我有一個需要讀取的檔案。我正在讀取的檔案如下:
我有一個需要讀取的檔案。
module first(x,y,z);
輸出x。
input y;
input [0:7] z;
# z后來在檔案中使用,并且出現兩次以上。
endmodule
.....
閱讀完上述檔案后,我需要尋找任何遵循input identifier;或input [digit:digit] identifier;模式的行,為此我做了一個正則運算式如下:
pattern = re.compile(r'(input)(s*)([*d*d*d*:*d*d*]*)(s )(w )')
然后我需要找到變數名稱(識別符號)。在上面的例子中input y; 。我將需要找到y。如果這個變數出現兩次或更少,我需要將其洗掉。因此,如果y在檔案中只出現兩次,我將洗掉input y一行和括號中的y。因此,該檔案將變為
module first(x,z);
輸出x。
input [0:7] z;
# z在檔案中出現兩次以上。
endmodule
.....
我寫的代碼如下:
我寫的代碼如下:
pattern = re.compile(r'(input)(s*)([*d*d*d*:*d*d*)*) (s )(w )')
with open('filename' ,'r') as f:
data = f.read()
結果 = re.search(pattern, data)
identifier = search_result.group(5)
上面的代碼只允許我在一個輸入中獲得第一個變數名,在檔案中,僅此而已。我試著把它放在一個for回圈中,但這也沒有用。
在我找到所有被宣告為輸入的變數名之后,我想檢查該變數名在檔案中是否出現了兩次或更少。如果它出現的次數少于兩次,那么我將不得不洗掉它在input y和括號中的宣告行。
我應該怎么做呢?
我應該怎么做呢?
uj5u.com熱心網友回復:
pattern = re.compile(r'(input)(s*)([dd*d*:dd*d*]*)(s )(w )')
如果我們只需要字串末尾的變數名部分,那么我們可以跳過已經匹配的那些括號,因為我們可以只匹配末尾部分。然后,我們還需要另一個regex來匹配module行。
你可以對檔案內容進行兩次迭代:
- 第一次迭代計算帶有
"input"代碼的變數名的出現次數 。
- 然后進行第二次迭代,洗掉/重構行中存在計數小于或等于2的變數名稱的行 。
from collections import Counter
import re
# 讀取輸入檔案
with open('input.txt') as file_input。
contents = file_input.readlines()
# Initialize the counters for the variable names declared in both the <input> and <module> lines.
input_names = Counter()
module_names = Counter()
# 準備好regex匹配器以捕獲在<input>和<module>行中宣告的變數名。
input_re = re.compile(r"^.*input.*?(w );$")
module_re = re.compile(r"^module(.*?)((.*));$")
# 遍歷檔案內容中的每一行,計算所有的變數名。目前還沒有洗掉,只是計算。
for line in contents:
if match := input_re.match(line)。
# 如果該行是<input>行,提取并計算變數名。
input_names[match.group(1)] = 1.
elif match := module_re.match(line):
# 如果該行是一個<module>行,提取并計算用逗號分隔的變數名稱。
splits = match.group(2).split(', ')
module_names = Counter(splits)
# Get the names to delete, which are the variables in <input> that are only used once or twice.
names_to_delete = set()
for key in input_names:
if input_names[key] module_names.get(key, 0) <= 2:
# 所以如果<input>中的變數只使用了兩次或更少,就把它標記為洗掉。
names_to_delete.add(key)
# 對每一行重新進行重復。這一次,洗掉要洗掉的變數名。
contents_updated = ""。
for line in contents。
if match := input_re.match(line)。
if match.group(1) in names_to_delete:
# 如果該行是<input>行,并且包含要洗掉的變數,則洗掉整行。
line = ""
elif match := module_re.match(line)。
# 如果該行是一個<module>行,洗掉要洗掉的變數。在沒有這些變數的情況下重新構建該行。
splits = match.group(2).split(', ')
line = module_re.sub(
r'module1('/span> ",". join(filter(lambda value: value not in names_to_delete, splits) ");"。
行。
)
contents_updated = line
# 將更新的內容寫入一個新檔案。
with open('output.txt', 'w) as file_output:
file_output.write(contents_updated)
print("Deleted names:"/span>, names_to_delete)
input.txt
module first(x,y,z);
輸出x。
input y;
input [0:7] z;
input [1:2] abc;
input [3:4] jkl;
模塊second(abc,def,ghi,jkl,mno)。
input mno;
模塊三(z,jkl)。
模塊四(pq)。
input pq;
模塊四(RSTU)。
module fifth(def,x);
input v。
output.txt
module first(x,z);
輸出x。
input [0:7] z;
input [3:4] jkl;
模塊second(def,ghi,jkl)。
模塊第三(z,jkl)。
模塊fourth()。
模塊四(RSTU)。
模塊五(def,x)。
執行輸出:
洗掉的名字。{'pq', 'y', 'v', 'abc', 'mno'] 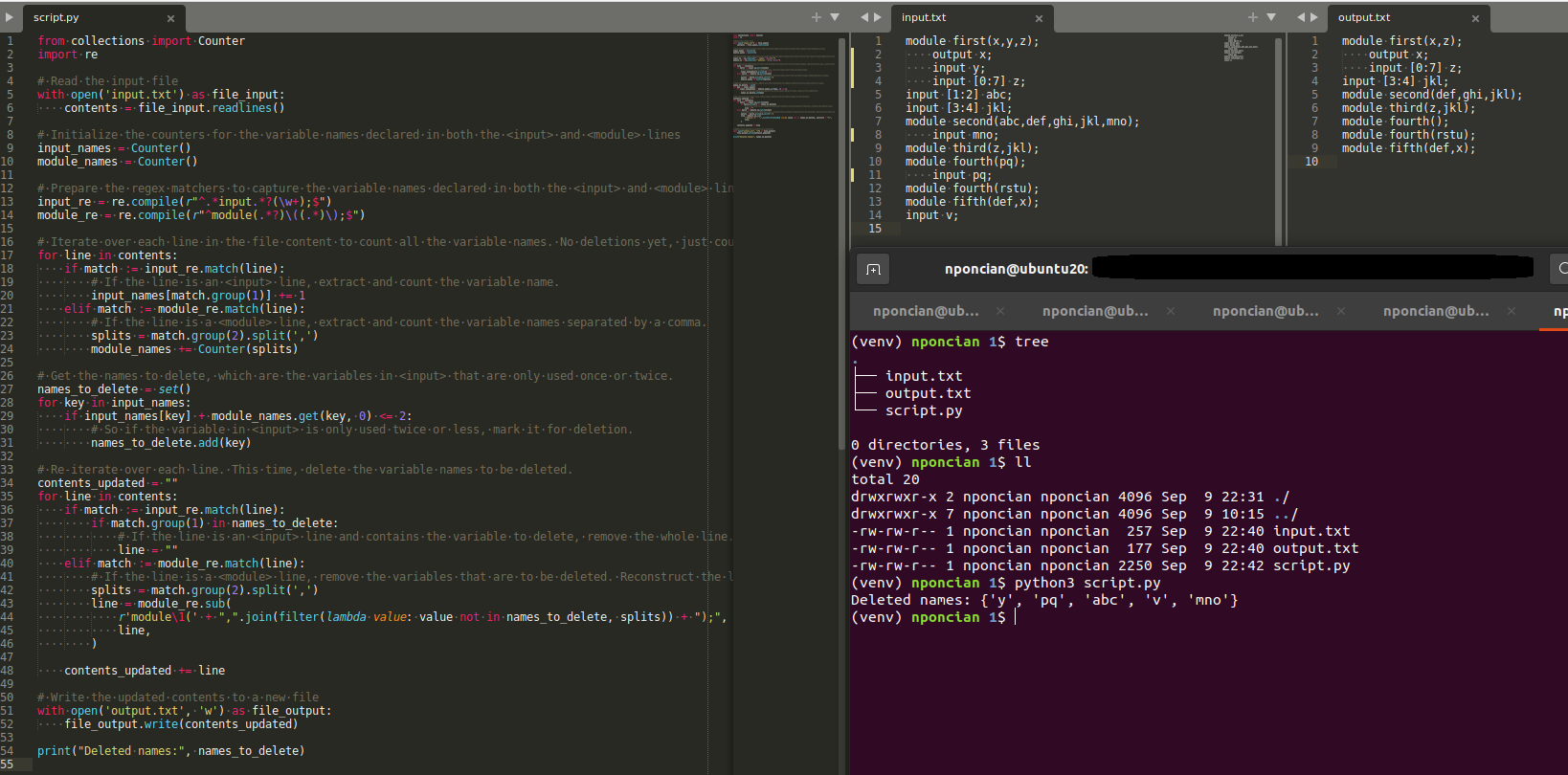
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/310464.html
標籤: