我有以下資料框架,我需要使用id列進行groupby,并且相應的值應該在同一單元格的串列中。有誰能幫助我解決這個問題?
我有這樣處理過的資料框架:
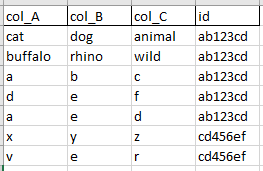
實際的資料框架:
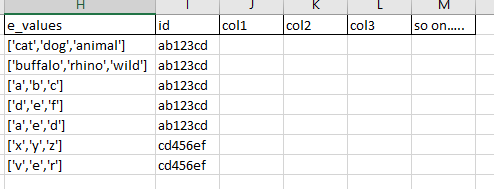
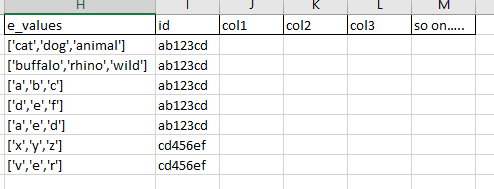
在實際的資料框架中:
 uj5u.com熱心網友回復:
uj5u.com熱心網友回復:df['e_values'] = df. filter(like='col_').apply(list, axis=1)
uj5u.com熱心網友回復:
如果從實際到處理。 你可以分割,expand=True,然后替換角括號。這應該給你一個資料框架,你可以重命名列
。df['values'].str. split(',',expand=True).replace(regex={'[': ', ' ]': ''})
如果從處理過的到實際的使用:
df.set_index('id').agg(list,1).reset_index()
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/324005.html
標籤:
下一篇:linux遞回地替換檔案中的字串