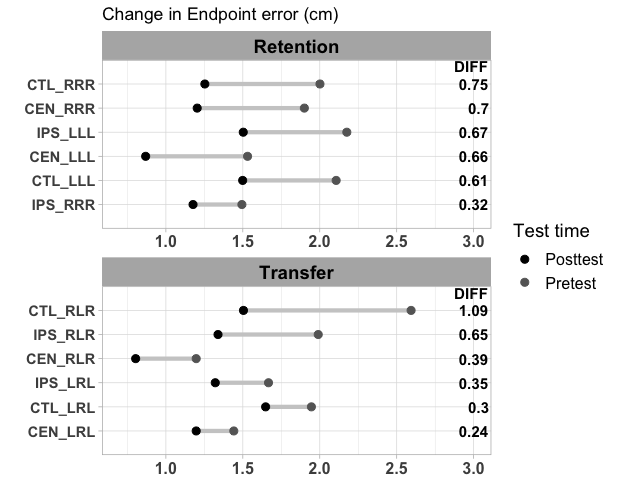
我想排列 y 值,使兩個方面的排列相似。例如,我希望 y-tick 標簽“RRR”首先出現,然后是“保留”組下的“LLL”組。在轉會組中,我希望3個“ RLR”組跟隨3個“ LLL”。目前,他們不遵循任何命令,因此很難遵循
data10 <- structure(list(Trial_type = structure(c(2L, 1L, 2L, 1L, 2L, 1L,
1L, 2L, 1L, 2L, 1L, 2L), .Label = c("1", "2"), class = "factor"),
Trial_type2 = c(2, 1, 2, 1, 2, 1, 1, 2, 1, 2, 1, 2), GROUP = c("LRL",
"RRR", "LRL", "RRR", "LRL", "RRR", "LLL", "RLR", "LLL", "RLR",
"LLL", "RLR"), conditon2 = structure(c(11L, 9L, 3L, 1L, 7L,
5L, 12L, 10L, 4L, 2L, 8L, 6L), .Label = c("IPS_RRR", "IPS_RLR",
"IPS_LRL", "IPS_LLL", "CTL_RRR", "CTL_RLR", "CTL_LRL", "CTL_LLL",
"CEN_RRR", "CEN_RLR", "CEN_LRL", "CEN_LLL"), class = "factor"),
condition20 = c(1, 1, 2, 2, 3, 3, 1, 1, 2, 2, 3, 3), Training = c("right",
"right", "right", "right", "right", "right", "left", "left",
"left", "left", "left", "left"), Pathlength_102 = c(3.187250625,
2.922721625, 3.405212, 2.775334063, 2.776401875, 3.149278375,
2.847822, 3.03391925, 3.674062375, 2.726527125, 2.78150325,
3.6662945), Pathlength_104 = c(2.8958505, 2.540974188, 3.413019688,
2.639986, 2.675723688, 2.761517625, 2.631161188, 2.664713,
2.889202063, 2.6051525, 2.568229875, 2.911062813), MovementTime_102 = c(1586.5625,
1977.5, 2181.25, 1664.6875, 2658.125, 2384.375, 1931.875,
1595, 2140.9375, 1652.8125, 1962.1875, 3074.375), MovementTime_104 = c(1445.625,
1327.1875, 2008.75, 1312.1875, 2302.8125, 1658.75, 1589.6875,
1387.1875, 1627.8125, 1611.25, 1519.0625, 2316.5625), AveResultantVel_102 = c(2.40919925,
2.069098625, 2.010902313, 1.943953438, 1.174490563, 1.548894813,
1.958885813, 2.343926125, 1.904319375, 2.122309625, 1.7739885,
1.391745563), AveResultantVel_104 = c(2.771204063, 2.5431425,
2.053414375, 2.505344125, 1.298380563, 1.983456875, 2.314399688,
2.350340875, 2.187628625, 2.051979125, 2.110770188, 1.434088938
), NormalizedJerk_102 = c(1270.168699, 2099.703957, 3259.268053,
1152.257445, 3810.890123, 4601.918336, 1792.371775, 1288.768888,
2699.08162, 1650.968794, 2018.457394, 6159.567785), NormalizedJerk_104 = c(853.7034116,
924.8554548, 2268.966702, 675.7160839, 2442.874632, 1603.954653,
1010.111276, 794.1752256, 1313.813984, 1197.638788, 1039.577947,
3125.131019), EndpointError_102 = c(1.441449813, 1.899916938,
1.666946063, 1.493975375, 1.945765938, 2.001344875, 1.530830188,
1.197009313, 2.1758275, 1.990092563, 2.106561813, 2.593554438
), EndpointError_104 = c(1.196976438, 1.203483813, 1.32090125,
1.176485125, 1.648146125, 1.253227125, 0.86855425, 0.803545313,
1.502868938, 1.338789625, 1.499023188, 1.504206125), RV_diff = c(0.36,
0.47, 0.04, 0.56, 0.12, 0.43, 0.36, 0.01, 0.28, -0.07, 0.34,
0.04), EE_diff = c(-0.24, -0.7, -0.35, -0.32, -0.3, -0.75,
-0.66, -0.39, -0.67, -0.65, -0.61, -1.09), PL_diff = c(-0.29,
-0.38, 0.01, -0.14, -0.1, -0.39, -0.22, -0.37, -0.78, -0.12,
-0.21, -0.76), NJ_diff = c(-416.47, -1174.85, -990.3, -476.54,
-1368.02, -2997.96, -782.26, -494.59, -1385.27, -453.33,
-978.88, -3034.44), MT_diff = c(-140.94, -650.31, -172.5,
-352.5, -355.31, -725.63, -342.19, -207.81, -513.13, -41.56,
-443.13, -757.81)), row.names = c(NA, -12L), spec = structure(list(
cols = list(Trial_type = structure(list(), class = c("collector_character",
"collector")), Trial_type2 = structure(list(), class = c("collector_double",
"collector")), GROUP = structure(list(), class = c("collector_character",
"collector")), conditon2 = structure(list(), class = c("collector_character",
"collector")), condition20 = structure(list(), class = c("collector_double",
"collector")), Training = structure(list(), class = c("collector_character",
"collector")), Pathlength_102 = structure(list(), class = c("collector_double",
"collector")), Pathlength_104 = structure(list(), class = c("collector_double",
"collector")), MovementTime_102 = structure(list(), class = c("collector_double",
"collector")), MovementTime_104 = structure(list(), class = c("collector_double",
"collector")), AveResultantVel_102 = structure(list(), class = c("collector_double",
"collector")), AveResultantVel_104 = structure(list(), class = c("collector_double",
"collector")), NormalizedJerk_102 = structure(list(), class = c("collector_double",
"collector")), NormalizedJerk_104 = structure(list(), class = c("collector_double",
"collector")), EndpointError_102 = structure(list(), class = c("collector_double",
"collector")), EndpointError_104 = structure(list(), class = c("collector_double",
"collector")), RV_diff = structure(list(), class = c("collector_double",
"collector")), EE_diff = structure(list(), class = c("collector_double",
"collector")), PL_diff = structure(list(), class = c("collector_double",
"collector")), NJ_diff = structure(list(), class = c("collector_double",
"collector")), MT_diff = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), skip = 1), class = "col_spec"), class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"))
library(tidyverse)
library(ggplot2)
library(rlang)
library(utils)
library(data.table)
library(dumbbell)
data10$conditon2 <- forcats::fct_reorder(data10$conditon2, data10$conditon2, .desc = TRUE)
data10A<-data10 %>% select(conditon2,Trial_type,EndpointError_102,EndpointError_104) %>% mutate("key"="Change In Endpoint Error (cm)")
data10B<-data10A %>% mutate("diff"=EndpointError_104-EndpointError_102) %>% arrange(desc(diff))
data10A$conditon2<-factor(data10A$conditon2, data10B$conditon2)
data10A$Trial_type <- factor(data10A$Trial_type, levels = 1:2, labels = c("Retention", "Transfer"))
dumbbell::dumbbell(data10A, id="conditon2", key="Trial_type", leg = "Test time", column1 = "EndpointError_102", column2="EndpointError_104", delt=1, lab1="Pretest", lab2="Posttest", p_col1 = "black", p_col2 = "grey40", textsize = 4, segsize = 1.5, pointsize = 2.5, title = "Change in Endpoint error (cm)")
xlim(0.7,3.0) facet_wrap( Trial_type ~., scales="free", ncol=1)
theme(axis.text.x = element_text(size = 12,face="bold"),
axis.text.y = element_text(size = 11, face = "bold")) theme(legend.position="right") theme(legend.text=element_text(size=12), legend.title=element_text(size=14)) theme(strip.text = element_text(face="bold", size=14, color = "black"))
uj5u.com熱心網友回復:
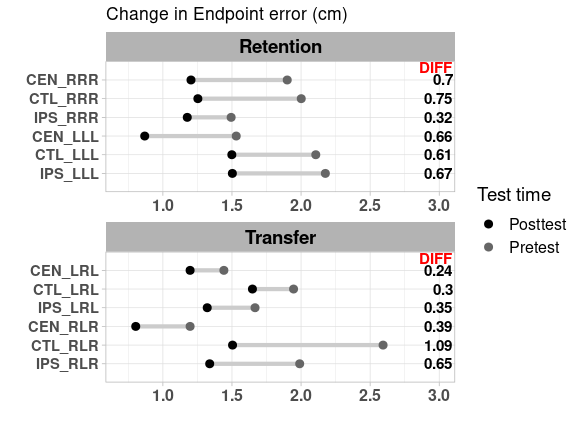
如果您想要的訂單是
RRR然后LLL和LRL然后RLR
更改因子condition2水平,然后按照問題進行繪制。
library(tidyverse)
library(dumbbell)
data10A <- data10 %>% select(conditon2,Trial_type,EndpointError_102,EndpointError_104) %>% mutate("key"="Change In Endpoint Error (cm)")
data10A$Trial_type <- factor(data10A$Trial_type, levels = 1:2, labels = c("Retention", "Transfer"))
i1 <- grepl("_RR", levels(data10A$conditon2))
i2 <- grepl("_RL", levels(data10$conditon2))
i3 <- grepl("_LL", levels(data10A$conditon2))
RRR_levels <- levels(data10A$conditon2)[i1]
RLR_levels <- levels(data10A$conditon2)[i2]
LLL_levels <- levels(data10A$conditon2)[i3]
LRL_levels <- levels(data10A$conditon2)[!i1 & !i2 & !i3]
ord_levels <- c(LLL_levels, RRR_levels, RLR_levels, LRL_levels)
data10A$conditon2 <- factor(data10A$conditon2, levels = ord_levels)
dumbbell(data10A, id = "conditon2", key = "Trial_type",
leg = "Test time",
column1 = "EndpointError_102",
column2 = "EndpointError_104",
delt = 1, lab1 = "Pretest", lab2 = "Posttest",
p_col1 = "black", p_col2 = "grey40",
textsize = 4, segsize = 1.5,
pointsize = 2.5,
title = "Change in Endpoint error (cm)")
xlim(0.7,3.0)
facet_wrap( Trial_type ~., scales="free", ncol=1)
theme(axis.text.x = element_text(size = 12, face = "bold"),
axis.text.y = element_text(size = 11, face = "bold"),
legend.position = "right",
legend.text = element_text(size = 12),
legend.title = element_text(size = 14),
strip.text = element_text(face = "bold", size = 14, color = "black"))
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/315848.html