我有一個文本檔案,'student.txt'。一些鍵有多個值。我只想要與名稱相關的資料,以及該名稱下方的兄弟和愛好值。
'學生.txt'
ignore me
name-> Alice
name-> Sam
sibling-> Kate,
unwanted
sibling-> Luke,
hobby_1-> football
hobby_2-> games
name-> Ramsay
hobby_1-> dance
unwanted data
hobby_2-> swimming
hobby_3-> jogging
ignore data
我做過的代碼:
file = open("student.txt", "r")
with open("student.csv", "w") as writer:
main_dict = {}
student_dict = {"Siblings": "N/A", "Hobbies": "N/A"}
sibling_list = []
hobby_list = []
flag = True
writer.write ('name,siblings,hobbies\n')
header = 'Name,Siblings,Hobbies'.split(',')
sib_str = ''
hob_str =''
for eachline in file:
try:
key, value = eachline.split("-> ")
value = value.strip(",\n")
if flag:
if key == "name":
print (key,value)
if len(sibling_list) > 0:
main_dict[name]["Siblings"] = sib_str
#print (main_dict)
if len(hobby_list) > 0:
main_dict[name]["Hobbies"] = hob_str
sibling_list = []
hobby_list = []
name = value
main_dict[name] = student_dict.copy()
main_dict[name]["Name"] = name
elif key == "sibling":
sibling_list.append(value)
sib_str= ' '.join(sibling_list).replace(' ', '\n')
elif key.startswith("hobby"):
hobby_list.append(value)
hob_str = ' '.join(hobby_list)
if len(sibling_list) > 0:
main_dict[name]["Siblings"] = sib_str
if len(hobby_list) > 0:
main_dict[name]["Hobbies"] = hob_str
if 'name' in eachline:
if 'name' in eachline:
flag = True
else:
flag = False
except:
pass
for eachname in main_dict.keys():
for eachkey in header:
writer.write(str(main_dict[eachname][eachkey]))
writer.write (',')
if 'Hobbies' in eachkey:
writer.write ('\n')
上面代碼的 CSV 輸出:
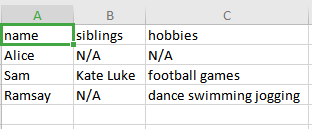
預期的 CSV 輸出:
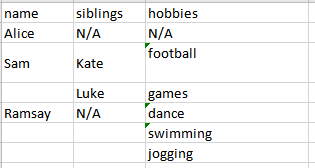
PS:我似乎無法弄清楚如何不放棄嘗試/通過。因為有些行(沒有 '->')是不需要的,我不能使用 eachline.split("->")。也將不勝感激。
非常感謝!
uj5u.com熱心網友回復:
請參閱我在下面粘貼的代碼,它提供了可以匯入到 excel 中的 csv 檔案,并且它的格式與您期望的完全相同。
你可以使用類似的東西
if "->" not in line:
continue
要跳過不包含“->”值的行,請參見下面的代碼:
import csv
file = open("student.txt", "r")
students = {}
name = ""
for line in file:
if "->" not in line:
continue
line = line.strip(",\n")
line = line.replace(" ", "")
key, value = line.split("->")
if key == "name":
name = value
students[name] = {}
students[name]["siblings"] = []
students[name]["hobbies"] = []
else:
if "sibling" in key:
students[name]["siblings"].append(value)
elif "hobby" in key:
students[name]["hobbies"].append(value)
#print(students)
csvlines = []
for student in students:
name = student
hobbies = students[name]["hobbies"]
siblings = students[name]["siblings"]
maxlength = 0
if len(hobbies) > len(siblings) :
maxlength = len(hobbies)
else:
maxlength = len(siblings)
if maxlength == 0:
csvlines.append([name, "N/A", "N/A"])
continue
for i in range(maxlength):
if i < len(siblings):
siblingvalue = siblings[i]
elif i == len(siblings):
siblingvalue = "N/A"
else:
siblingvalue = ""
if i < len(hobbies):
hobbyvalue = hobbies[i]
elif i == len(siblings):
hobbyvalue = "N/A"
else:
hobbyvalue = ""
if i == 0:
csvlines.append([name, siblingvalue, hobbyvalue])
else:
csvlines.append(["", siblingvalue, hobbyvalue])
print(csvlines)
fields = ["name", "siblings", "hobbies"]
with open("students.csv", 'w') as csvfile:
# creating a csv writer object
csvwriter = csv.writer(csvfile)
# writing the fields
csvwriter.writerow(fields)
# writing the data rows
csvwriter.writerows(csvlines)
如果這對您有幫助,請將其標記為答案,或者如果您對此不清楚,請發表評論。謝謝
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/312978.html
上一篇:如何遍歷StackOverflowapi中的元組字典
下一篇:Python迭代和創建嵌套字典