我有一個堆疊的直方圖,它看起來像這樣:
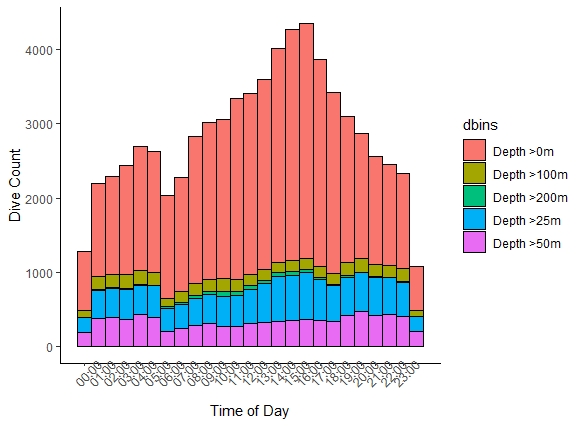
我有兩個問題:
- 我想要 24 列,而不是 25 - 所以我需要以某種方式組合第一列和最后一列。st_time 是從日期時間列中剝離超過 6 個月的時間,輸出為 POSIXct 2021-10-11 00:00:00 到 2021-10-11 23:59:54
All_M_dives$st_time <- format(as.POSIXct(All_M_dives$begdesc, format = "%d/%m/%Y %H:%M:%S"), format = "%H:%M:%S")
All_M_dives$st_time <- as.POSIXct(All_M_dives$st_time, format = "%H:%M:%S")
- 我想按深度 0,25,50,100,200 手動訂購堆疊。R按字母順序執行此操作,因此您可以在圖例/圖表中看到不正確的順序。
我想可能有一個解決方案,只使用按字母順序排列的 dbins,如果可能的話,只是重命名圖例,我只是想到了這一點。
gg <- ggplot(data = All_M_dives, aes(x = st_time, fill = dbins))
geom_histogram(colour = "black", position = "stack", binwidth = 3600 )
scale_x_datetime(date_labels = "%H:%M")
labs(title = NULL, x = "Time of Day", y = "Dive Count")
theme(legend.position = "none")
theme_classic() theme(axis.text.x = element_text(angle=45))
gg
dput 可以在這里看到: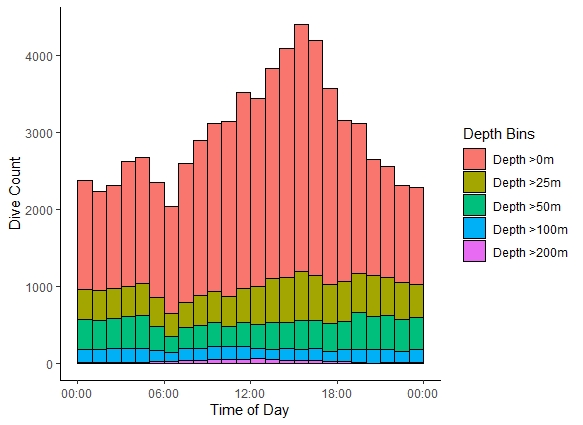
uj5u.com熱心網友回復:
我認為這可以通過添加center = 1800到您的geom_histogram行來最簡單地解決。這將使每個 bin 的寬度為 3600 秒,并跨越以 1800 秒為中心的整個小時。
fake <- data.frame(st_time = as.POSIXct("2021-10-12", tz = "GMT") runif(1E5, max = 24*60*60),
dbins = sample(LETTERS[1:5], 1E5, replace = TRUE, prob = c(20, 2, 1, 5, 5)))
ggplot(data = fake, aes(x = st_time, fill = dbins))
geom_histogram(colour = "black", position = "stack", binwidth = 3600, center = 1800 )
scale_x_datetime(date_labels = "%H:%M")
labs(title = NULL, x = "Time of Day", y = "Dive Count")
theme(legend.position = "none")
theme_classic() theme(axis.text.x = element_text(angle=45))
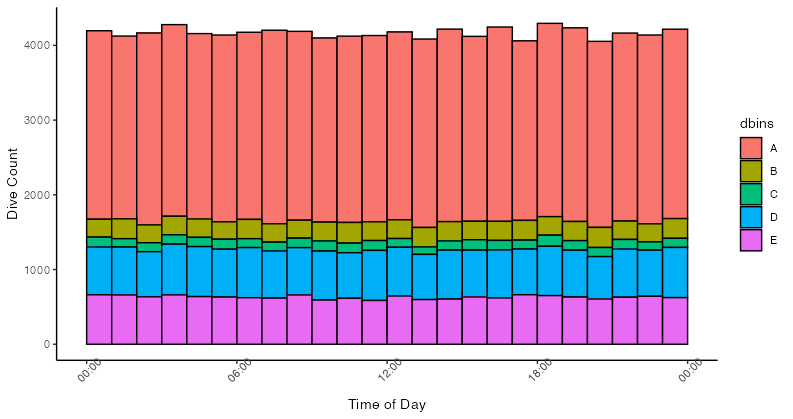
您也可以自己進行分箱并將其輸入 ggplot 以使用geom_col,對于相同的圖:
library(dplyr); library(lubridate)
fake %>%
count(st_time = floor_date(st_time, "hour"), dbins) %>%
ggplot(aes(x = st_time 1800, y = n, fill = dbins))
geom_col(colour = "black", position = "stack", width = 3600)
scale_x_datetime(date_labels = "%H:%M")
labs(title = NULL, x = "Time of Day", y = "Dive Count")
theme(legend.position = "none")
theme_classic() theme(axis.text.x = element_text(angle=45))
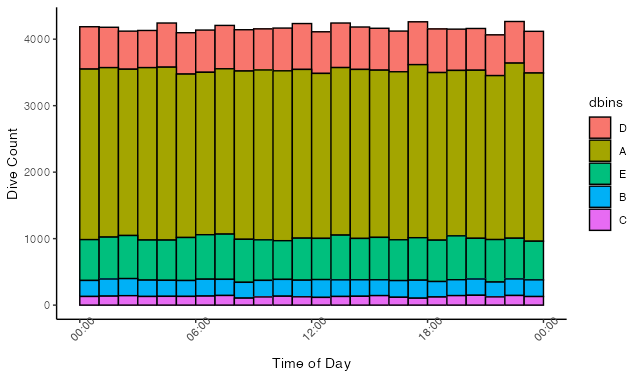
要更改系列順序,我建議將dbins變數轉換為有序因子。添加此行將排序和繪圖順序更改為我提供的順序:
fake$dbins = factor(fake$dbins, levels = c("D", "A", "E", "B", "C"))
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/315832.html