所以基本上我在嘗試這段代碼時卡住了,但它沒有拆分名稱和數字。PL 參考示例影像以了解所需的結果。
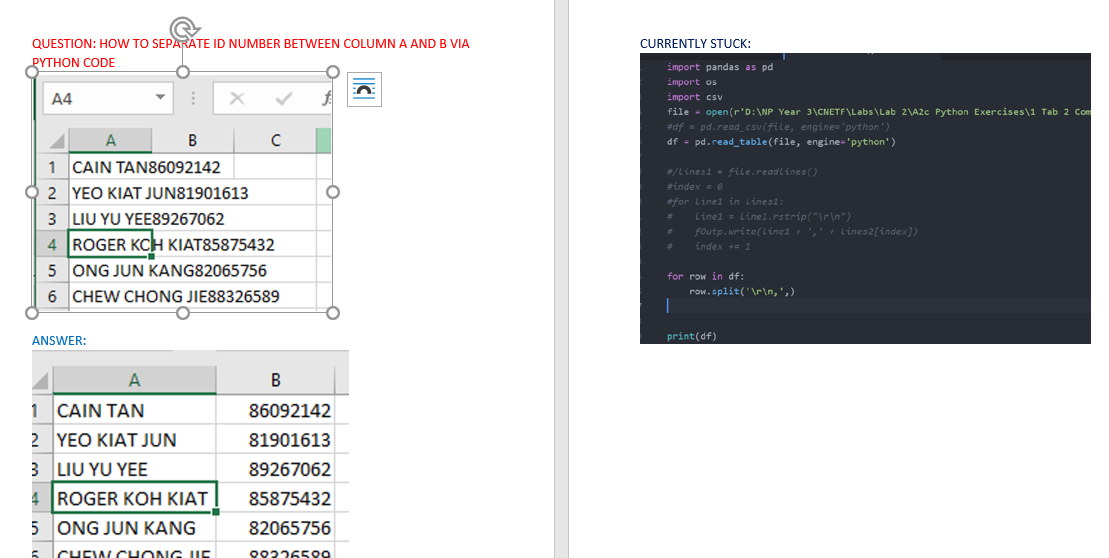
我試過的代碼
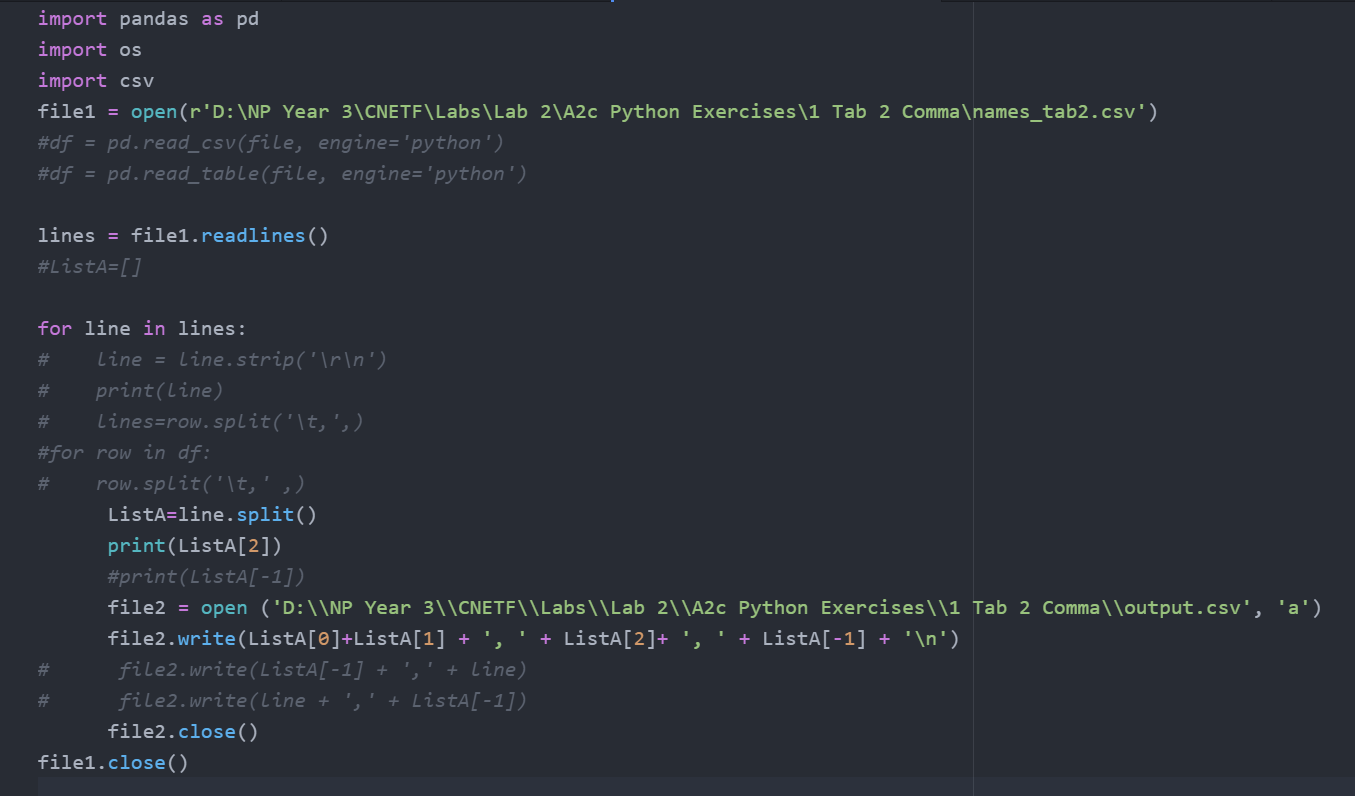
EDIT1:添加了前 5 行代碼 https://pastebin.com/uEU5X3DZ
`將熊貓匯入為 pd 匯入 o??s 匯入 csv
#df = pd.DataFrame({'ColA': ['CAIN TAN86092142', 'YEO KIAT JUN81901613']})
df = pd.read_csv('D:\NP Year 3\CNETF\Labs\Lab 2\A2c Python Exercises\1 Tab 2 Comma\names_tab2.csv', 'r')
#names_tab2.csv的前5行#("CAIN TAN 86092142", "YEO KIAT JUN 81901613", "LIU YU YE EEE 89267062", "ROGER KOH KIAT 85875432", "ONG JUN KANG 85206")
out = df['ColA'].str.extract(r'([^\d]*)(\d )')
.rename(columns={0: 'Name', 1: 'Number'})
out.to_csv('D:\NP Year 3\CNETF\Labs\Lab 2\A2c Python Exercises\1 Tab 2 Comma\data.csv', index=False, header=None)
print(out)`
Edit2: names_tab2 file link
https://wetransfer.com/downloads/349f20af819edf2702b27ac6e0c9c22b20211019083824/e09ef6
uj5u.com熱心網友回復:
您在參考和分隔符方面有問題。要清理資料框,請使用以下代碼:
pd.read_csv('names_tab2.csv', quoting=1, header=None)[0] \
.str.split('\t', expand=True) \
.to_csv('clean_names.csv', index=False, header=False)
舊答案
使用str.extract:
假設這個資料框:
df = pd.DataFrame({'ColA': ['CAIN TAN86092142', 'YEO KIAT JUN81901613']})
print(df)
# Output:
ColA
0 CAIN TAN86092142
1 YEO KIAT JUN81901613
在遇到的第一個數字上拆分:
out = df['ColA'].str.extract(r'([^\d]*)(\d )') \
.rename(columns={0: 'Name', 1: 'Number'})
print(out)
# Output:
Name Number
0 CAIN TAN 86092142
1 YEO KIAT JUN 81901613
更新:
有沒有辦法在輸出到 csv 時洗掉名稱和編號?
out.to_csv('data.csv', index=False, header=None)
# content of data.csv:
CAIN TAN,86092142
YEO KIAT JUN,81901613
uj5u.com熱心網友回復:
打開純文本檔案(或在本例中為純文本 csv 檔案)時,您可以使用 for 回圈逐行瀏覽檔案,如下所示(當前為 Python 3):
name = []
id_num = []
file = open('file.csv', 'r')
for f in file:
f = f.split(',') # split the data
name.append(str(f[0])) # append name to list
id_num.append(str(f[1])) # append ID to list
現在您擁有串列中的資料,您可以根據需要列印/存盤它。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/326232.html