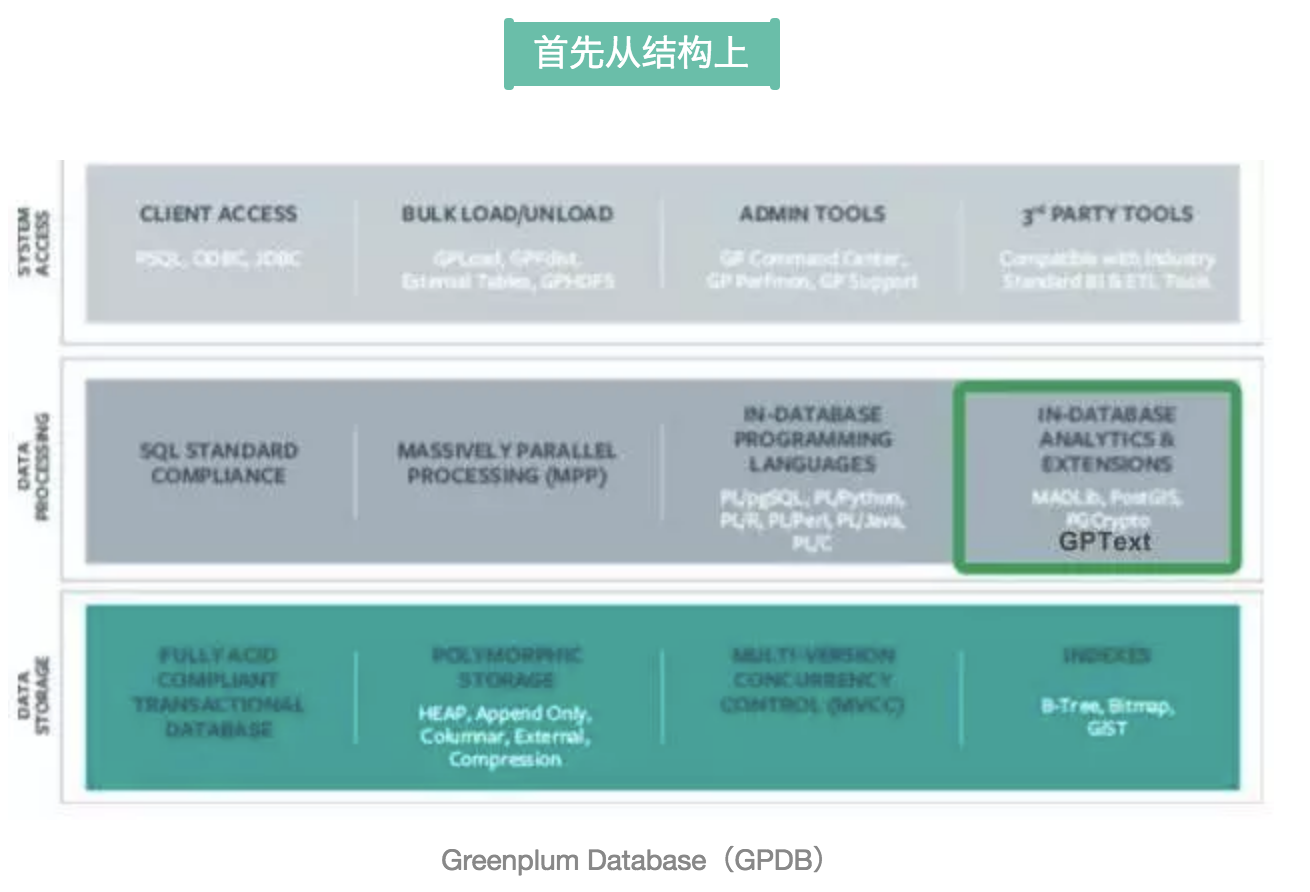
GPText是作為資料庫的文本分析的擴展。在資料庫里面,特別是GPDB是非常擅長于處理各種結構化的資料,MPP的方式可以高效地處理結構化資料。但是對于半結構化的或者是純文本的資料,它有搜索需求,這種處理就不是那么高效。在現有的GPDB里面,這種資料的處理我們可能需要經過全面掃描。當表的資料量比較大的話,全面掃描是非常費時的事情。
那我們怎么才能在毫秒級得到查詢的請求呢?比如可以從資料里面包含某個欄位或者包含當前一個名稱,把這些記錄給匯出來。所以我們做了GPText資料庫的擴展。
今天我們將和大家分享一篇來自Pivotal全球資料路演的技術強文 -- Pivotal GPText研發經理楊瑜介紹了如何使用Greenplum分析半結構化資料以及其原理,并通過一系列的案例演示讓演講內容更加生動豐富。同時還分享了開發和release的流程以及近期和遠期的研發計劃。
uj5u.com熱心網友回復:
請問,有沒有應用實體呢?gptext.search中的search_query這個引數有點沒用明白。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/92403.html
標籤:Greenplum
上一篇:登錄頁面測驗案例
下一篇:Windows系統組件漏洞