9 月 19 日,CODING 和中國 DevOps 社區聯合舉辦的深圳第九屆 Meetup 在騰訊大廈 2 樓多功能圓滿結束,本次沙龍以 「DevOps 轉型與實踐」 為主題,4 位來自互聯網、金融、零售行業的知名世界 500 強企業技術大咖,在現場分享了他們對于 DevOps 轉型實踐的見解和經驗,80 多位觀眾與講師們也進行了深入的技術探討,共同探討在 DevOps 潮流下,企業可能面臨的新機遇和挑戰,

CODING 一直致力于讓所有開發者都能有機會傾聽最具前沿的 DevOps 技術分享,之后還會在全國各地舉辦一系列 DevOps 技術沙龍,在不同城市的小伙伴也無需擔心,我們屆時會提供線上直播平臺,讓異地的同學也能與導師無障礙交流,敬請期待!話不多說,本期為大家分享的是《DevOps 在 SEE 小電鋪的落地與實踐》——
背景介紹
SEE 小電鋪是微信生態內最大的小程式電商服務平臺,目前累計與 10000+ 自媒體合作開店,是微博、斗魚等平臺的官方電商 SaaS 服務商,以及抖音頭部渠道電商平臺,
SEE 小電鋪技術負責人馬志雄講述了在競爭激烈的電商行業背景下,SEE 小電鋪是如何引入業界優秀的 DevOps 實踐,打造了高效穩定的應用交付體系,幫助公司邁向云原生時代的,他主要圍繞落地的法則,分享了 SEE 小電鋪內 DevOps 實踐的目標、落地的原則和具體實踐,
引入 DevOps 實踐
在疫情期間, SEE 小電鋪的作業人員采取了遠程辦公模式,這對所有人的協作和效率提出了更高的要求,研發流程中出現的各種問題促使 SEE 小電鋪反思技術架構、研發流程、度量工具以及團隊文化如何能夠高質量地順暢交付用戶價值,
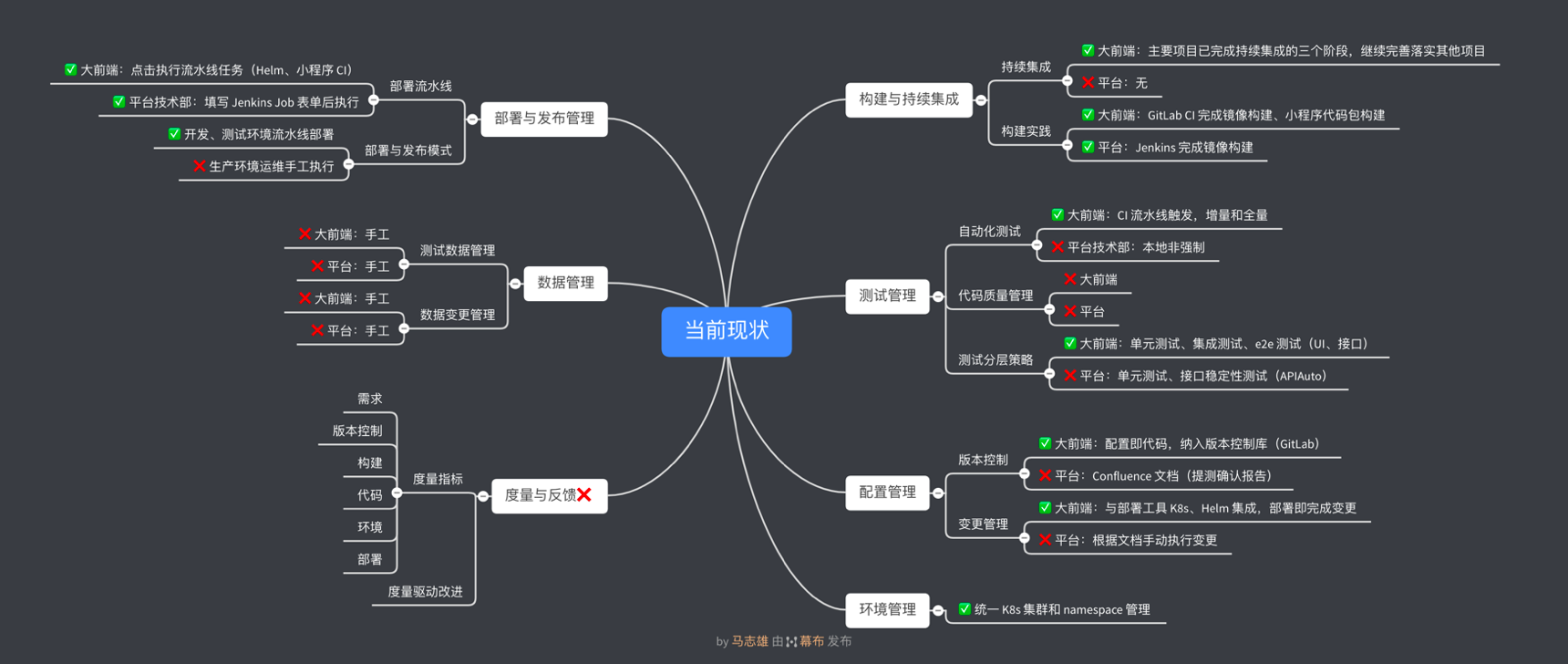
持續改革的第一步是識別問題,經過調研和討論,SEE 小電鋪首先引入了 DevOps 能力成熟度模型,對當前團隊里面存在的問題以及需要補齊的能力進行梳理,
SEE 小電鋪在組織支撐方面設立了 DevOps 作業小組,由工程效能團隊專項推進,把DevOps 具體事項納入 OKR 里進行目標管理,并拆解到相關的一線同事里面去,借此機會,團隊文化被重新塑造,作業小組不斷和一線同事講未來的技術方向是什么,為什么要去做這件事情,和所有人同步推進 DevOps 目標、方法和策略,在具體落地路徑上,灰度思維幫助優先主導推進那些對 DevOps 認同度比較高的同事,從比較容易改造并且能夠迅速看到成效的專案著手,
隨后,SEE 小電鋪制定了一期改進目標:
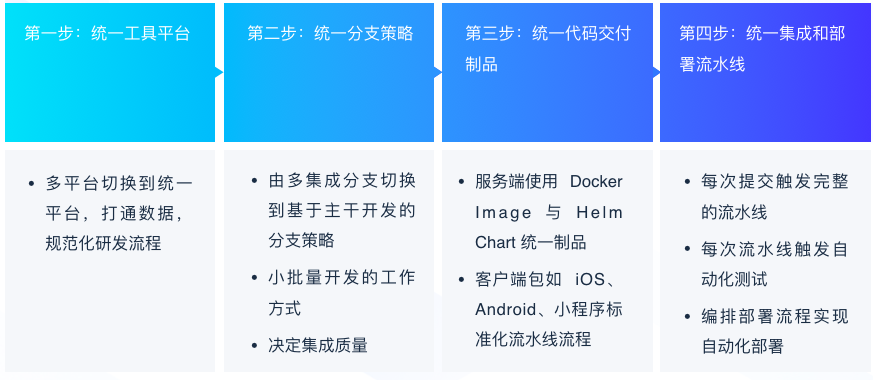
- 統一工具平臺
過去 SEE 小電鋪使用了繁多的工具,不僅有維護成本高等問題,在實際研發程序中的使用也不太順暢,舉個例子,部署還是依賴于人工 + 腳本的方式手動進行,在調研了市面上各種 DevOps 工具,最終 SEE 小電鋪選擇了 CODING DevOps 作為一站式研發平臺,主要的優勢體現在不需要跳轉多個產品,整個資料是打通互聯的,而且部署在國內,訪問速度好,中文支持度高,團隊成員上手也比較快,另外,持續部署是基于 Spinnaker,功能比較強大,和目前使用的騰訊云集成較好,測驗管理也無需單獨付費,整個維護無需自建維護,性價比高,
- 統一分支策略
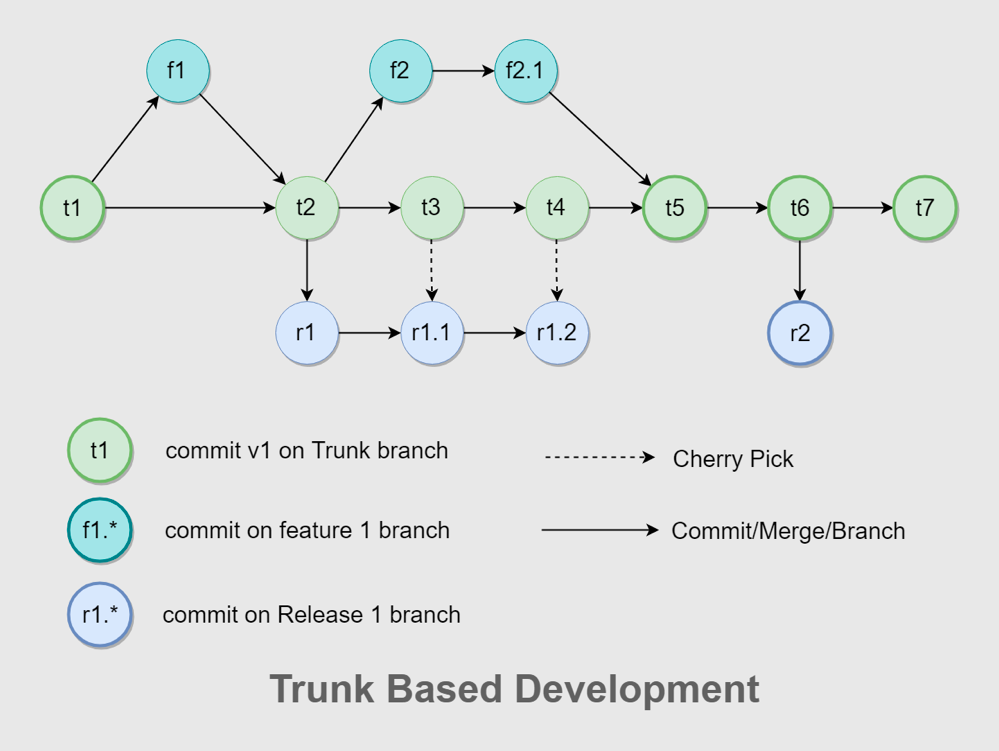
在工具切換之后,SEE 小電鋪面臨的一個困境是分支策略不統一,GitLab Flow 和 Git Flow 混合使用,整個流程非常復雜,容易出錯,合并也非常費時,多個版本并行時,GitLab Flow 需要配套多個環境,與持續集成的理念相違背,為了把研發效能提升到比較極致的狀態,SEE 小電鋪結合團隊自身的情況,決定采用有功能分支的主干開發策略,然后在團隊內部不斷地去講怎么用,包括怎么去更好地拆用戶故事和任務,怎么去做 git cherry-pick 和 rebase ,怎么去把 commit 設計得更加原子性等,
- 統一制品管理
SEE 小電鋪之前面臨的制品管理困境是應用的分發包是多種多樣的:整個系統在經過微服務進行改造以后,累計有四五十個服務需要進行維護,面臨著多應用集合管理和配置困難的問題;另外制品庫也是不統一的,缺乏統一的管控以及權限控制,在這種情況下,SEE 小店鋪使用了 Docker 和 Helm 來解決制品的統一性問題,Docker 鏡像能夠標準化交付元件, Helm 能夠幫助簡化 K8s 資源集合管理和配置,并且方便回滾和更新,制品庫則統一遷移到 CODING 制品庫來做制品托管,實作應用制品的單一來源管控以及細粒度的權限控制,
- 統一集成和部署流水線
經過多年的業務發展,SEE 小電鋪的應用數量非常多,缺乏體系化的流水線建設,少部分比較完善的專案工程使用 GitLab CI,還有一部分用 Jenkins 來做構建打包,大部分的應用還在使用 shell 腳本拉取 jar 包進行發布,已有的自動化部署耦合在 CI 里,環境與配置復雜以后難以維護,不夠規范且效率低容易出錯,因此 SEE 小電鋪首先制定了 CI 流水線的規范,包括根據不同的技術堆疊設計符合的流水線流程,根據分支模型和 MR 流程劃分全量集成和增量集成,以及各個流程的耗時標準;之后把工具統一切換到 CODING 支持的 Jenkins,做好構建節點的資源規劃,確保每次流水線都會觸發自動化測驗,包括代碼格式檢查,代碼規范和靜態分析,以及單元測驗、集成測驗和 E2E 測驗的自動化執行,最終執行的一個結果會通過企微機器人同步到專門的作業群,
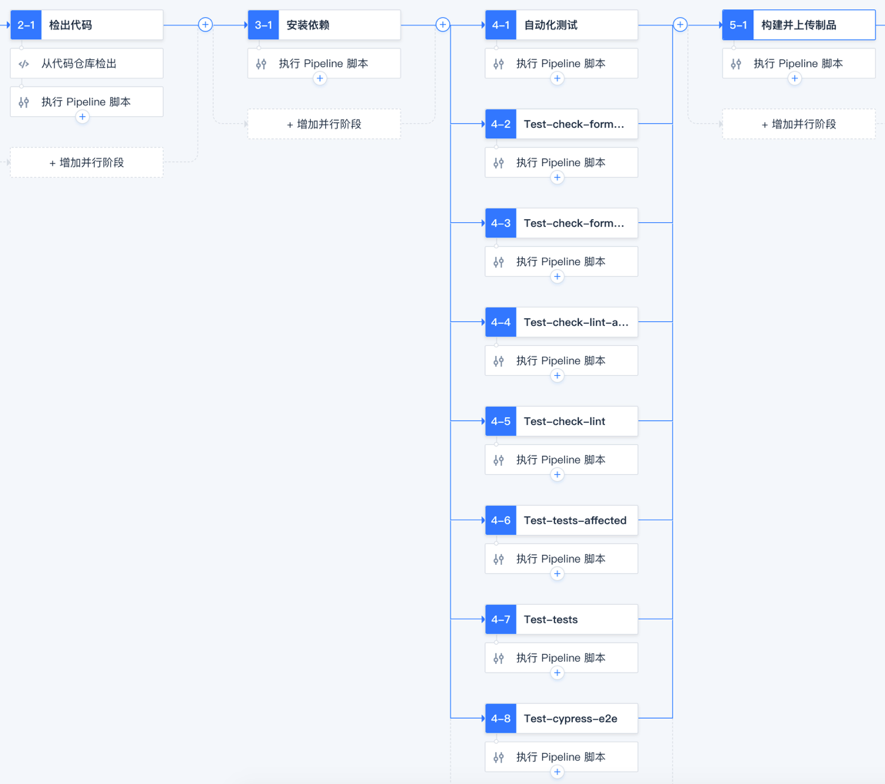
持續部署的流水線設計,主要是借助 Spinnaker 來進行編排,配置好 Bake 和部署流程,這里面的交付制品統一使用 Helm Chart,并且借助 CODING 的持續部署功能來進行發布單的管理,包括創建提單,并行部署,人工審批等,
云原生基礎架構
除了以上這四步以外,SEE 小電鋪的 DevOps 實踐還貫穿了很多其他理念,首先在基礎架構方面,SEE 小電鋪貫徹云原生的理念,把整個應用進行了 K8s 容器改造,直接使用騰訊云 TKE 產品來托管集群,幫助快速完成容器化改造,進行微服務和 BFF 架構風格下的高效容器編排,實作應用的標準化交付,確保資源隔離性和高效的利用率,并能保證環境的一致性,同時在面對流量潮汐時,也能夠基于 HPA 和 Cluster AutoScaler 實作 Pod 和節點靈活快速的擴縮容,從容應對業務的各種活動和大促,同時借助 K8s 的 Readiness Probe 和 Liveness Probe,能夠比較好地實作服務的自愈和容錯,在把 K8s 引入基礎架構以后,SEE 小電鋪通過引入服務網格技術 Service Mesh 實作了更加精細化的服務治理,通過 Istio 服務治理中核心的 Virtual Service 和 Destination Rules 這兩個 CRD 結合 CODING 的持續部署可以實作自動化灰度發布,取代原有的集群藍綠發布策略,把資源利用和流量控制做到一個相對比較極致的水平,并且把微服務架構里難以落地的服務治理固化成了一個標準的基礎設施,讓開發能夠更加關注應用本身,
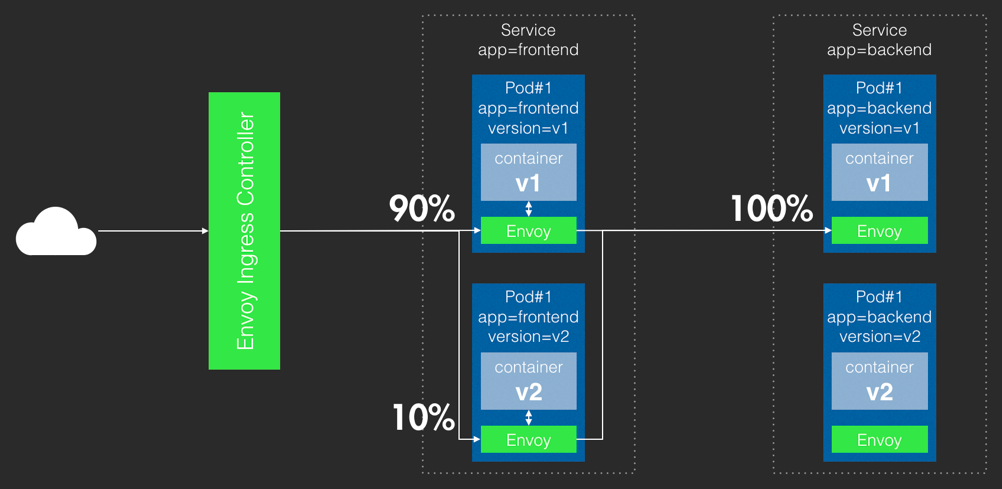
在上圖中,根據 Istio 里面的配置規則可以實作按百分比把 10% 的流量打到新的應用里,最終通過校驗以后可以把整個流量進行完全切換,實作精細化的流量轉移,
可靠性 & 可觀測性
SRE 方法論被 SEE 小電鋪引入指導可靠性建設,首先,SLO 可靠性建模包括三個維度:Availability 可用性、Latency 延遲和 Ticket 人工干預,這三個維度分別對前后端應用進行了白盒和黑盒監控指標采集,模型計算公式最終可以輸出整個服務指標,SRE 團隊基于此模型搭建了內部所有服務的可靠性看板,能夠實時對生產環境的服務可靠性指標進行查看和跟進,SRE 方法論中還有一個非常好的概念,就是錯誤預算,基于 SLO 的模型,可以計算出一段周期內錯誤預算消耗了多少,從而決定是否調整這個周期內的版本發布頻率以及節奏,比如說要維持 99.9% 的可靠性,那一個月內的不可用視窗期就是 43.2 分鐘,
可觀測性基于 EFK 日志平臺做了所有服務的日志收集與聚合,幫助做 K8s 改造后所有容器的收集;指標監控方面基于 Prometheus 和 Grafana 搭建了監控平臺,幫助進行發布盯盤和對 Pod 例外指標進行記錄和告警,
質量內建
質量內建方面,SEE 小電鋪遵循了一些 DevOps 社區內較為流行的原則來實施,首先是質量門禁,內部的指標所有單元測驗模塊覆寫率都必須大于 80%,老的系統也會在專案排期里面不斷補充完善,web、小程式、iOS、Android 和 React Native 等應用要求要有 100% 的 E2E 測驗來覆寫所有的應用場景,質量門禁還需要管控合并請求,開發的 MR 需要通過 CI 自動化測驗,CODING 遠程提供的代碼靜態掃描以及結對代碼 Review 以后才會被合并到主干,其次,CODING 的測驗管理成功將 SEE 小電鋪從原始的 Excel 管理測驗用例中解放出來,支持用例的在線評審并制定迭代的測驗計劃,DogFooding 自測允許在集成環境上進行冒煙測驗,通過測驗管理中的測驗計劃進行追蹤,并組織提測前的 demo 演示,
成果
在半年多的 DevOps 變革和實踐里,SEE 小電鋪實作了多項核心指標提升,單個服務部署時長從以前的數小時縮短到 5 分鐘,總的全量環境部署也從一兩個星期縮短到 1 個小時,開發 bug 率下降了 10 倍左右,調整迭代規劃以后,大概達到每周 2 次全量環境部署頻率,變更前置時間也縮短到 1 周以內,可用性也達到了 99.9%,更重要的是,團隊更加聚焦到了業務交付本身,
Q:Helm Chart 管理的資源很多,你們在這方面有沒有最佳實踐?
A:我們做了很粗暴的一刀切,前端的應用是公共的 Helm Chart,后端的應用是另外一個 Chart,各個服務作為 Chart 中的子應用,是 Chart 里面的其中一塊,在內部工程效能組規范化以后,所有的應用都是按照這個模板來做的,
Q:請問你們團隊是怎么保證發布后的質量的?
A:我們的可用性維持在 99.9% 左右,但難免還是會有泄露的 bug,我們要在業務創新和穩定性中取得權衡,這個權衡就是通過 SLO 的方式,我們通過確保整體的服務維持在 99.9% 的可靠性目標前提下,盡可能快地去發布我們的應用,
溫馨提示:
更多講師 PPT 及演講稿脫敏后將逐步更新
點擊開啟 CODING DevOps 云上研發作業流
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/164497.html
標籤:其他