資料庫優化是一個任重而道遠的任務,想要做優化必須深入理解資料庫的各種特性,在開發程序中我們經常會遇到一些原因很簡單但造成的后果卻很嚴重的疑難雜癥,這類問題往往還不容易定位,排查費時費力最后發現是一個很小的疏忽造成的,又或者是因為不了解某個技術特性產生的,
于資料庫層面,最常見的恐怕就是索引失效了,且一開始因為資料量小還不易被發現,但隨著業務的拓展資料量的提升,性能問題慢慢的就體現出來了,處理不及時還很容易造成雪球效應,最終導致資料庫卡死甚至癱瘓,造成索引失效的原因可能有很多種,相關技術博客已經有太多了,今天我要記錄的是隱式轉換造成的索引失效,
資料準備
首先使用存盤程序生成1000萬條測驗資料,
測驗表一共建立了7個欄位(包括主鍵),num1和num2保存的是和ID一樣的順序數字,其中num2是字串型別,
type1和type2保存的都是主鍵對5的取模,目的是模擬實際應用中常用類似type型別的資料,但是type2是沒有建立索引的,
str1和str2都是保存了一個20位長度的隨機字串,str1不能為NULL,str2允許為NULL,相應的生成測驗資料的時候我也會在str2欄位生產少量NULL值(每100條資料產生一個NULL值),
-- 創建測驗資料表
DROP TABLE IF EXISTS test1;
CREATE TABLE `test1` (
`id` int(11) NOT NULL,
`num1` int(11) NOT NULL DEFAULT '0',
`num2` varchar(11) NOT NULL DEFAULT '',
`type1` int(4) NOT NULL DEFAULT '0',
`type2` int(4) NOT NULL DEFAULT '0',
`str1` varchar(100) NOT NULL DEFAULT '',
`str2` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `num1` (`num1`),
KEY `num2` (`num2`),
KEY `type1` (`type1`),
KEY `str1` (`str1`),
KEY `str2` (`str2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 創建存盤程序
DROP PROCEDURE IF EXISTS pre_test1;
DELIMITER //
CREATE PROCEDURE `pre_test1`()
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
WHILE i < 10000000 DO
SET i = i + 1;
SET @str1 = SUBSTRING(MD5(RAND()),1,20);
-- 每100條資料str2產生一個null值
IF i % 100 = 0 THEN
SET @str2 = NULL;
ELSE
SET @str2 = @str1;
END IF;
INSERT INTO test1 (`id`, `num1`, `num2`,
`type1`, `type2`, `str1`, `str2`)
VALUES (CONCAT('', i), CONCAT('', i),
CONCAT('', i), i%5, i%5, @str1, @str2);
-- 事務優化,每一萬條資料提交一次事務
IF i % 10000 = 0 THEN
COMMIT;
END IF;
END WHILE;
END;
// DELIMITER ;
-- 執行存盤程序
CALL pre_test1();
資料量比較大,還涉及使用MD5生成隨機字串,所以速度有點慢,稍安勿躁,耐心等待即可,
1000萬條資料,我用了33分鐘才跑完(實際時間跟你電腦硬體配置有關),這里貼幾條生成的資料,大致長這樣,
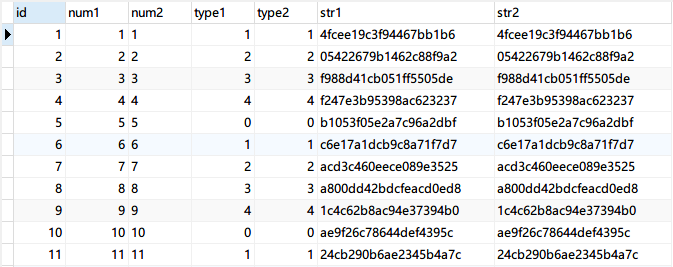
SQL測驗
首發地址:https://www.guitu18.com/post/2019/11/24/61.html
先來看這組SQL,一共四條,我們的測驗資料表num1是int型別,num2是varchar型別,但是存盤的資料都是跟主鍵id一樣的順序數字,兩個欄位都建立有索引,
1: SELECT * FROM `test1` WHERE num1 = 10000;
2: SELECT * FROM `test1` WHERE num1 = '10000';
3: SELECT * FROM `test1` WHERE num2 = 10000;
4: SELECT * FROM `test1` WHERE num2 = '10000';
這四條SQL都是有針對性寫的,12查詢的欄位是int型別,34查詢的欄位是varchar型別,12或34查詢的欄位雖然都相同,但是一個條件是數字,一個條件是用引號引起來的字串,這樣做有什么區別呢?先不看下邊的測驗結果你能猜出這四條SQL的效率順序嗎?
經測驗這四條SQL最后的執行結果卻相差很大,其中124三條SQL基本都是瞬間出結果,大概在0.001~0.005秒,在千萬級的資料量下這樣的結果可以判定這三條SQL性能基本沒差別了,但是第三條SQL,多次測驗耗時基本在4.5~4.8秒之間,
為什么34兩條SQL效率相差那么大,但是同樣做對比的12兩條SQL卻沒什么差別呢?查看一下執行計劃,下邊分別1234條SQL的執行計劃資料:

可以看到,124三條SQL都能使用到索引,連接型別都為ref,掃描行數都為1,所以效率非常高,再看看第三條SQL,沒有用上索引,所以為全表掃描,rows直接到達1000萬了,所以性能差別才那么大,
仔細觀察你會發現,34兩條SQL查詢的欄位num2是varchar型別的,查詢條件等號右邊加引號的第4條SQL是用到索引的,那么是查詢的資料型別和欄位資料型別不一致造成的嗎?如果是這樣那12兩條SQL查詢的欄位num1是int型別,但是第2條SQL查詢條件右邊加了引號為什么還能用上索引呢,
查閱MySQL相關檔案發現是隱式轉換造成的,看一下官方的描述:
官方檔案: 12.2 Type Conversion in Expression Evaluation
當運算子與不同型別的運算元一起使用時,會發生型別轉換以使運算元兼容,某些轉換是隱式發生的,例如,MySQL會根據需要自動將字串轉換為數字,反之亦然,以下規則描述了比較操作的轉換方式:
- 兩個引數至少有一個是
NULL時,比較的結果也是NULL,特殊的情況是使用<=>對兩個NULL做比較時會回傳1,這兩種情況都不需要做型別轉換- 兩個引數都是字串,會按照字串來比較,不做型別轉換
- 兩個引數都是整數,按照整數來比較,不做型別轉換
- 十六進制的值和非數字做比較時,會被當做二進制串
- 有一個引數是
TIMESTAMP或DATETIME,并且另外一個引數是常量,常量會被轉換為timestamp- 有一個引數是
decimal型別,如果另外一個引數是decimal或者整數,會將整數轉換為decimal后進行比較,如果另外一個引數是浮點數,則會把decimal轉換為浮點數進行比較- 所有其他情況下,兩個引數都會被轉換為浮點數再進行比較
根據官方檔案的描述,我們的第23兩條SQL都發生了隱式轉換,第2條SQL的查詢條件num1 = '10000',左邊是int型別右邊是字串,第3條SQL相反,那么根據官方轉換規則第7條,左右兩邊都會轉換為浮點數再進行比較,
先看第2條SQL:SELECT * FROM `test1` WHERE num1 = '10000'; 左邊為int型別10000,轉換為浮點數還是10000,右邊字串型別'10000',轉換為浮點數也是10000,兩邊的轉換結果都是唯一確定的,所以不影響使用索引,
第3條SQL:SELECT * FROM `test1` WHERE num2 = 10000; 左邊是字串型別'10000',轉浮點數為10000是唯一的,右邊int型別10000轉換結果也是唯一的,但是,因為左邊是檢索條件,'10000'轉到10000雖然是唯一,但是其他字串也可以轉換為10000,比如'10000a','010000','10000'等等都能轉為浮點數10000,這樣的情況下,是不能用到索引的,
關于這個隱式轉換我們可以通過查詢測驗驗證一下,先插入幾條資料,其中num2='10000a'、'010000'和'10000':
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000001', '10000', '10000a', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000002', '10000', '010000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000003', '10000', ' 10000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
然后使用第三條SQL陳述句SELECT * FROM `test1` WHERE num2 = 10000;進行查詢:
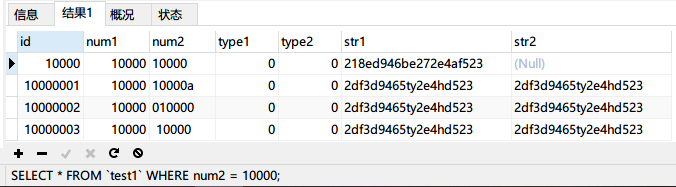
從結果可以看到,后面插入的三條資料也都匹配上了,那么這個字串隱式轉換的規則是什么呢?為什么num2='10000a'、'010000'和'10000'這三種情形都能匹配上呢?查閱相關資料發現規則如下:
- 不以數字開頭的字串都將轉換為
0,如'abc'、'a123bc'、'abc123'都會轉化為0; - 以數字開頭的字串轉換時會進行截取,從第一個字符截取到第一個非數字內容為止,比如
'123abc'會轉換為123,'012abc'會轉換為012也就是12,'5.3a66b78c'會轉換為5.3,其他同理,
現對以上規則做如下測驗驗證:

如此也就印證了之前的查詢結果了,
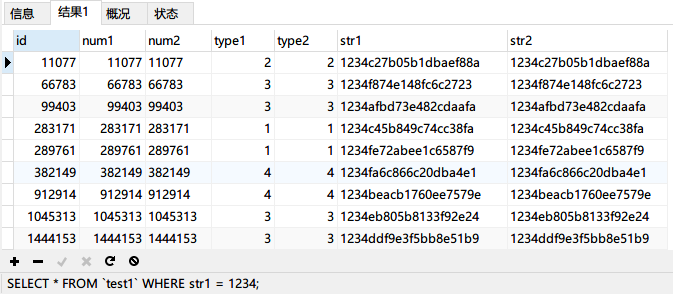
再次寫一條SQL查詢str1欄位:SELECT * FROM `test1` WHERE str1 = 1234;
分析和總結
通過上面的測驗我們發現MySQL使用運算子的一些特性:
- 當運算子左右兩邊的資料型別不一致時,會發生隱式轉換,
- 當where查詢運算子左邊為數值型別時發生了隱式轉換,那么對效率影響不大,但還是不推薦這么做,
- 當where查詢運算子左邊為字符型別時發生了隱式轉換,那么會導致索引失效,造成全表掃描效率極低,
- 字串轉換為數值型別時,非數字開頭的字串會轉化為
0,以數字開頭的字串會截取從第一個字符到第一個非數字內容為止的值為轉化結果,
所以,我們在寫SQL時一定要養成良好的習慣,查詢的欄位是什么型別,等號右邊的條件就寫成對應的型別,特別當查詢的欄位是字串時,等號右邊的條件一定要用引號引起來標明這是一個字串,否則會造成索引失效觸發全表掃描,
碼海無涯,不進則退,榷訓跬步,以至千里,本博客所寫內容僅為個人在學習和研究MySQL程序中的一些心得體會及總結筆記,僅代表個人觀點,本次測驗使用的MySQL版本是 5.7.26,隨著MySQL版本的更新某些特性可能會發生改變,本文不代表所述觀點和結論于MySQL所有版本均準確無誤,版本差異請自行甄別,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/90897.html
標籤:MySQL
下一篇:MySQL卸載