情況
我試圖在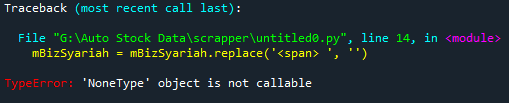
Non-Compliant字樣。
問題
我怎樣才能洗掉span標簽,以獲得該標簽中的文本?
謝謝!
uj5u.com熱心網友回復:
處理beautifulsoup最簡單的方法是.text或者如果你想抓取和修改(加入和剝離)get_text()。
mBizSyariah.text #contains whitespaces。
mBizSyariah.get_text(strip=True) #without additional whitespaces實體
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '。
'Chrome/87.0.4280.88 Safari/537.36 '。
}
mBizLink = requests.get(str('https://www.malaysiastock.biz/Corporate-Infomation.aspx?securityCode=7164'), headers=header)
mBizParser = BeautifulSoup(mBizLink.text, 'html.parser')
mBizParser.find('label', {'id' : 'ctl17_lbShariah'}) 。 find('span').get_text(strip=True)
輸出:
'不符合規定'
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/331285.html
標籤: