我目前正在閱讀Richard Bird & Jeremy Gibbons的Algorithm Design with Haskell,Saddleback search演算法是在第四章二進制搜索之后給出的,給出的問題動機是:
給定f:N x N -> N在兩個引數中都是嚴格增加的,以及一個值t找到所有的對(x,y)使f(x,y)=t.
第一個定義由search f t =[(x,y) | x ← [0...t],y ← [0...t],t == f(x,y)]給出,它從左下角的原點開始搜索到右上角,(指數從下到上和從左到右遞增),然后本書進行了改進。
第二個定義是由搜索f t =[(x,y) | x ← [0...t], y ← [t,t -1...0],t == f(x, y)]給出。
書中參考這個定義時說
Theta(m n)對于一個尺寸為n x m的矩陣。
最后的演算法看起來像這樣
search f t = searchIn (0,t)
where searchIn (x, y) | x>t ∨ y<0 =[] 。
| z<t = searchIn (x 1, y)
| z == t = (x, y): searchIn (x 1, y-1)
| z>t = searchIn (x,y-1)
where z = f(x,y)
為什么會出現這種情況?從原點(0,0)開始有什么問題? 為什么將x坐標取為遞增,而將y坐標取為遞減,或者反過來(我在leetCode上看到x遞減,y遞增),為什么不將兩個坐標都取為遞增方向?
uj5u.com熱心網友回復:
一個典型的問題的輸入將看起來像這樣:

黑色像素代表的是數值。
黑色像素代表大于t的值,白色較小,而灰色則相等。我們的目標是要找到所有的灰色斑點。理想情況下,為了做這個搜索,我們只想沿著黑色和白色之間的邊界行走。唯一的問題是,我們不知道這個邊界從哪里開始,所以我們甚至需要搜索才能知道在哪里搜索。
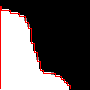
第一步是找到邊界,我們可以通過從左下角向上掃描直到找到它。但是,然后......我們必須轉過身來! 搜索的剩余部分,我們向下和向右進行。因此,我們必須把搜索分成兩個階段,一個是尋找邊界,另一個是跟蹤邊界。如果你從左上角開始,雖然......

這一次,我們在左上角添加了一條紅色曲線。
這一次,我們不需要轉身,這意味著我們可以重復使用我們用于遵循邊界的其余部分的代碼,以首先找到邊界!
這就回答了 "為什么不從原點開始"。另一個問題,"為什么不在一個方向上增加而在另一個方向上減少",嗯......你可以。這是一個幾乎相同的問題,而且一個幾乎相同的演算法可以解決它。
uj5u.com熱心網友回復:
我一直在閱讀這個,我想我現在明白了,為什么在鏈接中,有一個關于兩個排序串列的目標之和的更簡單的問題,問題陳述:
給定一個值k和兩個排序的整數串列(都是不同的),找到所有一對整數(i, j),其中i j == k。
解決方案必須決定哪一個串列移動list1或list2或兩者,以及when,然后它將list1按升序排序,list2按降序排序,這有助于為每一種情況分配一個決定
讓i表示元素list1和j表示list2中的元素,
i j < k
i j > k
i j == k
分別映射到move on(list1, list2, both)。
現在同樣適用于矩陣的情況,假設我們從原點(0,0)開始。 因為我們自下而上地遍歷每一列,讓我們在
a列,假設我們在b行遇到一個元素z,這樣z=f(a,b) > = t那么我們就可以離開a列和b行,實際上整個上矩形的左下角是(a,b)(因為f在兩個引數中都是嚴格增加的,而且從原點開始都是增加的)。
下一個起點將是(a 1,0),但是當z=f(a,b) < t時,我們可以什么都不做,只是在當前列中完成,直到我們碰到一個大于t的元素,或者列結束。
從問題中的搜索演算法實作來看,似乎選擇一個索引是遞增的,另一個是遞減的,在實作中引入了更多的規則性,同時新的起點通常在矩陣內部,所以我們沒有對點進行線性搜索,這將減少搜索空間,不像從(a 1,0)開始。
我無法進行全面的分析,以了解在最壞的情況下時間復雜度會受到怎樣的影響,但我認為這很有說服力。
歡迎任何評論,如果有完整的分析方案,我們將不勝感激
。轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/316979.html
標籤:
上一篇:使用>>=表達基本的數字決議器