Kubernetes概述
Kubernetes由google開源,它的開發和設計都深受Google內部久負盛名的系統Borg的影響,而且,它的許多頂級貢獻者之前也是Borg系統的開發者,Borg是Google內部使用的大規模集群管理系統,
Kubernetes吸取了Borg在過去十數年間積累的經驗和教訓,剛剛面世就立即廣受關注和青睞,目前已經成為容器編排領域事實上的標準,很多人將Kubernetes視為Borg系統的一個開源實作版本,
Kubernetes使用共享網路將多個物理機或虛擬機匯集到一個集群中,在各服務器之間進行通信,該集群是配置Kubernetes的所有組件、功能和作業負載的物理平臺,集群包含Master和Node,
Master
Master是集群的網關和中樞,負責諸如為用戶和客戶端暴露API、跟蹤其他服務器的健康狀態、以最優方式調度作業負載,以及編排其他組件之間的通信等任務,它是用戶或客戶端與集群之間的核心聯絡點,并負責Kubernetes系統的大多數集中式管控邏輯,
Node
Node是Kubernetes集群的作業節點,負責接收來自Master的作業指令并根據指令相應地創建或銷毀Pod物件,以及調整網路規則以合理地路由和轉發流量等,
Kubernetes集群組件
一個典型的Kubernetes集群由一個或一組Master和多個Node、一個集群狀態存盤系統(etcd)和add-ons組成,
Kubernetes的系統架構:
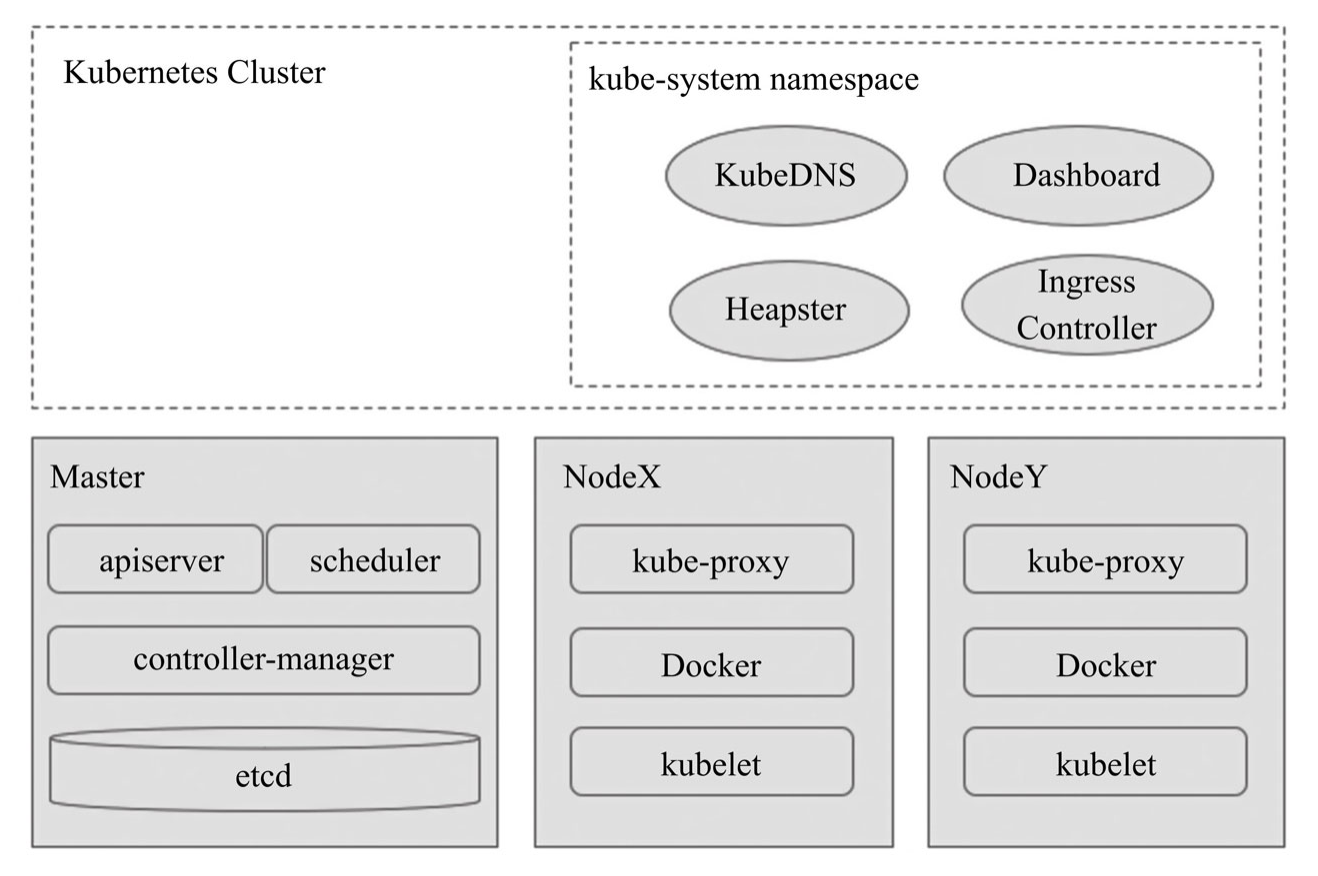
Master節點主要由apiserver、controller-manager和scheduler三個組件,以及一個用于集群狀態存盤的etcd存盤服務組成,而每個Node節點則主要包含kubelet、kube-proxy及容器引擎等組件,
Master組件
API Server
API Server負責輸出RESTful風格的KubernetesAPI,它是發往集群的所有REST操作命令的接入點,并負責接收、校驗并回應所有的REST請求,結果狀態被持久存盤于etcd中,
Controller Manager
Kubernetes中,集群級別的大多數功能都是由幾個被稱為控制器的行程執行實作的,這幾個行程被集成于kube-controller-manager守護行程中,由控制器完成的功能主要包括生命周期功能和API業務邏輯.
- 生命周期功能:包括Namespace創建和生命周期、Event垃圾回收、Pod終止相關的垃圾回收、級聯垃圾回收及Node垃圾回收等,
- API業務邏輯:例如,由ReplicaSet執行的Pod擴展等
Scheduler
在API Server確認Pod物件的創建請求之后,Scheduler就會根據集群內各節點的可用資源狀態,以及要運行的容器的資源需求做出調度決策,
Cluster State Store
etcd被用作Kubernetes集群狀態的存盤,etcd是獨立的服務組件,并不隸屬于Kubernetes集群自身,生產環境中應該以etcd集群的方式運行以確保其服務可用性,
Node組件
kubelet
kubelet是Node的核心代理程式,它是運行于作業節點之上的守護行程,從API Server接收關于Pod物件的配置資訊并確保它們處于期望的狀態(desired state),kubelet會在API Server上注冊當前作業節點,定期向Master匯報節點資源使用情況,并通過cAdvisor監控容器和節點的資源占用狀況,
容器運行時環境
每個Node都需要容器運行時(ContainerRuntime)環境,才能下載鏡像、啟動容器,kubelet以插件的方式載入配置的容器環境,目前支持Docker、RKT、cri-o和Fraki等容器環境,
kube-proxy
每個Node都需要運行一個kube-proxy守護行程,它能夠按需為Service資源物件生成iptables或ipvs規則,從而捕獲訪問當前Service的ClusterIP的流量并將其轉發至正確的后端Pod物件,
Addons
Kubernetes集群還依賴于一系列add-ons以提供完整的功能,它們通常是由第三方提供的特定應用程式,且托管運行于Kubernetes集群之上,比如
- KubeDNS:在Kubernetes集群中調度運行提供DNS服務的Pod,同一集群中的其他Pod可使用此DNS服務決議主機名,
- Kubernetes Dashboard:可以通過Dashboard來管理集群中的應用甚至是集群自身,
- Heapster:容器和節點的性能監控與分析系統,其功能會逐漸由Prometheus結合其他組件所取代,
- Ingress Controller:與負載均衡相關,
Kubernetes網路模型基礎
云計算的核心是虛擬化技術,網路虛擬化技術又是其最重要的組成部分,用于在物理網路上虛擬多個相互隔離的虛擬網路,實作網路資源切片,提高網路資源利用率,實作彈性化網路,
為了提供更靈活的解決方式,Kubernetes的網路模型需要借助于外部插件實作,它要求任何實作機制都必須滿足以下需求:
- 所有Pod間均可不經NAT(網路地址轉換)機制而直接通信
- 所有節點均可不經NAT機制而直接與所有容器通信
- 容器自己使用的IP也是其他容器或節點直接看到的地址,所有Pod物件都位于同一平面網路中,而且可以使用Pod自身的地址直接通信,
Kubernetes集群包含三種網路:
- 各主機(Master、Node和etcd等)自身所屬的網路,用于各主機之間的通信,其地址配置于主機的網路介面,且在Kubernetes集群構建之前就已配置好,它并不能由Kubernetes管理,
- 專用于Pod資源物件的網路,它是一個虛擬網路,用于為各Pod物件設定IP地址等網路引數,其地址配置于Pod中容器的網路介面之上,Pod網路需要借助kubenet插件或CNI插件實作,插件可獨立部署于Kubernetes集群之外,也可托管于Kubernetes之上,在創建Pod物件時由其自動完成各網路引數(Pod IP)的動態配置,
- 專用于Service資源物件的網路,也是虛擬網路,用于為Kubernetes集群之中的Service配置IP地址,但此地址并不配置于任何主機或容器的網路介面之上,而是通過Node之上的kube-proxy配置為iptables或ipvs規則,從而將發往此地址的所有流量調度至其后端的各Pod物件之上,Service網路在Kubernetes集群創建時予以指定,而各Service的地址(Cluster IP)則在用戶創建Service時予以動態配置,
綜上,Kubernetes為Pod和Service資源物件分別使用了各自的專用網路,Pod網路由Kubernetes的網路插件配置實作,而Service的網路則由Kubernetes集群予以指定,
學習資料
《Kubernetes實戰進階》 馬永亮著
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/272457.html
標籤:其他