我正在嘗試比較 CSV 檔案中的 2 列時間戳,我只想保留第 1 列中的日期/時間在第 2 列中的日期/時間之前的行。我不太確定從哪里開始,因為我們正在考慮將許多不同的數字(例如,月、年、小時、分鐘等)分別與彼此相關地進行比較,包括上午/下午的比較。
示例:(日期為 [mm/dd/yyyy] 格式)
| 11/20/2018 下午 3:00:13 | 2017/11/23 上午 6:45:00 |
| 12/22/2019 下午 4:00:12 | 2020/1/10 上午 4:50:11 |
| 2018/10/10 下午 2:02:19 | 10/07/2018 下午 1:04:15 |
在這里,我想保留第 2 行,因為第 2 列中的日期在第 1 列中的日期之后,我不想保留第 1 行和第 3 行。在命令列中是否有一種巧妙的方法可以做到這一點?(如果沒有,任何撰寫 Python 腳本的指標都會非常有幫助)
提前致謝!
uj5u.com熱心網友回復:
在 Python 中,您只需要將每個日期值轉換為datetime物件。然后可以很容易地將它們與簡單的<運算子進行比較。例如:
from datetime import datetime
import csv
with open('input.csv') as f_input, open('output.csv', 'w', newline='') as f_output:
csv_input = csv.reader(f_input)
#header = next(csv_input)
csv_output = csv.writer(f_output)
#csv_output.writerow(header)
for row in csv_input:
date_col1 = datetime.strptime(row[0], '%m/%d/%Y %I:%M:%S %p')
date_col2 = datetime.strptime(row[1], '%m/%d/%Y %I:%M:%S %p')
if date_col1 < date_col2:
csv_output.writerow(row)
如果您的 CSV 檔案包含標題,請取消對這兩行的注釋。您可以在
從我們的資料集中列印單個日期以檢查模式:
請記住,python 中的索引從零開始
dataset[1][0] # dataset[row][column]
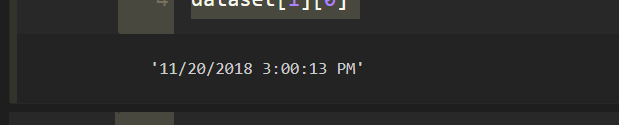
2.2) 模式是月/日/年小時:分鐘:秒 AM/PM
pattern = "%m/%d/%Y %I:%M:%S %p"
您可以檢查
成功轉換^
4) 現在我們將手動比較日期以理解概念。
通過簡單地使用比較運算子,我們可以使用 datetime 庫比較 python 中的日期
print(dataset[2][0] , "and" , dataset[2][1])
print(dataset[2][0] > dataset[2][1])

5)現在創建一個單獨的串列,其中僅添加第 2 列的日期大于第 1 列的日期的那些行:
col2_greatorthan_col1 = []
在我們的新串列中添加標題:
col2_greatorthan_col1.append(["column 1" , "column 2"])
比較每個日期并在我們的新串列中附加我們想要的行:
for i in dataset[1:]:
if i[1] > i[0]: # means if column 2's date is greater than column 1's date
col2_greatorthan_col1.append(i) # appending the filtered rows in our new list
col2_greatorthan_col1

6) 現在只需創建一個真實世界的 csv 檔案,該檔案將具有與col2_greatorthan_col1相同的資料
import csv
with open("new_dates.csv" , "w" , newline = "") as file :
writer = csv.writer(file)
writer.writerows(lst)
結果 :
名為new_dates.csv 的新 csv 檔案將在與您的 Python 代碼檔案相同的目錄中創建。該檔案將只包含第 2 列的日期大于第 1 列的日期的那些行。
uj5u.com熱心網友回復:
使用熊貓
import pandas as pd
# Read tab delimited CSV file without header
# Names columns date1, date2
df = pd.read_csv("dates.csv",
header = None,
sep='\t',
parse_dates = [0, 1], # use default date parser i.e. parser.parser
names=["date1", "date2"])
# Filter (keep) row when date2 > date1
df = df[df.date2 > df.date1]
# Output to filtered CSV file using the original date format
df.to_csv('filtered_dates.csv', index = False, header = False, sep = '\t', date_format = "%Y/%m/%d %I:%M:%S %p")
uj5u.com熱心網友回復:
我已將您提供的示例保存在一個制表符分隔檔案中 - 沒有標題。我已將其作為DataFrameusing匯入(請注意,我在 中指定了您的日期格式date_parser):
import pandas as pd
import datetime as dt
df = pd.read_csv(PATH_TO_YOUR_FILE, sep="\t", names=["col1", "col2"], parse_dates=[0,1], date_parser=lambda x:dt.datetime.strptime(x, "%m/%d/%Y %I:%M:%S %p")
要選擇您需要的行:
df.loc[df.loc[:,"col2"]>df.loc[:,"col1"],:]
uj5u.com熱心網友回復:
您可以使用pd.to_datetime決議日期時間字串,然后使用它們的比較作為條件來過濾所需的行。
演示:
import pandas as pd
df = pd.DataFrame({
'start': ['11/20/2018 3:00:13 PM', '12/22/2019 4:00:12 PM', '10/10/2018 2:02:19 PM'],
'end': ['11/23/2017 6:45:00 AM', '1/10/2020 4:50:11 AM', '10/07/2018 1:04:15 PM']
})
result = pd.DataFrame(df[
pd.to_datetime(df['start'], format='%m/%d/%Y %I:%M:%S %p') <
pd.to_datetime(df['end'], format='%m/%d/%Y %I:%M:%S %p')
])
print(result)
輸出:
start end
1 12/22/2019 4:00:12 PM 1/10/2020 4:50:11 AM
ONLINE DEMO
uj5u.com熱心網友回復:
在最初的問題中,@samster 正在尋找一種使用命令列過濾他的 CSV 的方法,所以這里有一種在 POSIX-Shell 中執行此操作的方法。我試了一下,因為在這種特定情況下決議 CSV 很容易(沒有轉義逗號或其他任何東西)。
首先,我們定義一個函式,用于將日期轉換為允許我們進行比較的數字:
date_to_num()
{
# The input format is '%m/%d/%Y %I:%M:%S %p'
IFS='/ :'
read m d Y I M S p <<-EOD
$1
EOD
# Rules for converting AM/PM to 24H
if [ $I -eq 12 ] && [ $p == "AM" ]
then
H=0
elif [ $I -lt 12 ] && [ $p == "PM" ]
then
H=$(( I 12 ))
else
H=$I
fi
printf '%dddddd' $Y $m $d $H $M $S
}
注意:我不使用該date命令,因為它的轉換功能不是POSIX ......例如,對于GNU date它是date -d '11/20/2018 12:00:13 AM' ' %s',對于BSD date它是date -j -f '%m/%d/%Y %I:%M:%S %p' '11/20/2018 3:00:13 PM' ' %s'和對于Solaris date它不可能進行轉換。
現在我們只需要讀取 CSV 檔案并列印 column1 中的日期/時間在 column2 中的日期/時間之前的行:
IFS=','
while read d0 d1
do
[ $(date_to_num $d0) -lt $(date_to_num $d1) ] && echo "$d0,$d1"
done < file.csv
uj5u.com熱心網友回復:
使用命令列工具,您可以使用awk: 將第一個日期轉換為紀元格式:
echo "11/20/2018 3:00:13 PM" |gawk -F'[/:]' '{print mktime($3" "$1" "$2" "$4" "$5" "$6" "$7)}'
第二個欄位相同。然后從第 1 列中減去第 2 列。如果結果為正,則表示第 1 列在第 2 列之后
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/326235.html