寫了一段代碼,總感覺出了問題,但是不知道哪里出了問題,代碼貼下
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define N 73 //葉子節點數
#define M 2*N-1 //樹中節點總數
#define MAXSIZE 20000
typedef struct
{
char data; //節點值
int weight; //權重
int parent; //雙親節點
int lchild; //左孩子節點
int rchild; //右孩子節點
}HTNode;
typedef struct
{
char cd[N]; //存放當前節點的哈夫曼編碼
int start; //cd[start]~cd[n]存放哈夫曼編碼
char data;
}HCode;
HCode hcd[N]; //存放哈夫曼編碼跟字符的結構體陣列
HTNode ht[M]; //存放哈夫曼樹
char string[10000];
int fileopen(char string[]) //讀入檔案
{
FILE *fp;
char *p = string;
fp = fopen("D:\\file1.txt", "r");
while (fgets(p, 1000, fp) != NULL); //輸出文章
printf("%s", string);
printf("\n");
fclose(fp);
return 0;
}
void CreateHT(HTNode ht[], int n) //構造哈夫曼樹
{
int i, k, lnode, rnode;
double min1, min2;
for (i = 0; i<2 * n - 1; i++) //所有節點的相關域置初值-1
ht[i].parent = ht[i].lchild = ht[i].rchild = -1;
for (i = n; i<2 * n - 1; i++)
{
min1 = min2 = 32767; //lnode和rnode為權值最小的兩個節點
lnode = rnode = -1; //只在尚未構造二叉樹的節點中找
for (k = 0; k<i - 1; k++)
if (ht[k].parent == -1)
{
if (ht[k].weight<min1)
{
min2 = min1; rnode = lnode;
min1 = ht[k].weight; lnode = k;
}
else if (ht[k].weight<min2)
{
min2 = ht[k].weight; rnode = k;
}
}
ht[lnode].parent = i; ht[rnode].parent = i;
ht[i].weight = ht[lnode].weight + ht[rnode].weight;
ht[i].lchild = lnode; ht[i].rchild = rnode; //ht[i]作為雙親節點
}
}
void CreateHCode(HTNode ht[], HCode hcd[], int n) //哈弗曼編碼
{
int i, f, c;
HCode hc;
for (i = 0; i<n; i++) //根據哈夫曼樹求哈弗曼編碼
{
hc.start = n; c = i;
f = ht[i].parent;
while (f != -1) //回圈直到無雙親節點即到達樹根節點為止
{
if (ht[f].lchild == c) //當前節點是其雙親節點的左孩子節點
hc.cd[hc.start--] = '0';
else //當前節點是其雙親節點的右孩子節點
hc.cd[hc.start--] = '1';
c = f;
f = ht[f].parent; //再對其雙親節點進行同樣的操作
}
hc.start++; //start指向哈弗曼編碼的開始字符
hc.data = ht[i].data;
hcd[i] = hc;
}
printf("\n");
}
void createht(HTNode ha[]) //錄入可能出現的字符
{
int i = 0;
char ch;
ha[i].data = ' '; i++; //每個字符有對應的一個i值
ha[i].data = ','; i++;
ha[i].data = '.'; i++;
ha[i].data = '('; i++;
ha[i].data = ')'; i++;
ha[i].data = '?'; i++;
ha[i].data = '"'; i++;
ha[i].data = '\''; i++;
ha[i].data = '!'; i++;
ha[i].data = ':'; i++;
ha[i].data = ';'; i++;
for (ch = '0'; ch <= '9'; ch++) {
ha[i].data = ch;
i++;
}
for (ch = 'A'; ch <= 'Z'; ch++) {
ha[i].data = ch;
i++;
}
for (ch = 'a'; ch <= 'z'; ch++) {
ha[i].data = ch;
i++;
}
for (i = 0; i<N; i++) //每個字符權重初始值賦為0
ha[i].weight = 0;
}
void Sumdata(HTNode ha[], int &n, char *string) //統計每個字符出現的頻度
{
char *p = string; //指標p指向文章中的字符
int i, k = 0;
while (*p != '\0')
{
for (i = 0; i<N; i++)
if (*p == ha[i].data) //每掃過一個字符,該字符權值加1
{
ha[i].weight++;
break;
}
p++; //指向下一個
}
printf("文章中出現的每個字符的個數如下:\n");
for (i = 0; i<N; i++) //當字符頻度不為0時,輸出該字符的頻度
if (ha[i].weight != 0)
{
printf("%c--%d\t", ha[i].data, ha[i].weight);
ht[k].data = ha[i].data; k++;
}
n = k;
printf("\n");
}
void DispHCode(HTNode ht[], HCode hcd[], int n) //輸出每個字符對應的哈弗曼編碼
{
int i, k, j;
int num = 0;
FILE * fp; fp = fopen("DispHcode.txt", "w"); //檔案指標
printf(" 輸出哈夫曼編碼:\n");
for (i = 0; i<n; i++) { //逐個輸出字符對應的哈弗曼編碼
j = 0;
printf("\t\t%c:", ht[i].data); //輸出字符
fprintf(fp, "\t\t%c:", ht[i].data);
for (k = hcd[i].start; k <= n; k++) {
printf("%c", hcd[i].cd[k]); //輸出編碼
fprintf(fp, "%c", hcd[i].cd[k]);
j++;
}
}
fclose(fp);
}
void PrintfHCode(HTNode ht[], HCode hcd[], int n) //輸出整篇文章的哈弗曼編碼
{
FILE * fp, *fp1, *fp2;
char ch, string[MAXSIZE];
int i, j, k;
fp = fopen("D:\\file1.txt", "r");
fp1 = fopen("PrintfHCode.txt", "w");
fp2 = fopen("decode.txt", "w");
for (i = 0; (ch = fgetc(fp)) != EOF; i++) //一個字符一個字符讀
{
string[i] = ch;
for (j = 0; j<n; j++) {
if (string[i] == ht[j].data) { //回圈查找與輸入字符相同的編號,相同的就輸出這個字符的編碼
for (k = hcd[j].start; k <= n; k++) {
printf("%c", hcd[j].cd[k]);
fprintf(fp1, "%c", hcd[j].cd[k]);//將hcd[j].cd[k]輸出到fp1中
fprintf(fp2, "%c", hcd[j].cd[k]);
}
printf(" ");
break;
}
}
}
fclose(fp);
fclose(fp1);
fclose(fp2);
}
void deHCode(HTNode ht[], HCode hcd[], int n) // 將編碼換成字符
{
char code[MAXSIZE], ch;
FILE *fp;
fp = fopen("decode.txt", "r"); //讀取檔案中的編碼
int i, j, k, m, x;
for (i = 0; (ch = fgetc(fp)) != EOF; i++) {
code[i] = ch;
}
while (code[0] != '\0')
for (i = 0; i<n; i++)
{
m = 0;
for (k = hcd[i].start, j = 0; k <= n; k++, j++) //與原生成的哈杜曼編碼進行比較
{
if (code[j] == hcd[i].cd[k])
m++;
}
if (m == j)
{
printf("%c", ht[i].data); //遇到相等時即取出對應的字符存入對應檔案中
for (x = 0; code[x - 1] != '\0'; x++)
{
code[x] = code[x + j];
}
}
}
fclose(fp);
}
void main() //主函式
{
char string[1000];
HTNode ha[N];
int x, n;
printf("\t\t\t********************************\n");
printf("\t\t\t***** 哈夫曼編碼 *****\n");
printf("\t\t\t********************************\n");
while (1)
{
printf("\n\t\t\t**【1】---------------輸入文章**");
printf("\n\t\t\t**【2】---------------統計頻度**");
printf("\n\t\t\t**【3】---------------字符編碼**");
printf("\n\t\t\t**【4】---------------文章編碼**");
printf("\n\t\t\t**【5】---------------文章譯碼**");
printf("\n\t\t\t**【6】---------------退 出**\n");
printf(" 請輸入選擇的編號:");
scanf("%d", &x);
switch (x) //定義switch()選擇分支結構
{
case 1:
printf("讀出文章為:\n");
fileopen(string);
break;
case 2:
createht(ha);
Sumdata(ha, n, string);
break;
case 3:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
DispHCode(ht, hcd, n);
break;
case 4:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
PrintfHCode(ht, hcd, n);
break;
case 5:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
deHCode(ht, hcd, n);
case 6:
exit(0);
default:
printf("輸入錯誤!\n");
}
}
}
測驗文章:
Education is very close in my heart. My father grew up in a very small village in China. In those days, not many villagers could read. So my father opened a night school to teach them how to read. With his help, many people learned to write their own names; with his help many people learned to read newspapers for the first time; with his help, many women were able to teach their children how to read. As his daughter, I know what education means to the people, especially those without it.
測驗結果:
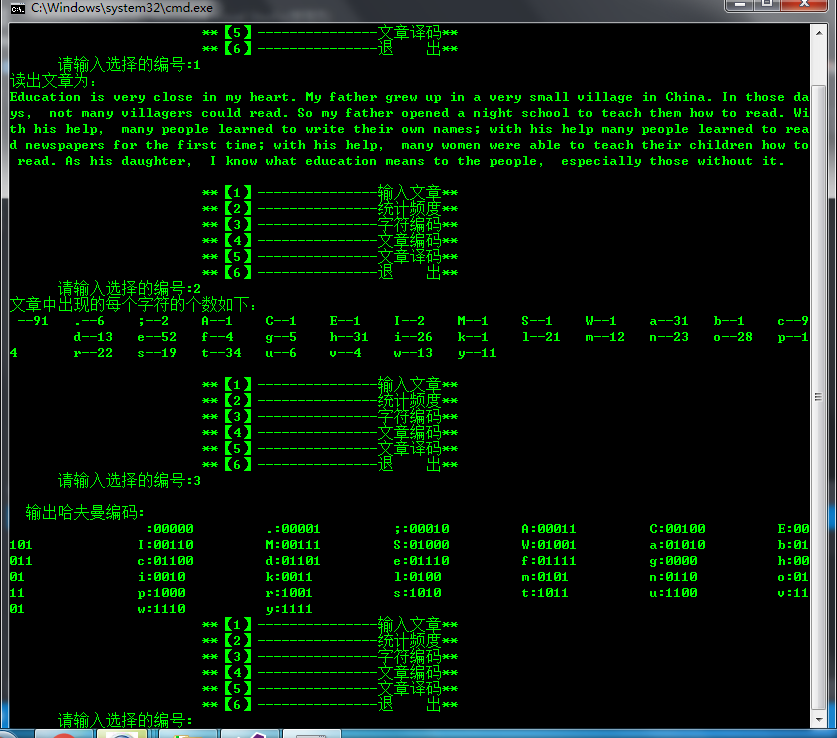
比如空格,頻度最高,但是編碼卻有點反常,不是很短,按照常理,頻度越高的編碼會越短
uj5u.com熱心網友回復:
如下修改
void Sumdata(HTNode ha[], int &n, char *text) //統計每個字符出現的頻度
{
char *p = text; //指標p指向文章中的字符
int i, k = 0;
while (*p != '\0')
{
for (i = 0; i<N; i++)
if (*p == ha[i].data) //每掃過一個字符,該字符權值加1
{
ha[i].weight++;
break;
}
p++; //指向下一個
}
printf("文章中出現的每個字符的個數如下:\n");
for (i = 0; i<N; i++) //當字符頻度不為0時,輸出該字符的頻度
if (ha[i].weight != 0)
{
printf("%c--%d\t", ha[i].data, ha[i].weight);
ht[k].data = ha[i].data;
ht[k].weight = ha[i].weight; //-----------------------------------------
k++;
}
n = k;
printf("\n");
}
結果為:
輸出哈夫曼編碼:
:11 ,:001110 .:101001 A:10100000 C:10100001 E:10100010 I:10101111 M:10100011 S:10101100 a:001 b:10101101 c:10001 d:00101 e:010 f:100000 g:101010 h:010 i:0110 k:10101110 l:1011 m:00110 n:0001 o:0111 p:0001 r:0000 s:1001 t:011 u:001111 v:100001 w:0000 y:00100
uj5u.com熱心網友回復:
譯碼還是錯誤的啊 好Sumdata 還是有問題 我想了一早上也沒想出來。uj5u.com熱心網友回復:
百度搜 霍夫曼 c++ 很多
uj5u.com熱心網友回復:
這個不是想的問題, 需要你自己去除錯, 還有其他比較多的問題deHCode 這個有個死回圈, CreateHCode 這個的cd最好初始化, 方便后面判斷
比較關鍵的錯誤在CreateHT, 這個遍歷時少處理了一個元素
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define printf ATLTRACE
#define scanf NDlg::InputScanf
#define file_path "E:\\SVN\\ICT_Pc\\PjIct\\Config\\text.log"
#define N 73 //葉子節點數
#define M 2*N-1 //樹中節點總數
#define MAXSIZE 20000
typedef struct
{
char data; //節點值
int weight; //權重
int parent; //雙親節點
int lchild; //左孩子節點
int rchild; //右孩子節點
}HTNode;
typedef struct
{
char cd[N]; //存放當前節點的哈夫曼編碼
int start; //cd[start]~cd[n]存放哈夫曼編碼
char data;
}HCode;
HCode hcd[N]; //存放哈夫曼編碼跟字符的結構體陣列
HTNode ht[M]; //存放哈夫曼樹
char text[10000];
int fileopen(char text[]) //讀入檔案
{
FILE *fp;
char *p = text;
fp = fopen("E:\\SVN\\ICT_Pc\\PjIct\\Config\\text.log", "r");
while (fgets(p, 1000, fp) != NULL); //輸出文章
printf("%s", text);
printf("\n");
fclose(fp);
return 0;
}
void CreateHT(HTNode ht[], int n) //構造哈夫曼樹
{
int i, k, lnode, rnode;
double min1, min2;
for (i = 0; i<2 * n - 1; i++) //所有節點的相關域置初值-1
ht[i].parent = ht[i].lchild = ht[i].rchild = -1;
for (i = n; i<2 * n - 1; i++)
{
min1 = min2 = 32767; //lnode和rnode為權值最小的兩個節點
lnode = rnode = -1; //只在尚未構造二叉樹的節點中找
for (k = 0; k<i; k++)
if (ht[k].parent == -1)
{
if (ht[k].weight<min1)
{
min2 = min1; rnode = lnode;
min1 = ht[k].weight; lnode = k;
}
else if (ht[k].weight<min2)
{
min2 = ht[k].weight; rnode = k;
}
}
ht[lnode].parent = i; ht[rnode].parent = i;
ht[i].weight = ht[lnode].weight + ht[rnode].weight;
ht[i].lchild = lnode; ht[i].rchild = rnode; //ht[i]作為雙親節點;
}
}
void CreateHCode(HTNode ht[], HCode hcd[], int n) //哈弗曼編碼;
{
int i, f, c;
HCode hc;
for (i = 0; i<n; i++) //根據哈夫曼樹求哈弗曼編碼;
{
memset(&hc, 0, sizeof(hc));
hc.start = n; c = i;
f = ht[i].parent;
while (f != -1) //回圈直到無雙親節點即到達樹根節點為止;
{
if (ht[f].lchild == c) //當前節點是其雙親節點的左孩子節點;
hc.cd[hc.start--] = '0';
else if(ht[f].rchild == c) //當前節點是其雙親節點的右孩子節點;
hc.cd[hc.start--] = '1';
else
assert(0);
c = f;
f = ht[f].parent; //再對其雙親節點進行同樣的操作;
}
hc.start++; //start指向哈弗曼編碼的開始字符;
hc.data = ht[i].data;
hcd[i] = hc;
}
printf("\n");
}
void createht(HTNode ha[]) //錄入可能出現的字符
{
int i = 0;
char ch;
ha[i].data = ' '; i++; //每個字符有對應的一個i值
ha[i].data = ','; i++;
ha[i].data = '.'; i++;
ha[i].data = '('; i++;
ha[i].data = ')'; i++;
ha[i].data = '?'; i++;
ha[i].data = '"'; i++;
ha[i].data = '\''; i++;
ha[i].data = '!'; i++;
ha[i].data = ':'; i++;
ha[i].data = ';'; i++;
for (ch = '0'; ch <= '9'; ch++) {
ha[i].data = ch;
i++;
}
for (ch = 'A'; ch <= 'Z'; ch++) {
ha[i].data = ch;
i++;
}
for (ch = 'a'; ch <= 'z'; ch++) {
ha[i].data = ch;
i++;
}
for (i = 0; i<N; i++) //每個字符權重初始值賦為0
ha[i].weight = 0;
}
void Sumdata(HTNode ha[], int &n, char *text) //統計每個字符出現的頻度
{
char *p = text; //指標p指向文章中的字符
int i, k = 0;
while (*p != '\0')
{
for (i = 0; i<N; i++)
if (*p == ha[i].data) //每掃過一個字符,該字符權值加1
{
ha[i].weight++;
break;
}
p++; //指向下一個
}
printf("文章中出現的每個字符的個數如下:\n");
for (i = 0; i<N; i++) //當字符頻度不為0時,輸出該字符的頻度
if (ha[i].weight != 0)
{
printf("%c--%d\t", ha[i].data, ha[i].weight);
ht[k].data = ha[i].data;
ht[k].weight = ha[i].weight; //-----------------------------------------
k++;
}
n = k;
printf("\n");
}
void DispHCode(HTNode ht[], HCode hcd[], int n) //輸出每個字符對應的哈弗曼編碼
{
int i, k, j;
int num = 0;
FILE * fp; fp = fopen("v:\\DispHcode.txt", "w"); //檔案指標
printf(" 輸出哈夫曼編碼:\n");
for (i = 0; i<n; i++) { //逐個輸出字符對應的哈弗曼編碼
j = 0;
printf("\t\t%c:", ht[i].data); //輸出字符
fprintf(fp, "\t\t%c:", ht[i].data);
for (k = hcd[i].start; k <= n; k++) {
printf("%c", hcd[i].cd[k]); //輸出編碼
fprintf(fp, "%c", hcd[i].cd[k]);
j++;
}
}
fclose(fp);
}
void PrintfHCode(HTNode ht[], HCode hcd[], int n) //輸出整篇文章的哈弗曼編碼;
{
FILE * fp, *fp1, *fp2;
char ch, text[MAXSIZE];
int i, j, k;
fp = fopen(file_path, "r");
fp1 = fopen("v:\\PrintfHCode.txt", "w");
fp2 = fopen("v:\\decode.txt", "w");
for (i = 0; (ch = fgetc(fp)) != EOF; i++) //一個字符一個字符讀 ;
{
text[i] = ch;
for (j = 0; j<n; j++)
{
if (text[i] == ht[j].data)
{
// 回圈查找與輸入字符相同的編號,相同的就輸出這個字符的編碼 ;
for (k = hcd[j].start; k <= n; k++)
{
printf("%c", hcd[j].cd[k]);
fprintf(fp1, "%c", hcd[j].cd[k]); //將hcd[j].cd[k]輸出到fp1中;
fprintf(fp2, "%c", hcd[j].cd[k]);
}
printf(" ");
break;
}
}
}
fclose(fp);
fclose(fp1);
fclose(fp2);
}
void deHCode(HTNode ht[], HCode hcd[], int n) // 將編碼換成字符;
{
char code[MAXSIZE], ch;
FILE *fp;
fp = fopen("v:\\decode.txt", "r"); //讀取檔案中的編碼;
int i, j, k, m, x;
for (i = 0; (ch = fgetc(fp)) != EOF; i++)
{
code[i] = ch;
}
code[i] = 0;
fclose(fp);
x=0;
while(code[x] != '\0')
{
for (i=0; i<n; i++)
{
for (k=hcd[i].start, j=0; k<=n; k++, j++) //與原生成的哈杜曼編碼進行比較;
{
if(code[x+j] != hcd[i].cd[k])
break;
}
if(hcd[i].cd[k] == 0)
break;
}
if (i>=n || hcd[i].cd[k])
break;
printf("%c", ht[i].data); //遇到相等時即取出對應的字符存入對應檔案中;
x += j;
}
}
void main_test() //主函式;
{
char text[1000];
HTNode ha[N];
int x, n;
printf("\t\t\t********************************\n");
printf("\t\t\t***** 哈夫曼編碼 *****\n");
printf("\t\t\t********************************\n");
fileopen(text);
createht(ha);
Sumdata(ha, n, text);
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
DispHCode(ht, hcd, n);
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
PrintfHCode(ht, hcd, n);
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
deHCode(ht, hcd, n);
return;
while (1)
{
printf("\n\t\t\t**【1】---------------輸入文章**");
printf("\n\t\t\t**【2】---------------統計頻度**");
printf("\n\t\t\t**【3】---------------字符編碼**");
printf("\n\t\t\t**【4】---------------文章編碼**");
printf("\n\t\t\t**【5】---------------文章譯碼**");
printf("\n\t\t\t**【6】---------------退 出**\n");
printf(" 請輸入選擇的編號:");;;;
scanf("%d", &x);
switch (x) //定義switch()選擇分支結構;
{
case 1:
printf("讀出文章為:\n");;;
fileopen(text);
break;
case 2:
createht(ha);
Sumdata(ha, n, text);
break;
case 3:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
DispHCode(ht, hcd, n);
break;
case 4:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
PrintfHCode(ht, hcd, n);
break;
case 5:
CreateHT(ht, n);
CreateHCode(ht, hcd, n);
deHCode(ht, hcd, n);
case 6:
return;
default:
printf("輸入錯誤!\n");
}
}
}
uj5u.com熱心網友回復:
這個是我花了4天改完了所有的但是還沒有寫完的代碼,不過已經解決了所有的問題,希望采納
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<conio.h>
#define N 80 //葉子結點的個數
#define M 2*N-1 //樹中節點的總個數
#define max 2000
typedef struct
{
char data; //節點值
int weight;
int parent,lchild,rchild;
}htnode,huffmantree[M+1];
////////////////////////////////////////////////////////////////////////////////////////////////////////////
typedef struct
{
char cd[N]; //存放當前節點的哈夫曼編碼
int start; //cd[start]~cd[n]存放哈夫曼編碼
char data;
}hcode;
typedef char* huffmantreecode[N+1];
////////////////////////////////////////////////////////////////////////////////////////////////////////////
htnode ht[M];
hcode hcd[N];
char string[1000];
//讀入檔案//////////////////////////////////////////////////////////////////////////////////////////////////
int fileopen(char string[])
{
FILE *fp;
char *p=string;
fp=fopen("C:\\Users\\Administrator\\Desktop\\file.txt","r"); //還可以改成name,即可隨意讀檔案
while(fgets(p,1000,fp)!=NULL);
printf("%s",string);
printf("\n"); //輸出文章
fclose(fp);
return 0;
}
/////////select函式////////////////////////////////////////////////////////////////////////////////////////
/*void select(huffmantree ht,int n,int *s1,int *s2)
{
int i,j;
int m1=max,m2=max;
for(j=1;j<=n;j++)
{
if(ht[j].weight<m1&&ht[j].parent==0)
{
m2=m1;
*s2=*s1;
m1=ht[j].weight;
}
else if(ht[j].weight<m2&&ht[j].parent==0)
{
m2=ht[j].weight;
*s2=j;
}
}
if(*s1>*s2)
{
i=*s1;
*s1=*s2;
*s2=i;
}
}
*/
//哈夫曼樹的建立 ////////////////////////////////////////////////////////////////////////////////////////
void greathuffmantree(htnode ht[],int n)
{
int i, k, lnode, rnode;
double min1, min2;
for (i = 0; i<2 * n - 1; i++) //所有節點的左孩子,右孩子,父親結點都置初值-1
ht[i].parent = ht[i].lchild = ht[i].rchild = -1;
for (i = n; i<2 * n - 1; i++)
{
min1 = min2 = max; //lnode和rnode為權值最小的兩個節點
lnode = rnode = -1; //只在尚未構造二叉樹的節點中找
for (k = 0; k<i - 1; k++)
if (ht[k].parent == -1)
{
if (ht[k].weight<min1)
{
min2 = min1; rnode = lnode;
min1 = ht[k].weight; lnode = k;
}
else if (ht[k].weight<min2)
{
min2 = ht[k].weight; rnode = k;
}
}
ht[lnode].parent = i; ht[rnode].parent = i;
ht[i].weight = ht[lnode].weight + ht[rnode].weight;
ht[i].lchild = lnode; ht[i].rchild = rnode; //ht[i]作為雙親節點
}
}
//哈夫曼編碼//////////////////////////////////////////////////////////////////////////////////////////////
void crthuffmantreecode(htnode ht[],hcode hcd[],int n)
//從葉子到根,求各葉子結點的編碼
{
int i, f, c;
hcode hc;
for (i = 0; i<n; i++) //根據哈夫曼樹求哈弗曼編碼
{
hc.start = n; c = i;
f = ht[i].parent;
while (f != -1) //回圈直到無雙親節點即到達樹根節點為止
{
if (ht[f].lchild == c) //當前節點是其雙親節點的左孩子節點
hc.cd[hc.start--] = '0';
else //當前節點是其雙親節點的右孩子節點
hc.cd[hc.start--] = '1';
c = f;
f = ht[f].parent; //再對其雙親節點進行同樣的操作
}
hc.start++; //start指向哈弗曼編碼的開始字符
hc.data = ht[i].data;
hcd[i] = hc;
}
printf("\n");
}
//輸出每個字對應的哈夫曼編碼///////////////////////////////////////////////////////////////////////////////////////////////////////
void printcode(huffmantree ht,hcode hcd[],int n)
{
int i,k,j;
int num=0;
FILE * fp;fp=fopen("code.txt","w");
printf("哈夫曼編碼:\n");
for(i=0;i<n;i++)
{
j = 0;
printf("\t%c:", ht[i].data); //輸出字符
fprintf(fp,"\t%c:", ht[i].data);
for (k = hcd[i].start; k <= n; k++) {
printf("%c", hcd[i].cd[k]); //輸出編碼
fprintf(fp, "%c\n", hcd[i].cd[k]);
j++;
}
}
fclose(fp);
}
//錄入可能出現的字符//////////////////////////////////////////////////////////////////////////////////////////////////////////////
void weight(huffmantree ht)
{
int i = 0;
char ch;
ht[i].data = ' '; i++; //每個字符有對應的一個i值
ht[i].data = ','; i++;
ht[i].data = '.'; i++;
ht[i].data = '('; i++;
ht[i].data = ')'; i++;
ht[i].data = '?'; i++;
ht[i].data = '"'; i++;
ht[i].data = '\''; i++;
ht[i].data = '!'; i++;
ht[i].data = ':'; i++;
ht[i].data = ';'; i++;
for (ch = '0'; ch <= '9'; ch++) {
ht[i].data = ch;
i++;
}
for (ch = 'A'; ch <= 'Z'; ch++) {
ht[i].data = ch;
i++;
}
for (ch = 'a'; ch <= 'z'; ch++) {
ht[i].data = ch;
i++;
}
for (i = 0; i<N; i++)
{
ht[i].weight = 0;
}
}
//統計字符出現數量/////////////////////////////////////////////////////////////////////////////////////////////////////////////////
void sumdata(htnode ha[],int &n,char *string)
{
char *p = string;
int i, k = 0;
while (*p != '\0')
{
for (i = 0; i<N; i++)
if (*p == ha[i].data)
{
ha[i].weight++;
break;
}
p++;
}
printf("文章中出現的每個字符的個數如下:\n");
for (i = 0; i<N; i++)
if (ha[i].weight != 0)
{
printf("%c--%d\t", ha[i].data, ha[i].weight);
ht[k].data = ha[i].data;
ht[k].weight = ha[i].weight;
// printf("..%c..",ht[k].data) ;
k++;
}
n = k;
printf("\n");
}
void printallfile(htnode ht[],hcode hcd[],int n)
{
FILE * fp, *fp1, *fp2;
char ch, string[max];
int i, j, k;
fp = fopen("C:\\Users\\Administrator\\Desktop\\file.txt","r");
fp1 = fopen("PrintfHCode.txt", "w");
fp2 = fopen("decode.txt", "w");
for (i = 0; (ch = fgetc(fp)) != EOF; i++)
{
string[i] = ch;
for (j = 0; j<n; j++) {
if (string[i] == ht[j].data) {
for (k = hcd[j].start; k <= n; k++) {
// printf("%c", hcd[j].cd[k]);
fprintf(fp1, "%c", hcd[j].cd[k]);
fprintf(fp2, "%c", hcd[j].cd[k]);
// printf("..%c..",ht[k].data);
}
printf(" ");
break;
}
}
}
fclose(fp);
fclose(fp1);
fclose(fp2);
}
//譯碼////////////////////////////////////////////////////////////////////////////
void dehcode(huffmantree ht,hcode hcd[],int n)
{
char buffer,a[max];
int i=0,j,p,t;
FILE *infile,*recodefile;
infile=fopen("C:\\Users\\Administrator\\Desktop\\PrintfHCode.txt","rb");
//判斷檔案是否存在
fread((char *)&buffer,sizeof(char),1,infile);
a[i]=buffer;i++;
while(!feof(infile))
{
fread((char *)&buffer,sizeof(char),1,infile);
a[i]=buffer;
// printf("%c",buffer);buffer是正確的!
i++;
}
fclose(infile);
j=strlen(a);
recodefile=fopen("C:\\Users\\Administrator\\Desktop\\decode.txt","wt");
p=2*n-1;
// printf("%d",p); p的數值為63!!也就是說有63個結點
for(i=0;i<=j;i++)
{//printf("*%c* ",ht[i].data);// printf("%c",a[i]);
if(a[i]=='0')
p=ht[p].lchild;
else//if(a[i]=='1')
p=ht[p].rchild;
if(ht[p].lchild==-1&&ht[p].rchild==-1)
{
printf("%c",ht[p].data);
fwrite(&ht[p].data,sizeof(char),1,recodefile);
p=2*n-1;
}
}
fclose(recodefile);
}
//壓縮//////////////////////////////////////////////////////////////////////////////////////////////////////
void compress()
{
char filename[225],outputfile[225],buf[512];
unsigned char c;
char i,j,m,n,f;
htnode tmp;
long min1,pt1,flength;
FILE *ifp,*ofp;
printf("source filename:\n");
gets(filename);
ifp=fopen(filename,"rb");
if(ifp==NULL)
{
printf("spurce file open error!\n");
return;
}
printf("destination filename:\n");
gets(outputfile);
ofp=fopen(outputfile,"wb");
if(ofp==NULL)
{
printf("destination file open error!\n");
return;
}
flength=0;
while(!feof(ifp))
{
fread(&c,1,1,ifp);
ht[c].weight++;
flength++;
}
flength--;
ht[c].weight--;
for(i=0;i<512;i++)
{
if(ht[c].weight!=0)
ht[i].data=https://bbs.csdn.net/topics/(unsigned char)i;
else ht[i].data=https://bbs.csdn.net/topics/0;
ht[i].parent=-1;
ht[i].lchild=ht[i].rchild=-1;
}
for(i=0;i<256;i++)
{
for(j=i+1;j<256;j++)
{
if(ht[i].weight<ht[j].weight)
{
tmp=ht[i];
ht[i]=ht[j];
ht[j]=tmp;
}
}
}
for(i=0;i<256;i++)
if(ht[i].weight==0) break;
}
int main(void) //主函式
{
char string[1000];
htnode ha[M];
int x, n,w[1000];
huffmantreecode hc;
printf("\t//////////////// 哈夫曼編碼 //////////////////\n");
while (1)
{
printf("\n\t\t\t【1】---------------輸入文章");
printf("\n\t\t\t【2】---------------統計頻度");
printf("\n\t\t\t【3】---------------字符編碼");
printf("\n\t\t\t【4】---------------文章編碼");
printf("\n\t\t\t【5】---------------文章譯碼");
printf("\n\t\t\t【6】---------------文章壓縮");
printf("\n\t\t\t【7】---------------文章解壓");
printf("\n\t\t\t【8】---------------退 出\n");
printf(" 請輸入選擇的編號:");
scanf("%d", &x);
switch (x)
{
case 1:
printf("讀出文章為:\n");
fileopen(string);
break;
case 2:
weight(ha);
sumdata(ha, n, string);
break;
case 3:
greathuffmantree(ht,n);
crthuffmantreecode(ht,hcd,n);
printcode(ht,hcd,n);
break;
case 4:
printallfile(ht,hcd,n);
break;
case 5:
dehcode(ht,hcd,n);
// CreateHT(ht, n);
// CreateHCode(ht, hcd, n);
// deHCode(ht, hcd, n);
// case 6:
// exit(0);
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/113991.html
標籤:基礎類