一、背景
最近容器組在開發云平臺的監控、報警功能,
大致的實作策略是:
1、云平臺頁面上配置告警規則
2、Prometheus完成監控資料的聚合
3、當Prometheus聚合后的監控資料滿足告警規則,觸發釘釘告警
二、程序
1、告警規則配置,一般情況下,業務服務的服務型別為deployment,告警規則:Pod記憶體使用率大于50%
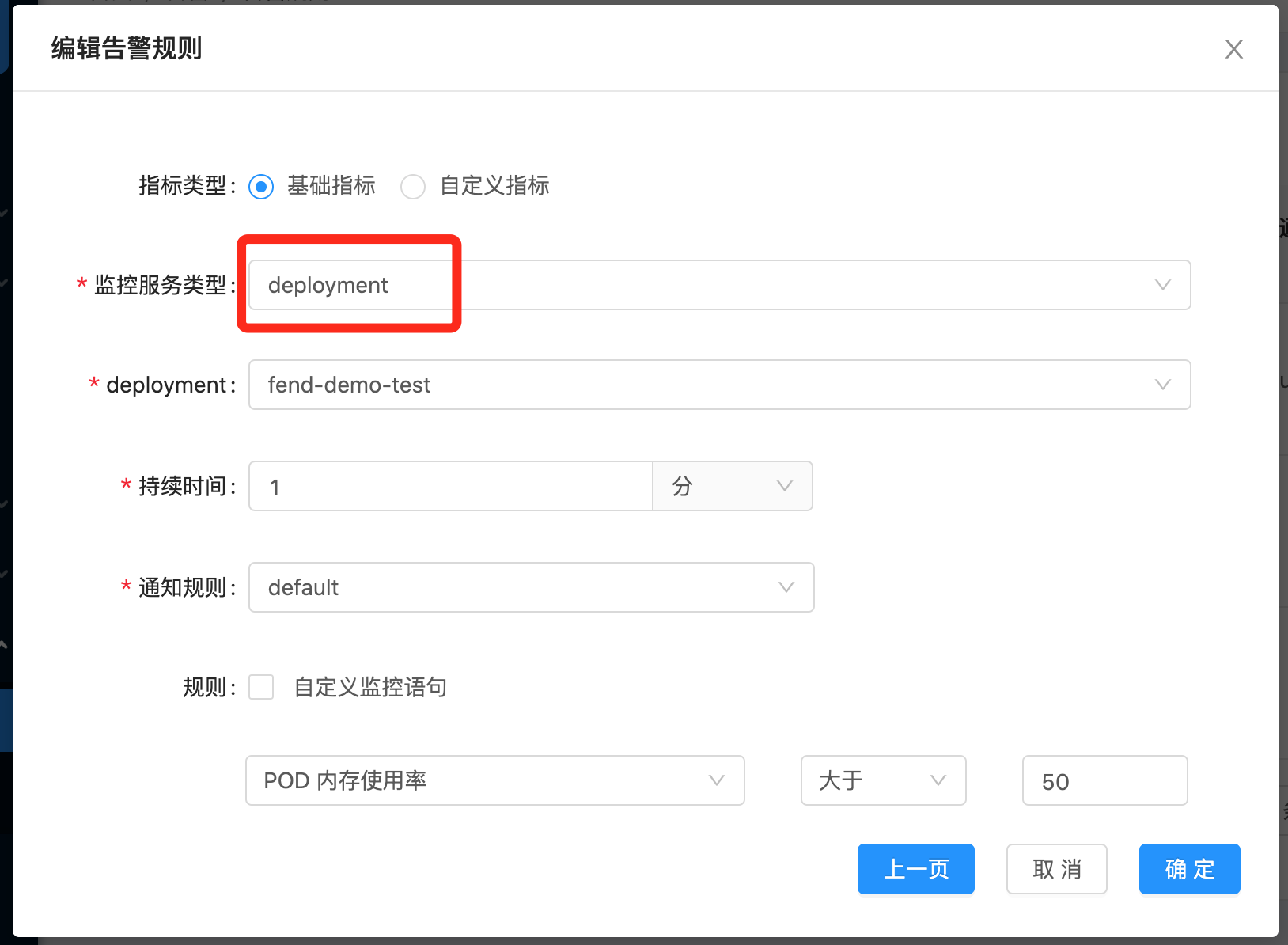
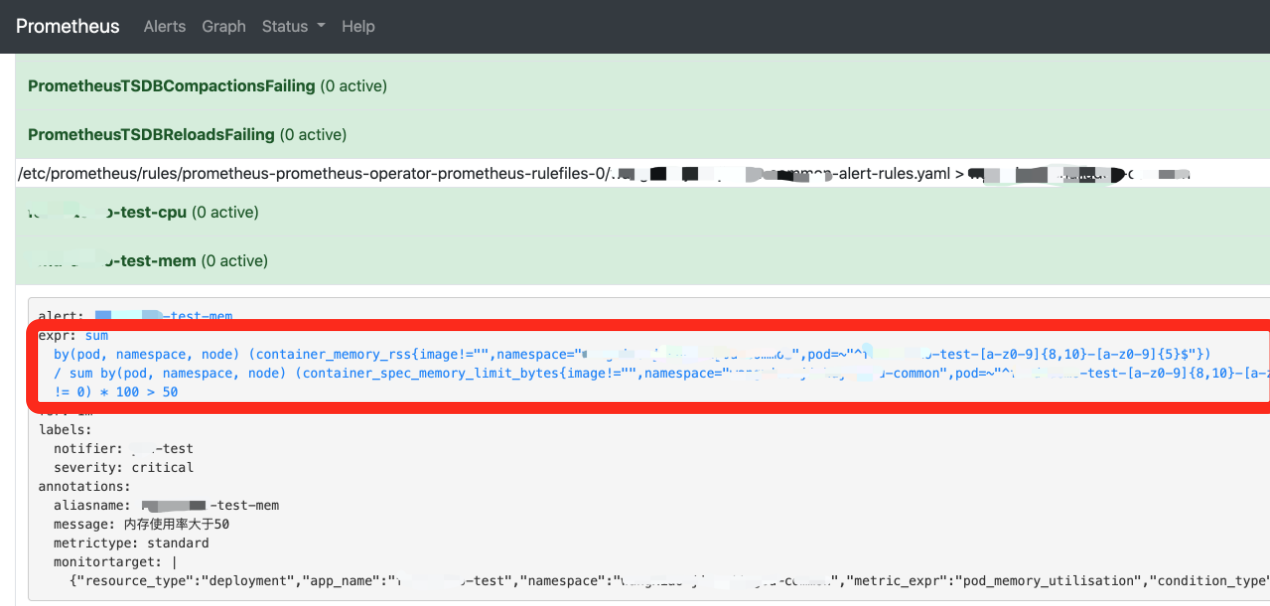
2、步驟1中創建告警規則時,會同步在Prometheus上創建一個相同規則的Alert任務
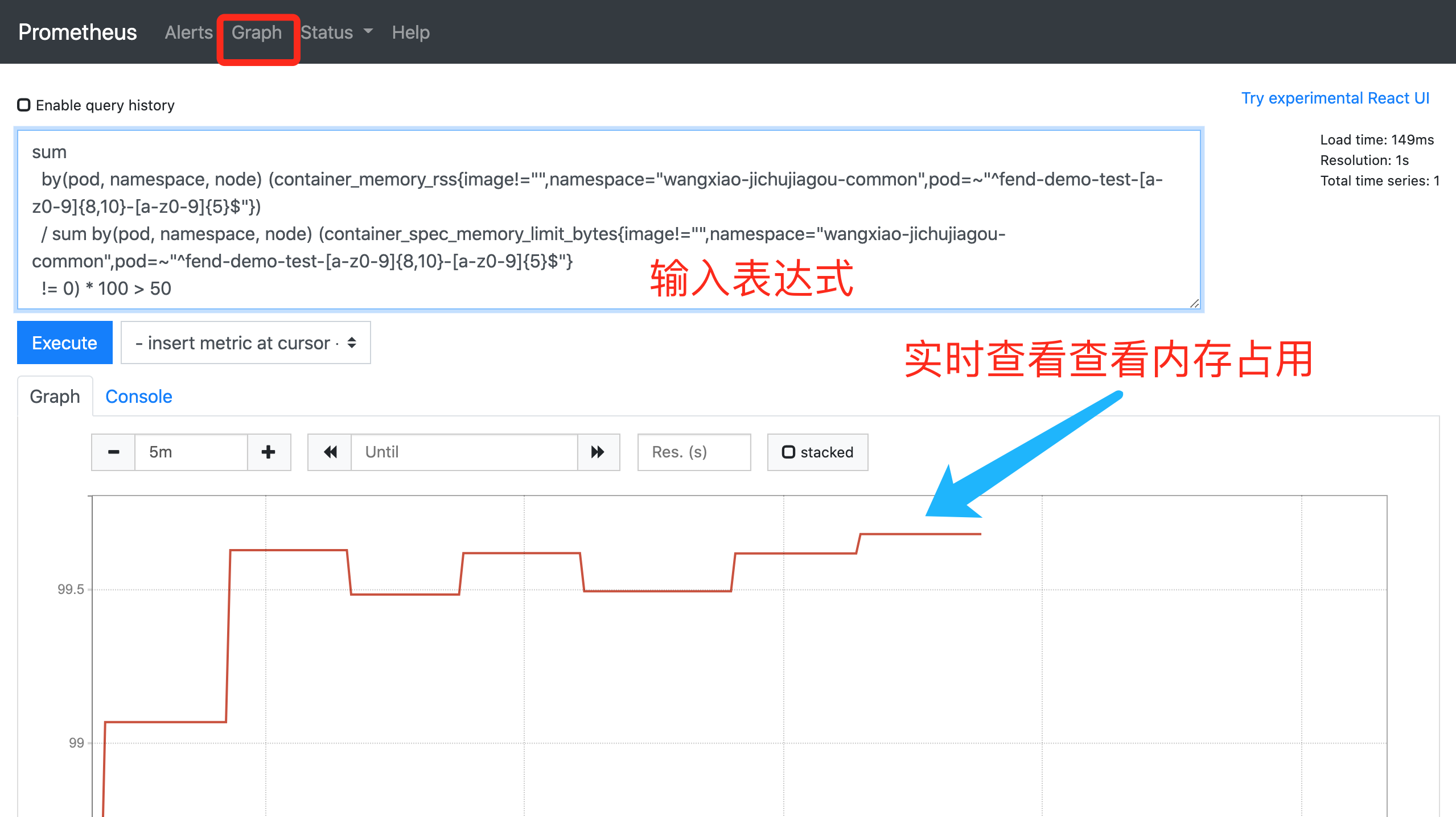
3、復制Alert任務的聚合運算式,可以在Graph中實時查看到記憶體的占用情況
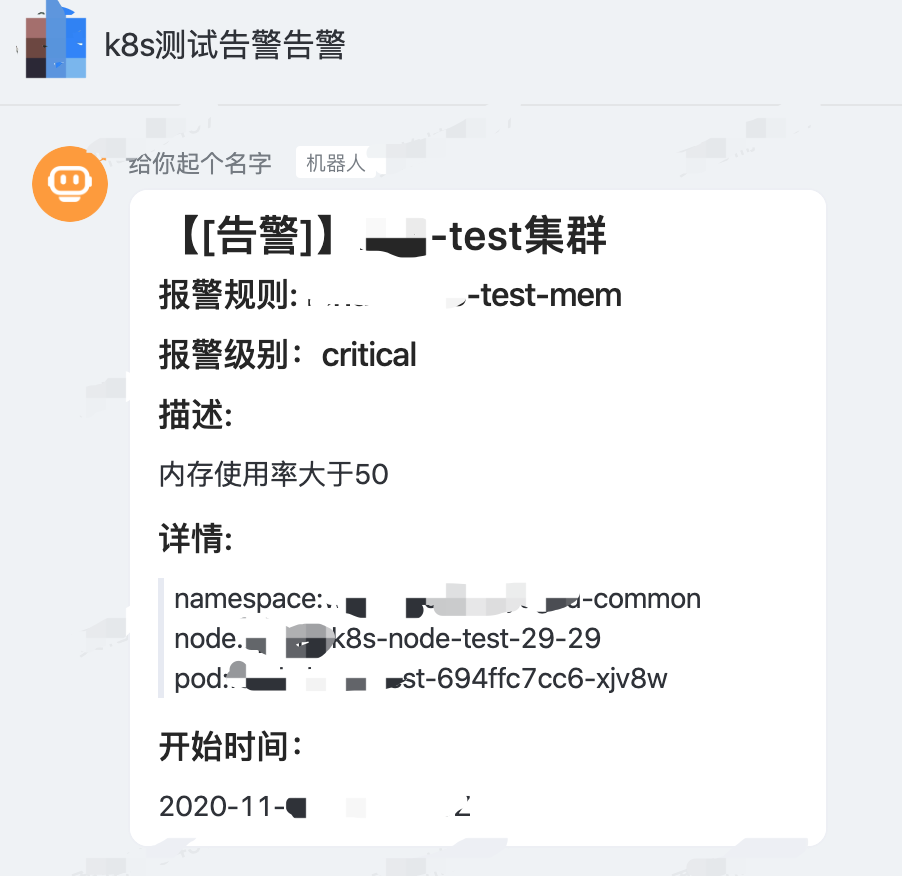
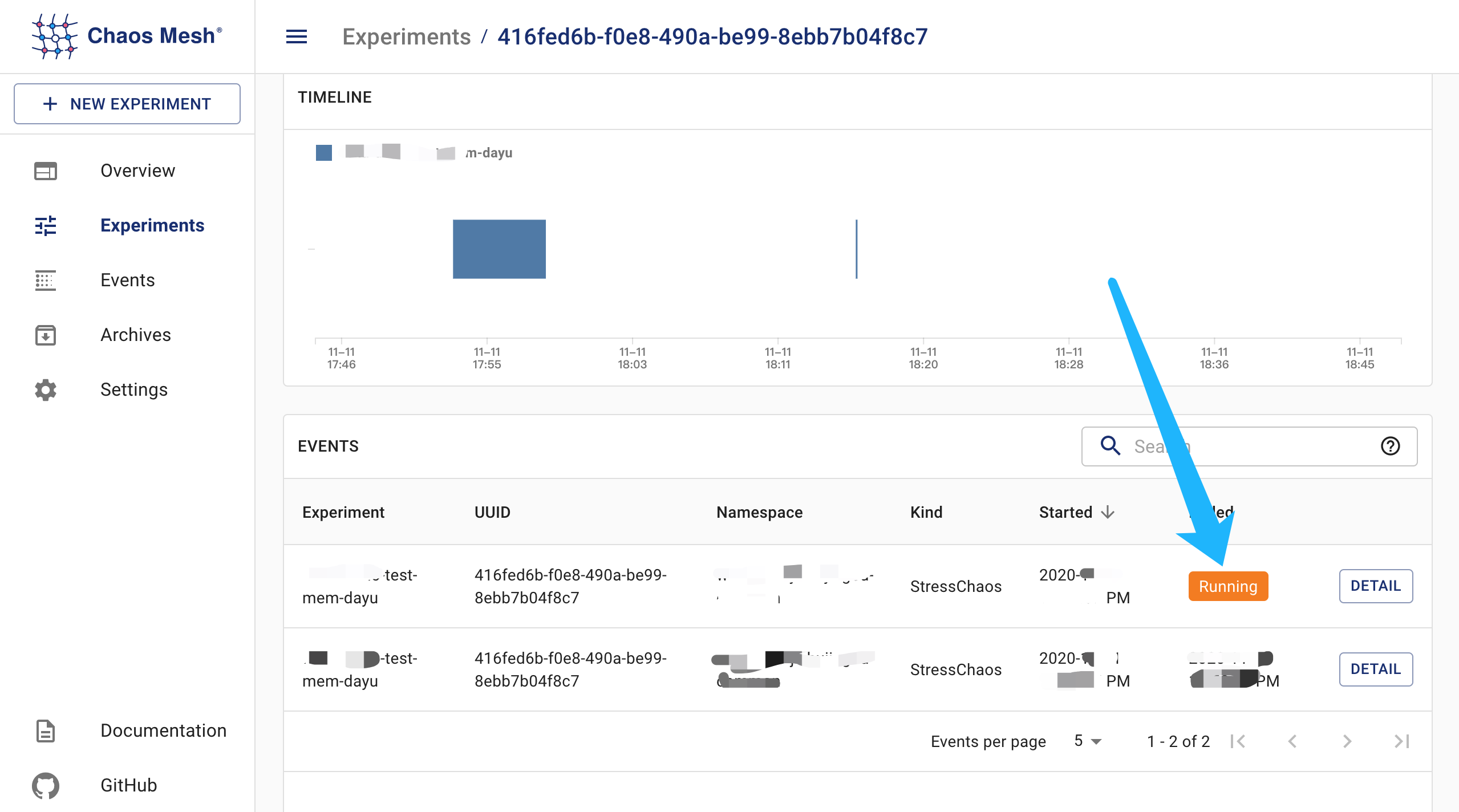
4、收到告警通知
三、Chaos Mesh
那么,是什么讓記憶體的占用突然增高到90%以上,從而能觸發告警條件的呢?(告警條件:Pod記憶體使用率大于50%)
Chaos Mesh登場了,
Chaos Mesh作為一個云原生的混沌工程平臺,提供在 Kubernetes 平臺上進行混沌測驗的能力,
Chaos Mesh包括針對Kubernetes上復雜系統的故障注入方法,并涵蓋了Pod,網路,檔案系統甚至內核中的故障,
Chaos Mesh功能很強大,這里只用到給Pod注入記憶體占用,
步驟如下:
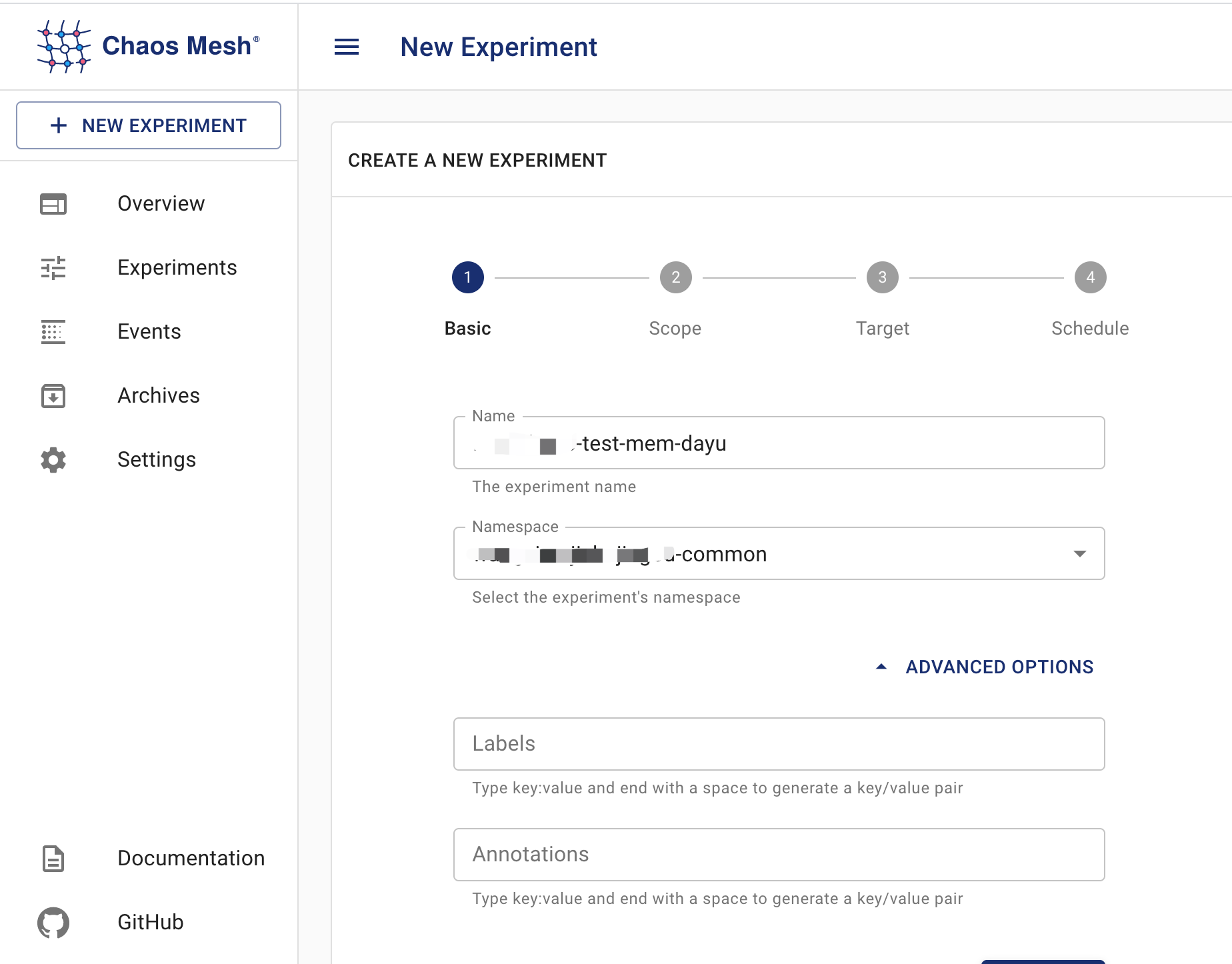
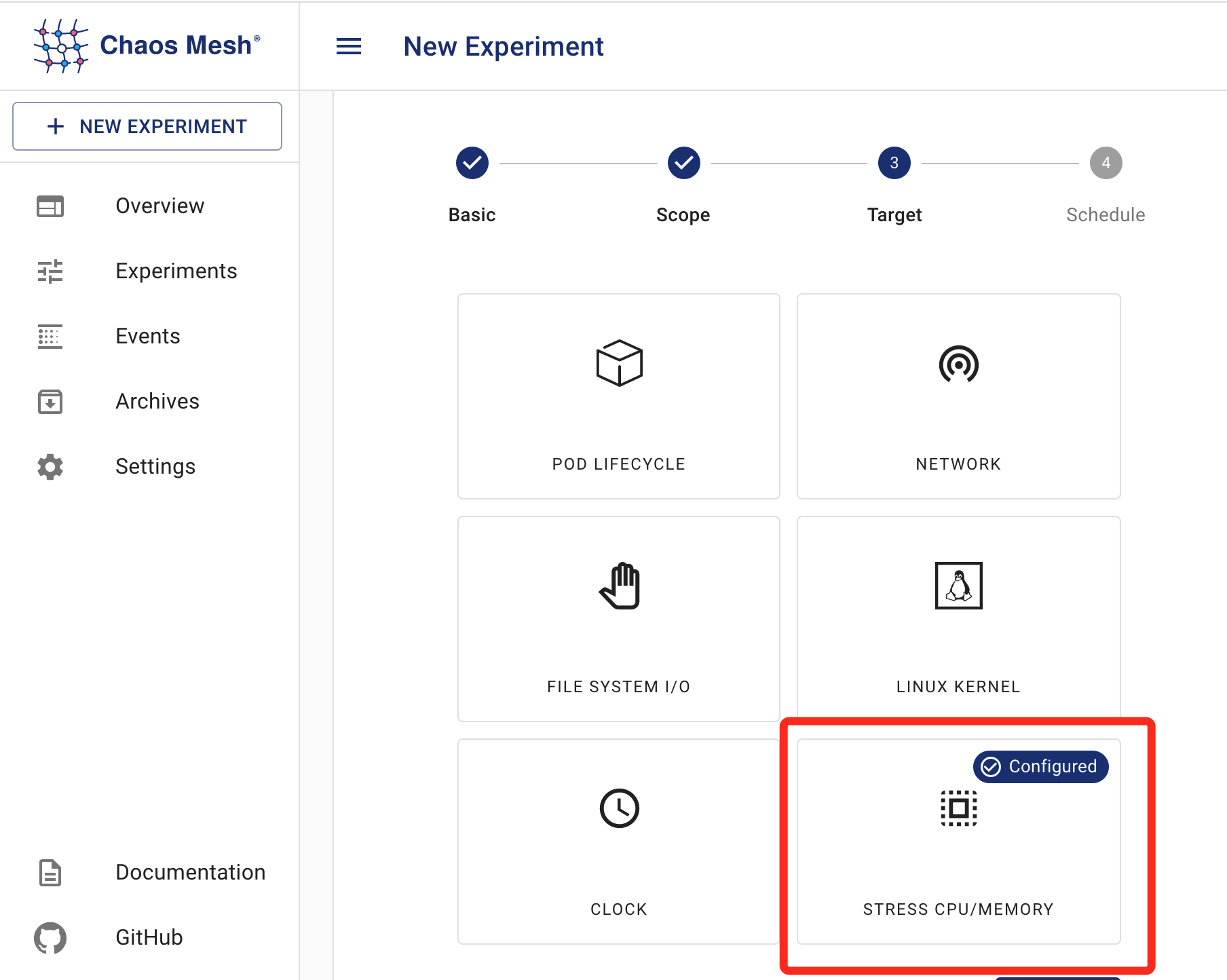
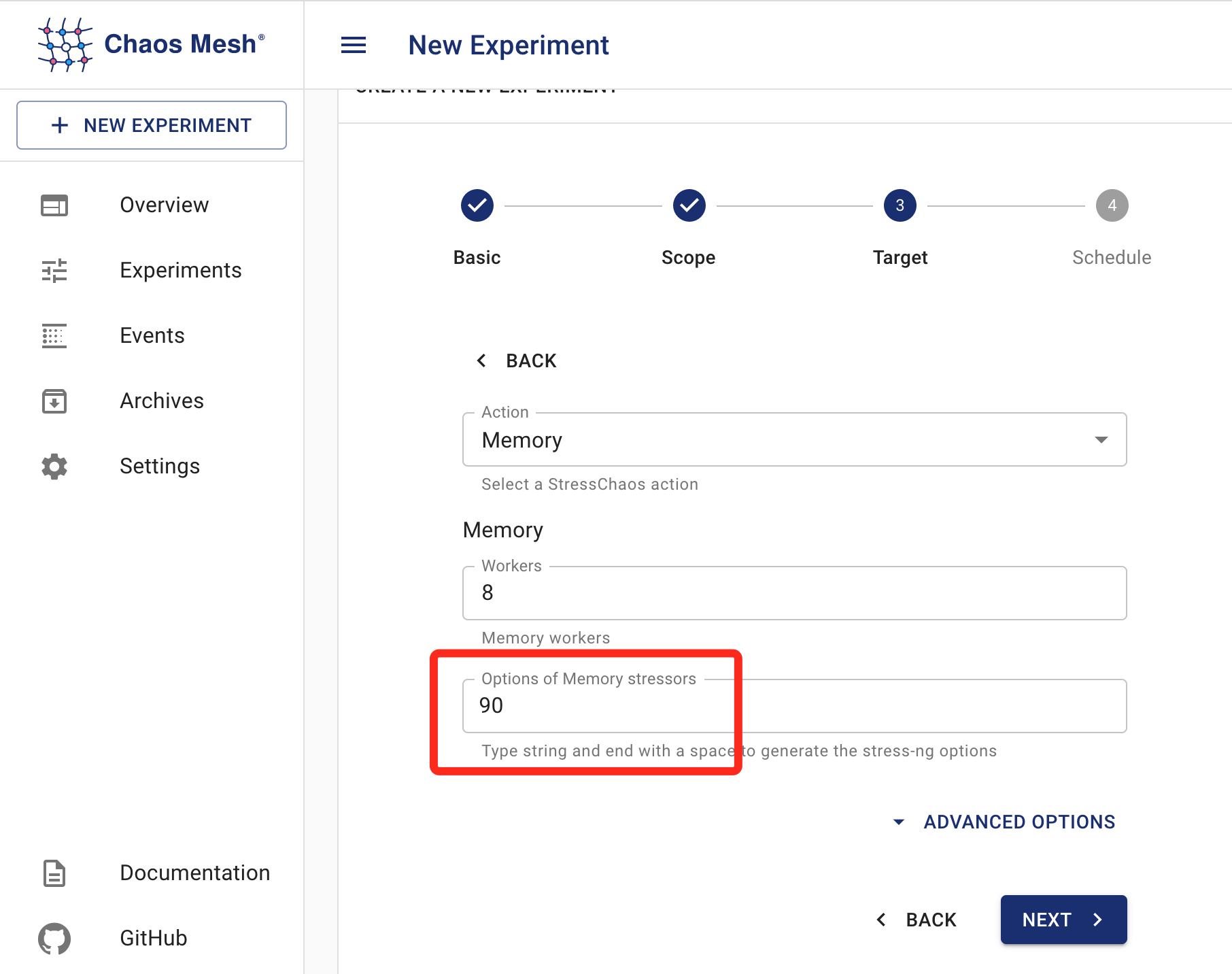
推薦:
https://prometheus.io/(官網)
https://chaos-mesh.org/ (官網)
https://www.kubernetes.org.cn/7443.html( 混沌網格(Chaos Mesh)的設計和作業原理 )
https://cloud.tencent.com/developer/article/1579651(kubernetes系列教程(二十)prometheus提供完備監控系統)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/217779.html
標籤:其他