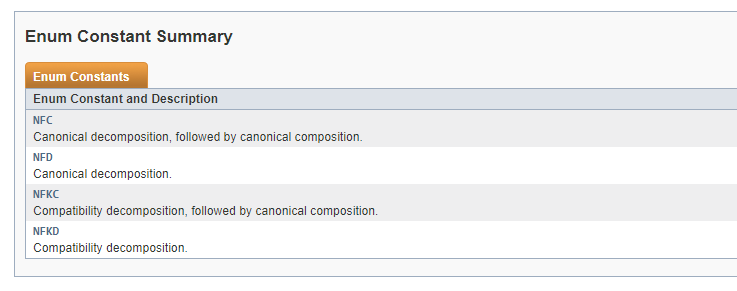
我Normalizer.normalize(url, Normalizer.Form.NFD)用來避免é在我的 url 中出現類似字符,我不明白Normalizer.Form常量(NFC、NFD、NFKC 和 NFKD)的含義或何時使用每個。
我查閱了檔案,但這根本沒有幫助。
有沒有人對這個話題有任何想法?
提前致謝!
uj5u.com熱心網友回復:
- D =分解
e′ - C =組成
é
K 代表連字,一個字母?(ffi) 或 3:ff i。
這是在javadoc 中提到的:
帶有重音或其他裝飾的字符可以在 Unicode 中以幾種不同的方式進行編碼。例如,取字符 A-acute。在 Unicode 中,這可以編碼為單個字符(“組合”形式):
U 00C1 LATIN CAPITAL LETTER A WITH ACUTE or as two separate characters (the "decomposed" form): U 0041 LATIN CAPITAL LETTER A U 0301 COMBINING ACUTE ACCENT To a user of your program, however, both of these sequences should be treated as the same“用戶級”字符“帶有重音符號的 A”。在搜索或比較文本時,必須確保將這兩個序列視為等效。此外,您必須處理具有多個重音的字符。有時,字符組合重音的順序很重要,而在其他情況下,不同順序的重音序列實際上是等效的。類似地,字串“ffi”可以編碼為三個單獨的字母:
U 0066 LATIN SMALL LETTER F U 0066 LATIN SMALL LETTER F U 0069 LATIN SMALL LETTER I or as the single character U FB03 LATIN SMALL LIGATURE FFI
因此,在您的情況下,您需要 NFKD,完全分解。
s = Normalizer.normalize(s, Normalizer.Form.NFD).replaceAll("\\p{M}", "");
后者replaceAll只是洗掉了組合變音符號,零寬度重音符號′。仍然有問題的拉丁字母,如
?用洗掉線擦亮小 L?土耳其語小 I 無點?帶點的土耳其首都 I
但可能已經在進行非 ASCII 替換。
當然,現在人們可能在某種程度上擁有Unicode URL,帶有特殊字符的站點。并且小心翼翼,這些角色不會被破壞。
分解形式的規范化的另一個用途是按字母順序對國家名稱進行排序:(?sterreich德語中的奧地利) before P。
一些細節
K 代表“兼容性”,因此很重要。
一個字母上可以有多個重音(零寬度組合變音符號)。
可以有一個包含組合字母和分解字母的字串。
所以實際上 NFC 是:規范分解,然后是規范組合。所以為了做一個好的組合,最好先分解哪個為你做 Normalizer。
Composition also has its use; for instance it is guaranteed canonical (single norming form), and is compact for String.codePointAt.
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/326789.html
上一篇:用串列中的每個字串替換一個字串