概述&背景
MySQL一直被人詬病沒有實作HashJoin,最新發布的8.0.18已經帶上了這個功能,令人欣喜,有時候在想,MySQL為什么一直不支持HashJoin呢?我想可能是因為MySQL多用于簡單的OLTP場景,并且在互聯網應用居多,需求沒那么緊急,另一方面可能是因為以前完全靠社區,這種演進速度畢竟有限,Oracle收購MySQL后,MySQL的發版演進速度明顯加快了很多,
HashJoin本身演算法實作并不復雜,要說復雜,可能是優化器配套選擇執行計劃時,是否選擇HashJoin,選擇外表,內表可能更復雜一點,不管怎樣現在已經有了HashJoin,優化器在選擇Join演算法時又多了一個選擇,MySQL本著實用主義,相信這個功能增強也回應了一些質疑,有些功能不是沒有能力做好,而是有它的優先級,
在8.0.18之前,MySQL只支持NestLoopJoin演算法,最簡單的就是Simple NestLoop Join,MySQL針對這個演算法做了若干優化,實作了Block NestLoop Join,Index NestLoop Join和Batched Key Access等,有了這些優化,在一定程度上能緩解對HashJoin的迫切程度,下文會單獨拿一個章節講MySQL的這些Join優化,下面先講HashJoin,
Hash Join演算法
NestLoopJoin演算法簡單來說,就是雙重回圈,遍歷外表(驅動表),對于外表的每一行記錄,然后遍歷內表,然后判斷join條件是否符合,進而確定是否將記錄吐出給上一個執行節點,從演算法角度來說,這是一個M*N的復雜度,HashJoin是針對equal-join場景的優化,基本思想是,將外表資料load到記憶體,并建立hash表,這樣只需要遍歷一遍內表,就可以完成join操作,輸出匹配的記錄,如果資料能全部load到記憶體當然好,邏輯也簡單,一般稱這種join為CHJ(Classic Hash Join),之前MariaDB就已經實作了這種HashJoin演算法,如果資料不能全部load到記憶體,就需要分批load進記憶體,然后分批join,下面具體介紹這幾種join演算法的實作,
In-Memory Join(CHJ)
HashJoin一般包括兩個程序,創建hash表的build程序和探測hash表的probe程序,
1).build phase
遍歷外表,以join條件為key,查詢需要的列作為value創建hash表,這里涉及到一個選擇外表的依據,主要是評估參與join的兩個表(結果集)的大小來判斷,誰小就選擇誰,這樣有限的記憶體更容易放下hash表,
2).probe phase
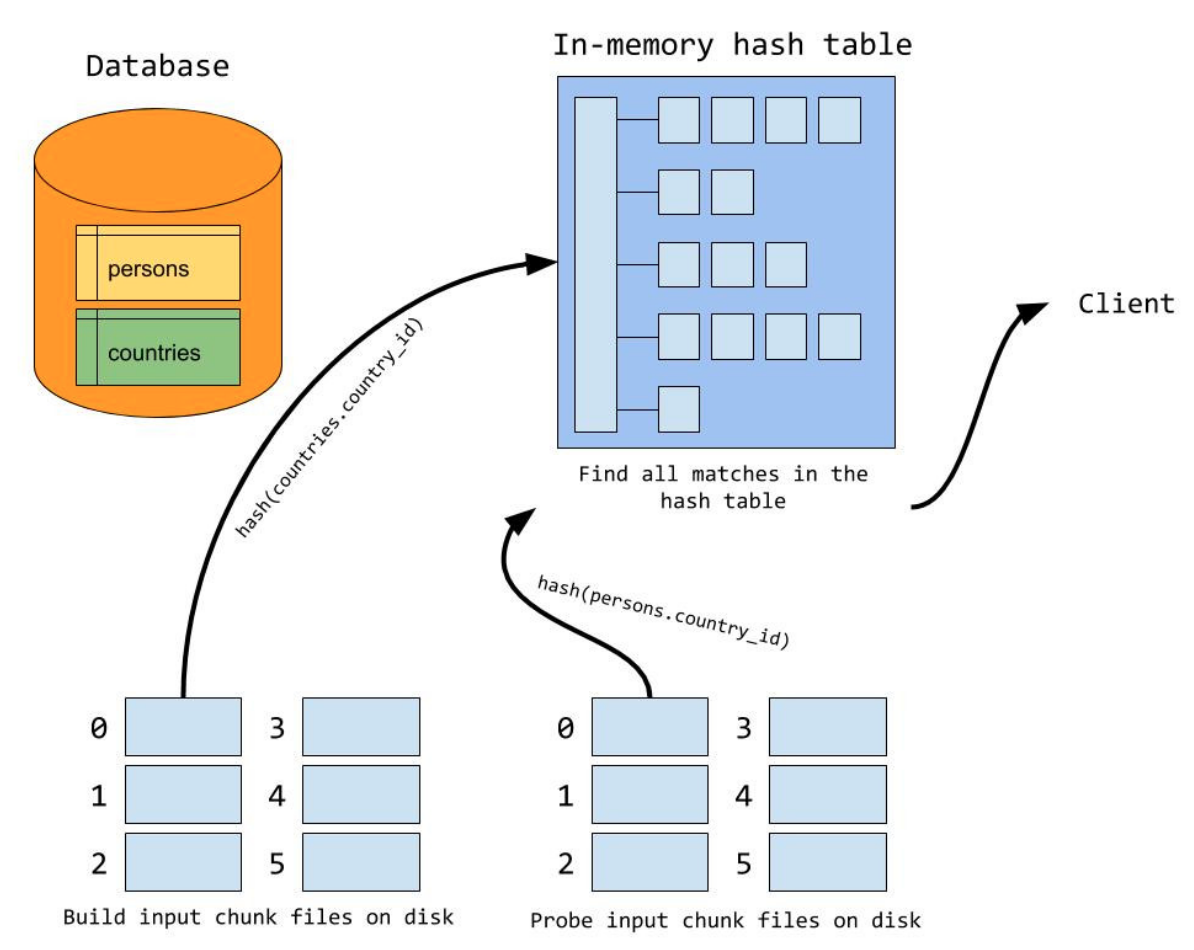
hash表build完成后,然后逐行遍歷內表,對于內表的每個記錄,對join條件計算hash值,并在hash表中查找,如果匹配,則輸出,否則跳過,所有內表記錄遍歷完,則整個程序就結束了,程序參照下圖,來源于MySQL官方博客
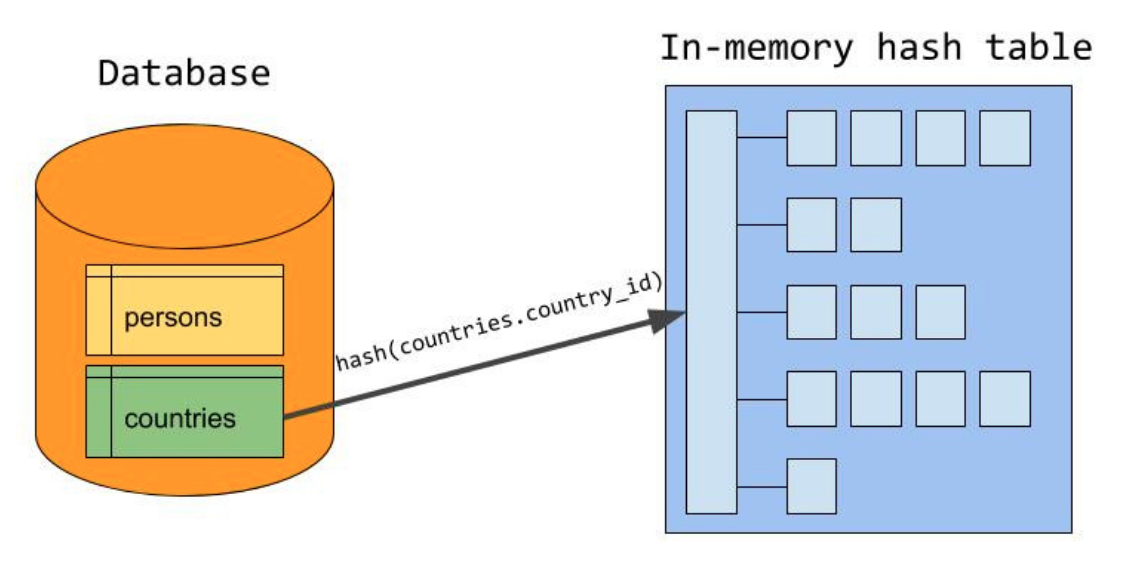
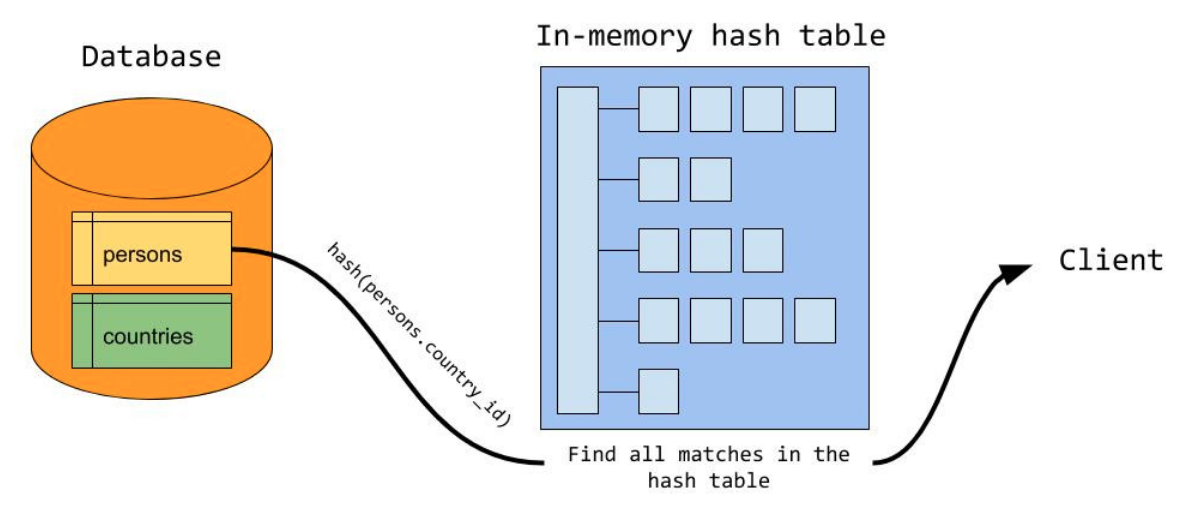
左側是build程序,右側是probe程序,country_id是equal_join條件,countries表是外表,persons表是內表,
On-Disk Hash Join
CHJ的限制條件在于,要求記憶體能裝下整個外表,在MySQL中,Join可以使用的記憶體通過引數join_buffer_size控制,如果join需要的記憶體超出了join_buffer_size,那么CHJ將無能為力,只能對外表分成若干段,每個分段逐一進行build程序,然后遍歷內表對每個分段再進行一次probe程序,假設外表分成了N片,那么將掃描內表N次,這種方式當然是比較弱的,在MySQL8.0中,如果join需要記憶體超過了join_buffer_size,build階段會首先利用hash算將外表進行磁區,并產生臨時分片寫到磁盤上;然后在probe階段,對于內表使用同樣的hash演算法進行磁區,由于使用分片hash函式相同,那么key相同(join條件相同)必然在同一個分片編號中,接下來,再對外表和內表中相同分片編號的資料進行CHJ的程序,所有分片的CHJ做完,整個join程序就結束了,這種演算法的代價是,對外表和內表分別進行了兩次讀IO,一次寫IO,相對于之之前需要N次掃描內表IO,現在的處理方式更好,
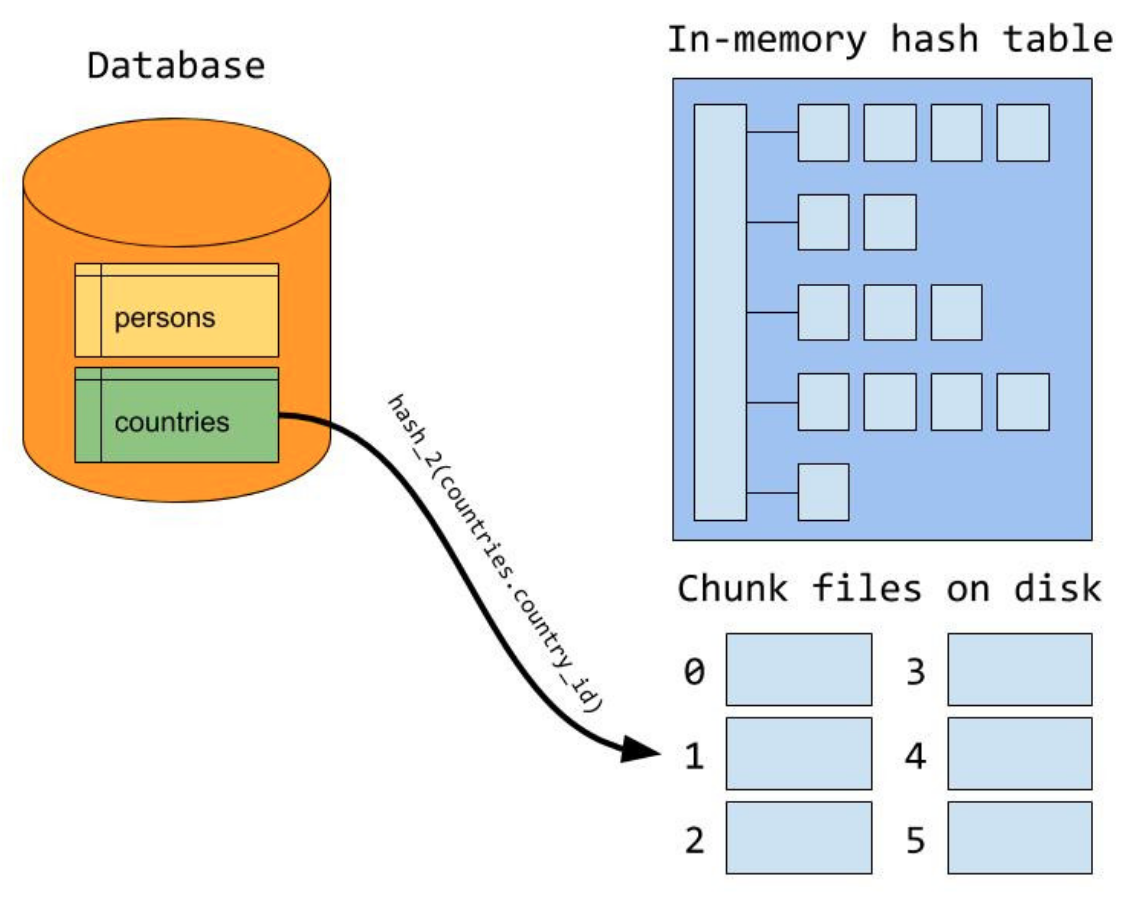
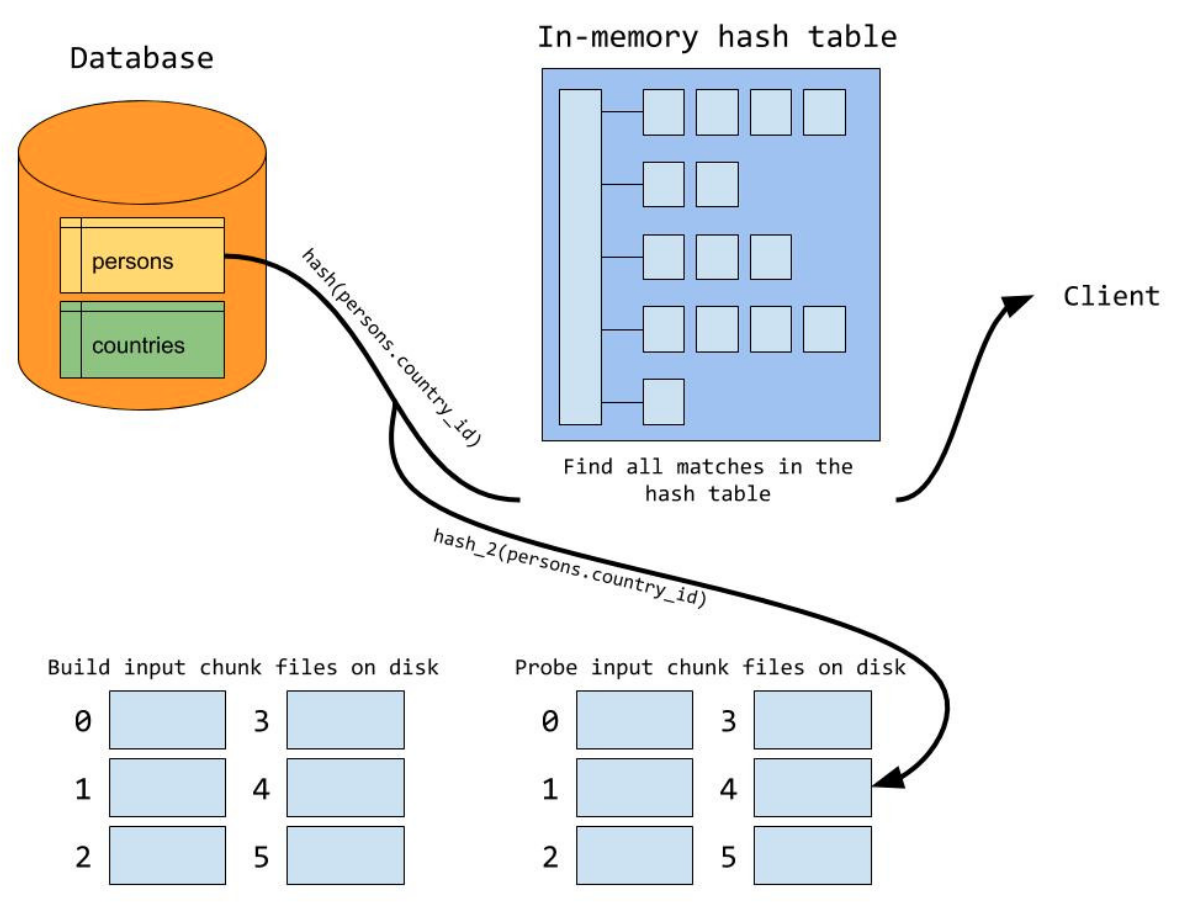
左上側圖是外表的分片程序,右上側圖是內表的分片程序,最下面的圖是對分片進行build+probe程序,
Grace Hash Join
主流的資料庫Oracle,SQLServer,PostgreSQL早就支持了HashJoin,Join演算法都類似,這里介紹下Oracle使用的Grace Hash Join演算法,其實整個程序與MySQL的HashJoin類似,主要有一點區別,當出現join_buffer_size不足時,MySQL會對外表進行分片,然后再進行CHJ程序,但是,極端情況下,如果資料分布不均勻,導致大量的資料hash后都分布在一個分桶中,導致分片后,join_buffer_size仍然不夠,MySQL的處理方式是一次讀分片讀若干記錄構建hash表,然后probe對應的外表分片,處理完一批后,清理hash表,重復上述程序,直到這個分片的所有資料處理完為止,這個程序與CHJ在join_buffer_size不足時,處理邏輯相同,
GraceHash在遇到這種情況時,會繼續分片進行二次Hash,直到記憶體足夠放下一個hash表為止,但是,這里仍然有極端情況,如果輸入join條件都相同,那么無論進行多少次Hash,都沒法分開,那么這個時候GraceHashJoin也退化成和MySQL的處理方式一樣,
hybrid hash join
與GraceHashJoin的區別在于,如果快取能快取足夠多的分片資料,會盡量快取,那么就不必像GraceHash那樣,嚴格地將所有分片都先讀進記憶體,然后寫到外存,然后再讀進記憶體去走build程序,這個是在記憶體相對于分片比較充裕的情況下的一種優化,目的是為了減少磁盤的讀寫IO,目前Oceanbase的HashJoin采用的是這種join方式,
MySQL-Join演算法優化
在MySQL8.0.18之前,也就是在很長一段時間內,MySQL資料庫并沒有HashJoin,主要的Join演算法是NestLoopJoin,SimpleNestLoopJoin顯然是很低效的,對內表需要進行N次全表掃描,實際復雜度是N*M,N是外表的記錄數目,M是記錄數,代表一次掃描內表的代價,為此,MySQL針對SimpleNestLoopJoin做了若干優化,下面貼的圖片均來自網路,
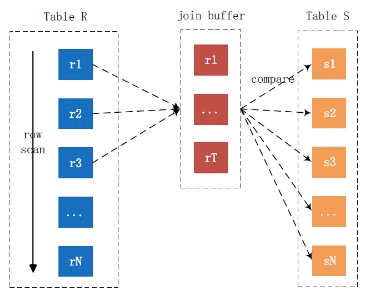
BlockNestLoopJoin(BNLJ)
MySQL采用了批量技術,即一次利用join_buffer_size快取足夠多的記錄,每次遍歷內表時,每條內表記錄與這一批資料進行條件判斷,這樣就減少了掃描內表的次數,如果內表比較大,間接就緩解了IO的讀壓力,
IndexNestLoopJoin(INLJ)
如果我們能對內表的join條件建立索引,那么對于外表的每條記錄,無需再進行全表掃描內表,只需要一次Btree-Lookup即可,整體時間復雜度降低為N*O(logM),對比HashJoin,對于外表每條記錄,HashJoin是一次HashTable的search,當然HashTable也有build時間,還需要處理記憶體不足的情況,不一定比INLJ好,
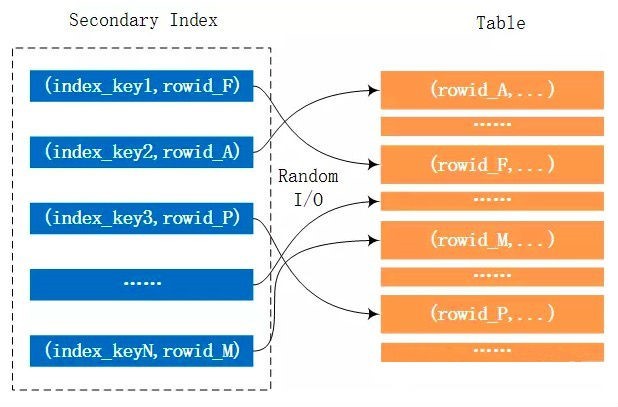
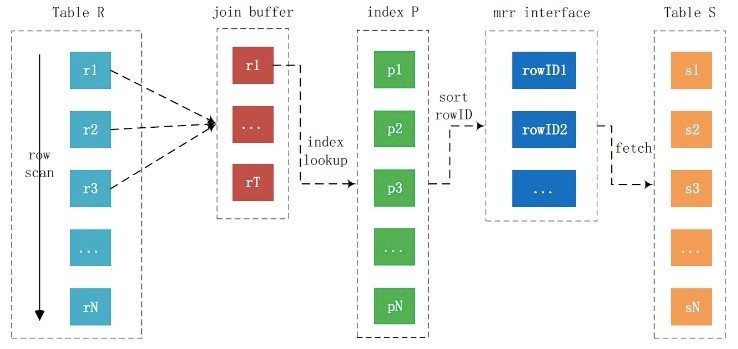
Batched Key Access
IndexNestLoopJoin利用join條件的索引,通過Btree-Lookup去匹配減少了遍歷內表的代價,如果join條件是非主鍵列,那么意味著大量的回表和隨機IO,BKA優化的做法是,將滿足條件的一批資料按主鍵排序,這樣回表時,從主鍵的角度來說就相對有序,緩解隨機IO的代價,BKA實際上是利用了MRR特性(MultiRangeRead),訪問資料之前,先將主鍵排序,然后再訪問,主鍵排序的快取大小通過引數read_rnd_buffer_size控制,
總結
MySQL8.0以后,Server層代碼做了大量的重構,雖然優化器相對于Oracle還有很大差距,但一直在進步,HashJoin的支持使得MySQL優化器有更多選擇,SQL的執行路徑也能做到更優,尤其是對于等值join的場景,雖然MySQL之前對于Join做過若干優化,比如NBLJ,INLJ以及BKA等,但這些代替不了HashJoin的作用,一個好用的資料庫就應該具備豐富的基礎能力,利用優化器分析出合適場景,然后拿出對應的基礎能力以最高效的方式回應請求,
參考檔案
https://en.wikipedia.org/wiki/Hash_join
https://mysqlserverteam.com/hash-join-in-mysql-8/
https://dev.mysql.com/worklog/task/?id=2241
https://www.cnblogs.com/qixinbo/p/10524142.html
https://zhuanlan.zhihu.com/p/35040231
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/99372.html
標籤:MySQL
上一篇:資料庫字符集US7ASCII,PB11如何顯示資料庫里的中文?
下一篇:MySQL資料庫備份和恢復