我想結合來自多個來源的資訊來繪制一系列圖表的不同方面。不同的圖表代表不同的元素,但對于每個圖表,我試圖將箱線圖、散點圖、與方程的最佳擬合線、每個分析物的平均值線和每個分析物的 3 個標準偏差組合在一起。我擁有需要繪制的所有資料,并堅持將其全部組裝以獲得所需的輸出。
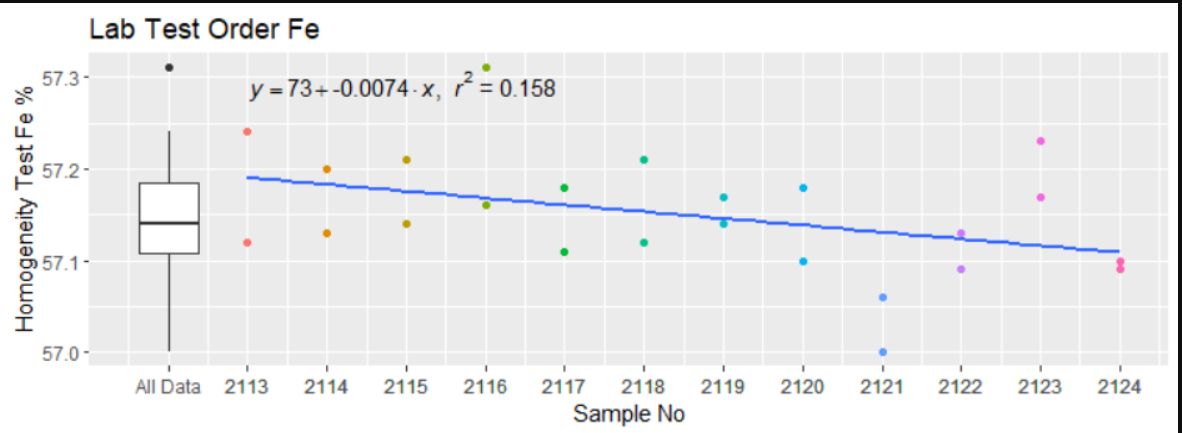
我正在尋找的是類似于下圖的東西,但對于我的資料框中的每個分析物
我的清單的一個片段
df <- structure(list(SampleNo = structure(c(1L, 1L, 2L, 2L, 3L, 3L,
4L, 4L, 5L, 5L, 6L, 6L, 7L, 7L, 8L, 8L, 9L, 9L, 10L, 10L, 11L,
11L, 12L, 12L), .Label = c("151868", "151959", "152253", "151637",
"152382", "152490", "152528", "152581", "152985", "152738", "153005",
"153337"), class = "factor"), Rep_No = c("1", "2", "1", "2",
"1", "2", "1", "2", "1", "2", "1", "2", "1", "2", "1", "2", "1",
"2", "1", "2", "1", "2", "1", "2"), Fe = c(57.24, 57.12, 57.2,
57.13, 57.21, 57.14, 57.16, 57.31, 57.11, 57.18, 57.21, 57.12,
57.14, 57.17, 57.1, 57.18, 57, 57.06, 57.13, 57.09, 57.17, 57.23,
57.09, 57.1), SiO2 = c(6.85, 6.83, 6.7, 6.69, 6.83, 6.8, 6.76,
6.79, 6.82, 6.82, 6.8, 6.86, 6.9, 6.82, 6.81, 6.83, 6.79, 6.76,
6.8, 6.88, 6.83, 6.79, 6.8, 6.83), Al2O3 = c(2.9, 2.88, 2.88,
2.88, 2.92, 2.9, 2.89, 2.87, 2.9, 2.89, 2.9, 2.89, 2.89, 2.88,
2.89, 2.91, 2.91, 2.91, 2.9, 2.9, 2.91, 2.91, 2.88, 2.86)), class = "data.frame", row.names = c(NA,
-24L))
我的第一個串列資料
l1 <- list(Fe = structure(list(hm = 57.2, hsd = 0.295156858558032,
hmin = 56.3145294243259, hmax = 58.0854705756741), class = "data.frame", row.names = c(NA,
-1L)), SiO2 = structure(list(hm = 6.7497718955, hsd = 0.111404744433739,
hmin = 6.41555766219878, hmax = 7.08398612880122), class = "data.frame", row.names = c(NA,
-1L)), Al2O3 = structure(list(hm = 2.8925, hsd = 0.0725002768867193,
hmin = 2.67499916933984, hmax = 3.11000083066016), class = "data.frame", row.names = c(NA,
-1L)))
l2 <- list(Fe = "italic(y) == \"1.5\" \"0.000000000000001\" %.% italic(x) * \",\" ~ ~italic(r)^2 ~ \"=\" ~ \"0.00000000000000000000000000000114\"",
SiO2 = "italic(y) == \"1.5\" \"0.000000000000001\" %.% italic(x) * \",\" ~ ~italic(r)^2 ~ \"=\" ~ \"0.00000000000000000000000000000114\"",
Al2O3 = "italic(y) == \"1.5\" \"0.000000000000001\" %.% italic(x) * \",\" ~ ~italic(r)^2 ~ \"=\" ~ \"0.00000000000000000000000000000114\"")
我的代碼似乎讓我大獲全勝
library(ggplot)
library(tidyverse)
library(scales)
library(ggpmisc)
H.PlotOrder <- unique(df$SampleNo)
H.Charts <- df %>% mutate(SampleNo = factor(SampleNo, levels = H.PlotOrder))
imap(l1, ~{
ggplot(H.Charts, outlier.shape = NA,
mapping = aes(x = SampleNo, y = .data[[.y]], color = SampleNo))
coord_cartesian(ylim = as.numeric(c(min(.y),max(.y))))
geom_point(mapping = aes(x = SampleNo, y = .data[[.y]]))
geom_smooth(formula = y~x, mapping = aes(label = l2),parse =T, method = "lm",hjust =-0.35)
geom_hline(linetype = 'dashed', color = 'blue', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
- (as.numeric(.x[[1,"hsd"]])) * 3))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
(as.numeric(.x[[1,"hsd"]])) * 3))
ggtitle(paste0(.y, "Manufacturing Assessment"))
theme(plot.title = element_text(hjust = 0.5),legend.position = "None")
xlab(label = "Sample No")
ylab(paste0(.y, ' values %'))
}) -> H.PlotList
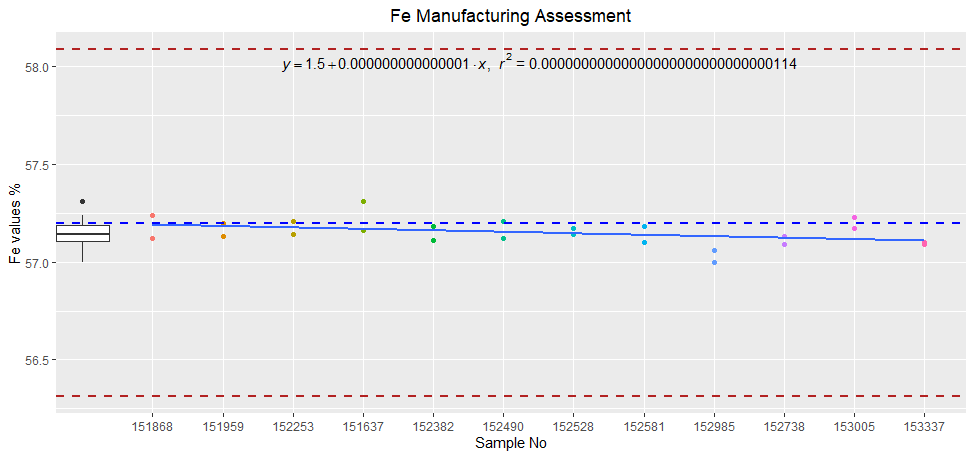
它運行,但當我嘗試查看單個圖表時,我收到以下錯誤訊息錯誤:美學必須是長度 1 或與資料相同 (24):標簽
An example of it working a single dataframe when not in a series of list
df2 <- structure(list(Sample = c(2113, 2113, 2114, 2114, 2115, 2115,
2116, 2116, 2117, 2117, 2118, 2118, 2119, 2119, 2120, 2120, 2121,
2121, 2122, 2122, 2123, 2123, 2124, 2124), Rep_No = c("A", "B",
"A", "B", "A", "B", "A", "B", "A", "B", "A", "B", "A", "B", "A",
"B", "A", "B", "A", "B", "A", "B", "A", "B"), Fe = c(57.24, 57.12,
57.2, 57.13, 57.21, 57.14, 57.16, 57.31, 57.11, 57.18, 57.21,
57.12, 57.14, 57.17, 57.1, 57.18, 57, 57.06, 57.13, 57.09, 57.17,
57.23, 57.09, 57.1), SiO2 = c("6.85", "6.83", "6.7", "6.69",
"6.83", "6.8", "6.76", "6.79", "6.82", "6.82", "6.8", "6.86",
"6.9", "6.82", "6.81", "6.83", "6.79", "6.76", "6.8", "6.88",
"6.83", "6.79", "6.8", "6.83"), Al2O3 = c("2.9", "2.88", "2.88",
"2.88", "2.92", "2.9", "2.89", "2.87", "2.9", "2.89", "2.9",
"2.89", "2.89", "2.88", "2.89", "2.91", "2.91", "2.91", "2.9",
"2.9", "2.91", "2.91", "2.88", "2.86")), row.names = c(NA, -24L
), class = "data.frame")
a <- "italic(y) == \"73\" \"-0.0074\" %.% italic(x) * \",\" ~ ~italic(r)^2 ~ \"=\" ~ \"0.158\""
p <- ggplot(data = df2, aes(x = Sample, y = Fe))
geom_point(mapping = aes(x = Sample, y = Fe, color = as.factor(Sample)))
stat_poly_eq(formula = y ~x , mapping = aes( label = a), parse = TRUE, method = "lm", hjust = -0.35 )
geom_smooth(method = lm, se = FALSE)
geom_boxplot(mapping = aes(x = min(Sample) - 1, y = Fe))
theme(legend.position = "None")
labs(title = "Lab Test Order Fe", x = "Sample No", y = "Homogeneity Test Fe %")
scale_x_continuous(labels = c("All Data", as.integer(df2$Sample)),
breaks = c(min(df2$Sample)-1, df2$Sample))
imap(l1, ~{
H.Charts %>%
ggplot( outlier.shape = NA,
mapping = aes(x = as.numeric(SampleNo), y = .data[[.y]]))
geom_point(mapping = aes(x = SampleNo, y = .data[[.y]], color = factor(SampleNo)))
stat_poly_eq(mapping = aes(label = l2[[.y]]), parse = TRUE, method = "lm", hjust = -0.35 )
geom_smooth(method = lm, se = FALSE, aes(x = as.numeric(SampleNo), y = .data[[.y]]))
geom_boxplot(aes(x = min(as.numeric(SampleNo))-1, y= .data[[.y]]))
coord_cartesian(ylim = as.numeric(c(min(.y),max(.y))))
geom_hline(linetype = 'dashed', color = 'blue', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
- (as.numeric(.x[[1,"hsd"]])) * 3))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
(as.numeric(.x[[1,"hsd"]])) * 3))
ggtitle(paste0(.y, " Manufacturing Assessment"))
theme(plot.title = element_text(hjust = 0.5),legend.position = "None")
xlab(label = "Sample No")
ylab(paste0(.y, ' values %'))
}) -> H.PlotList
H.PlotList[[1]]
uj5u.com熱心網友回復:
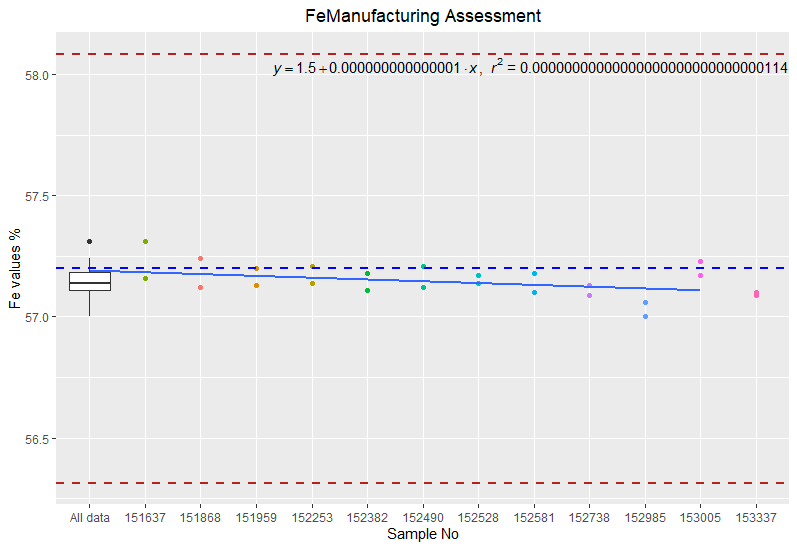
好吧,我改為SampleNo數字,因為應用geom_smoothx 軸由factor. 另外,將color的位置移動到 的內部geom_point。如果此結果不符合您的目的,請告訴我。
編輯:
我更改了位置as.numeric以使其與上面的圖相似。
imap(l1, ~{
H.Charts %>%
ggplot( outlier.shape = NA,
mapping = aes(x = as.numeric(SampleNo), y = .data[[.y]]))
geom_point(mapping = aes(x = SampleNo, y = .data[[.y]], color = factor(SampleNo)))
stat_poly_eq(formula = y ~x , mapping = aes( label = l2[[.y]]), parse = TRUE, method = "lm", hjust = -0.35 )
geom_smooth(method = lm, se = FALSE, aes(x = as.numeric(SampleNo), y = .data[[.y]]))
geom_boxplot(aes(x = factor(" All data"), y= .data[[.y]]))
coord_cartesian(ylim = as.numeric(c(min(.y),max(.y))))
geom_hline(linetype = 'dashed', color = 'blue', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
- (as.numeric(.x[[1,"hsd"]])) * 3))
geom_hline(linetype = 'dashed', color = 'firebrick', size = 0.75,
mapping = aes(yintercept = as.numeric(.x[[1,"hm"]])
(as.numeric(.x[[1,"hsd"]])) * 3))
ggtitle(paste0(.y, "Manufacturing Assessment"))
theme(plot.title = element_text(hjust = 0.5),legend.position = "None")
xlab(label = "Sample No")
ylab(paste0(.y, ' values %'))
}) -> H.PlotList
H.PlotList[[1]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/315812.html