成若干組
在SELECT串列中,所有未包含在分組函式中的列都應該包含在 GROUP BY子句中
包含在 GROUP BY 子句中的列不必包含在SELECT 串列中
having與where的區別
(1)where是從表中篩選的條件,而having是統計結果中再次篩選
(2)where后面不能加“分組/聚合函式”,而having后面可以跟分組函式
子查詢
嵌套在另一個查詢中的查詢,作為子查詢的SELECT陳述句只能查詢單個列,企圖檢索多個列將回傳錯誤,
根據位置不同,分為:
(1)where型
①子查詢是單值結果,那么可以對其使用(=,>等比較運算子)
②子查詢是多值結果,那么可對其使用(【not】in(子查詢結果),或 >all(子查詢結果),或>=all(子查詢結果),<all(子查詢結果),<=all(子查詢結果),或 >any(子查詢結果),或>=any(子查詢結果),<any(子查詢結果),<=any(子查詢結果))
(2)from型
必須給子查詢取別名,即臨時表名,表的別名不要加“”和空格
表別名不僅能用于WHERE子句,還可以用于SELECT的串列、ORDER BY子句以及其他陳述句部分,
表別名只在查詢執行中使用,與列別名不一樣,表別名不回傳到客戶端,
(3)exists型
注意:不管子查詢在哪里,子查詢必須使用()括起來
事務
保證所有事務都作為一個作業單元來執行,即使出現了故障,都不能改變這種執行方式,當在一個事務中執行多個操作時,要么所有的事務都被提交(commit),那么這些修改就永久地保存下來;要么資料庫管理系統將放棄所作的所有修改,整個事務回滾(rollback)到最初狀態
事務的ACID屬性:
(1)原子性(Atomicity) 原子性是指事務是一個不可分割的作業單位,事務中的操作要么都發生,要么都不發生,
(2)一致性(Consistency) 事務必須使資料庫從一個一致性狀態變換到另外一個一致性狀態,
(3)隔離性(Isolation) 事務的隔離性是指一個事務的執行不能被其他事務干擾,即一個事務內部的操作及使用的資料對并發的其他事務是隔離的,并發執行的各個事務之間不能互相干擾,
(4)持久性(Durability) 持久性是指一個事務一旦被提交,它對資料庫中資料的改變就是永久性的,接下來的其他操作和資料庫故障不應該對其有任何影響
mysql默認是自動提交,執行一句就提交一句,
我想要手動提交事務:
(1)set autocommit=false;
接下來所有陳述句都必須手動提交,
commit; 或 rollback; 或發生例外;
直到我set autocommit=true;或重新連接,
否則它之后的陳述句全部都需要手動提交
(2)start transaction;
在自動提交模式下,單獨針對某一組sql開啟事務
一組sql陳述句
commit; 或 rollback;
資料庫的隔離級別
-
-
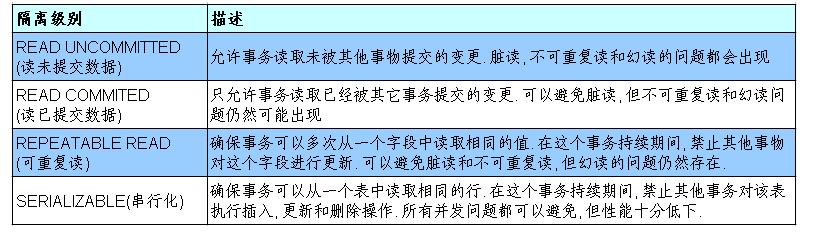
臟讀: 對于兩個事務 T1, T2, T1 讀取了已經被 T2 更新但還沒有被提交的欄位, 之后, 若 T2 回滾, T1讀取的內容就是臨時且無效的,
-
不可重復讀: 對于兩個事務T1, T2, T1 讀取了一個欄位, 然后 T2 更新了該欄位, 之后, T1再次讀取同一個欄位, 值就不同了,
-
幻讀: 對于兩個事務T1, T2, T1 從一個表中讀取了一個欄位, 然后 T2 在該表中插入了一些新的行, 之后, 如果 T1 再次讀取同一個表, 就會多出幾行,
-
-
資料庫事務的隔離性:資料庫系統必須具有隔離并發運行各個事務的能力, 使它們不會相互影響, 避免各種并發問題,
-
一個事務與其他事務隔離的程度稱為隔離級別,資料庫規定了多種事務隔離級別, 不同隔離級別對應不同的干擾程度, 隔離級別越高, 資料一致性就越好, 但并發性越弱,
Oracle 支持的 2 種事務隔離級別:READ COMMITED, SERIALIZABLE, Oracle 默認的事務隔離級別為: READ COMMITED ,
Mysql 支持 4 種事務隔離級別, Mysql 默認的事務隔離級別為: REPEATABLE READ,在mysql中REPEATABLE READ的隔離級別也可以避免幻讀了,
在MySql中設定隔離級別
-
每啟動一個 mysql 程式, 就會獲得一個單獨的資料庫連接,每個資料庫連接都有一個全域變數 @@tx_isolation, 表示當前的事務隔離級別.
-
查看當前的隔離級別: SELECT @@tx_isolation;
-
查看全域的隔離級別: SELECT @@global.tx_isolation;
-
設定當前 mySQL 連接的隔離級別:
set tx_isolation ='repeatable-read';
-
設定資料庫系統的全域的隔離級別:
set global tx_isolation ='read-committed';
注意:這里的隔離級別中間是減號,不是下劃線,
用戶與權限
用戶登錄
(1)IP+用戶名作為身份驗證
(2)密碼
給每個用戶權限,4個權限級別:
(1)全域(2)資料庫(3)表(4)欄位
依次校驗權限,如果前面通過了,后面就不校驗了:
全域 > 資料庫 > 表 > 欄位
注意:root@localhost,這個用戶始終保留所有的全域權限,
查看賬戶權限:
show grants for user@host;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/90879.html
標籤:MySQL