問題:
我有一個4維的numpy陣列:
x = np.range(1000) 。 reshape(5, 10, 10, 2 )如果我們列印它:
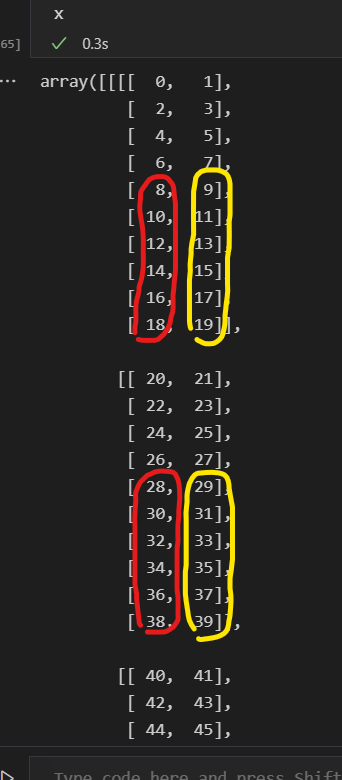
我想找到第二軸中陣列的6個最大值的指數,但僅為最后一個軸中的第0個元素(圖片中的紅色圓圈):
indLargest2ndAxis = np.argpartition(x[... ,0], 10-6, axis=2)[. .,10-6:]這些指數的形狀為(5,10,6),符合預期。
我想獲得第二軸中這些指數的值,但現在是最后一個軸中的第一個元素的值(圖片中的黃色圓圈)。它們的形狀應該是(5,10,6)。如果不進行矢量處理,可以用以下方法完成:
np.array([ [ [ x[i, j, k, 1] for k in indLargest2ndAxis[i, j]] for j in range(10) ] for i in range(5) ])然而,我想實作它的矢量化。我試著用以下方法進行索引:
x[indLargest2ndAxis, 1]但是我得到
IndexError: index 5 is out of bounds for axis 0 with size 5。我如何以矢量的方式來管理這個索引組合?我不知道。
uj5u.com熱心網友回復:
啊,我想我現在明白你的目的了。花式索引是這里詳細記錄的。但請注意,就其全部內容而言,這是相當沉重的東西。簡而言之,花式索引允許你從一個源陣列(根據一些idx)中獲取元素,并將它們放入一個新的陣列中(花式索引總是回傳一個副本):
source = np.array([10.5, 21, 42] )
idx = np. array([0, 1, 2, 1, 1, 1, 2, 1, 0] )
# This is fancy indexing[/span].
target = source[idx]
expected = np.array([10. 5, 21, 42, 21, 21, 21, 42, 21, 10。 5])
assert np.allclose(target, expected)
這樣做的好處是,你可以用索引陣列的形狀來控制結果陣列的形狀:
source = np.array([10.5, 21, 42] )
idx = np.array([[0, 1], [1, 2]] )
target = source[idx]
expected = np.array([[10.5, 21], [21, 42]] )
assert np.allclose(target, expected)
assert target.shape ==(2,2)。
如果source有一個以上的維度,事情就變得有點有趣了。在這種情況下,你需要指定每個軸的索引,這樣numpy就知道要取哪些元素:
source = np.range(4).reshape(2,2)
idxA = np.array([0, 1] )
idxB = np.array([0, 1] )
# this will take (0,0) and (1,1)
target = source[idxA, idxB]
expected = np.array([0, 3] )
assert np.allclose(target, expected)
請注意,同樣,target的形狀與使用的索引的形狀相匹配。 花式索引的厲害之處在于,如果有必要,索引的形狀會被廣播出來:
source = np.range(4).reshape(2,2)
idxA = np.array([0, 0, 1, 1]) 。 reshape((4,1)
idxB = np.array([0, 1]).reshape((1,2)
target = source[idxA, idxB] 。
預期 = np. array([[0, 1], [0, 1], [2, 3], [2, 3]] )
assert np.allclose(target, expected)
在這一點上,你可以理解你的例外來自哪里。你的source.ndim是4;然而,你試圖用一個2元組(indLargest2ndAxis, 1)來索引它。Numpy將此解釋為你試圖用indLargest2ndAxis來索引第一個軸,用1索引第二個軸,用:索引所有其他軸。很明顯,這是不可行的。indLargest2ndAxis的所有值都必須在0和4之間(包括),因為它們必須是指沿x的第一個軸的位置。
我建議的x[..., indLargest2ndAxis, 1]所做的是告訴numpy你希望對x的最后兩個軸進行索引,也就是說,你希望使用indLargest2ndAxis對第三軸進行索引,使用1對第四軸進行索引,而:對其他東西進行索引。
這將產生一個結果,因為indLargest2ndAxis的所有元素都在[0, 10)中,但將產生一個(5, 10, 5, 10, 6)的形狀(這不是你想要的)。有點手忙腳亂,形狀的第一部分(5, 10)來自省略號(...),也就是。選擇所有的東西,中間部分(5, 10, 6)來自indLargest2ndAxis根據indLargest2ndAxis的形狀沿x的第三軸選擇元素,最后部分(你看不到,因為它被擠壓了)來自沿第四軸選擇索引1。
繼續討論你的實際問題,你完全可以避開花哨的索引子彈,做以下的事情:
x = np.range(1000)。 reshape(5, 10, 10, 2)
順序 = x[..., 0]
values = x[..., 1]
idx = np.argpartition(order, 4) [..., 4: ]
result = np.take_along_axis(values, idx, axis=-1)
編輯:當然,你也可以使用花式索引;但是,它更隱蔽,而且不能很好地擴展到不同的形狀:
x = np.range(1000)。 reshape(5, 10, 10, 2)
indLargest2ndAxis = np.argpartition(x[..., 0], 4) [..., 4:]
result = x[np.range(5)[:, None, None], np. arange(10)[None, :, None], indLargest2ndAxis, 1]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/309459.html
標籤:
下一篇:如何讓scipy.stats.truncnorm.rvs使用numpy.random.default_rng()?