我有一個包含以下示例資料的表。該表實際上包含超過 1000 萬行。
| 表號 | ID | 型別 |
|---|---|---|
| 1 | 1 | 蘇1 |
| 2 | 2 | 蘇1 |
| 3 | 2 | 蘇2 |
| 4 | 3 | 蘇3 |
| 5 | 4 | 蘇1 |
我必須計算所有只有 su1 型別的 ID。如果 id 有 su1 但還有另一種型別,那么它不應該被計算在內。這是我想出的查詢。
Select Count(*) From (
Select id
From table t
Where exists (select null from table t1 where t.id = t1.id and t1.type = 'su1')
Group by id
Having Count(*) = 1) a
tableid 是主鍵。Id 上有一個非聚集索引。還有其他方法可以撰寫此查詢嗎?
uj5u.com熱心網友回復:
鑒于此表和示例資料:
CREATE TABLE dbo.[table]
(
tableid int,
Id int,
type char(3),
INDEX IX_table CLUSTERED (Id, type)
);
INSERT dbo.[table](tableid, Id, type) VALUES
(1, 1, 'su1'),
(2, 2, 'su1'),
(3, 2, 'su2'),
(4, 3, 'su3'),
(5, 4, 'su1');
一種方法是:
;WITH agg AS
(
SELECT tableid, Id, type,
mint = MIN(Type) OVER (PARTITION BY Id),
maxt = MAX(Type) OVER (PARTITION BY Id)
FROM dbo.[table]
)
SELECT tableid, Id, type
FROM agg
WHERE mint = maxt AND mint = 'su1';
如果您的聚集索引在Id, type這將允許單個聚集索引掃描:
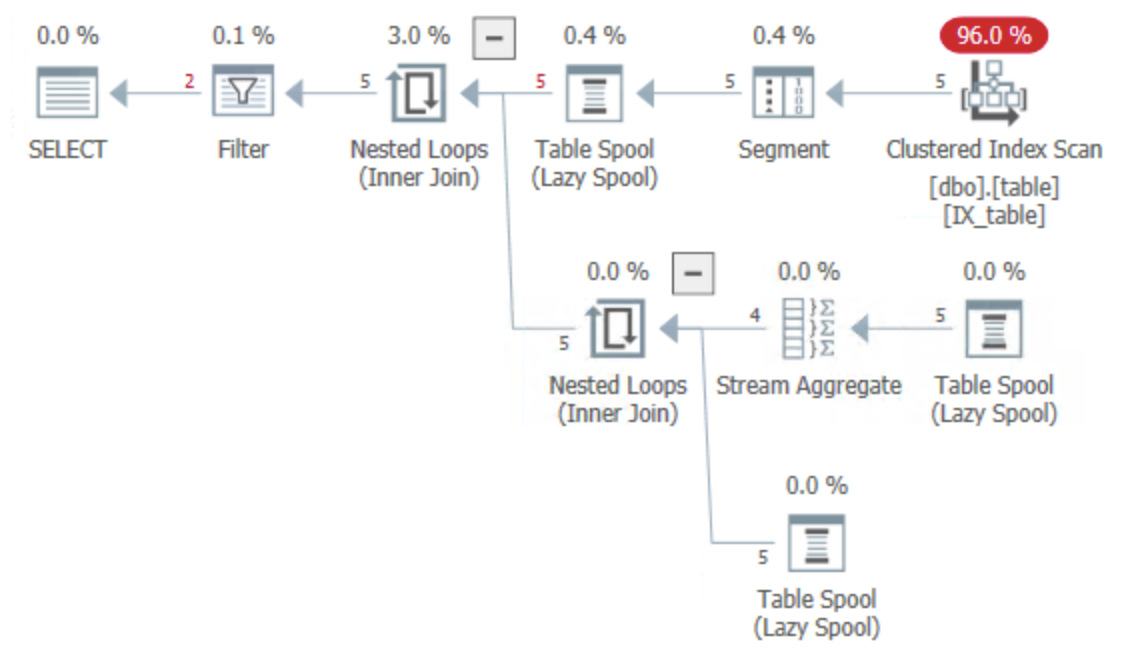
盡管有些我們可能不想要的線軸有點亂。David 的建議怎么樣(假設您使用的是 SQL Server 2017 或更高版本):
SELECT tableid = MIN(tableid), Id
FROM dbo.[table]
GROUP BY Id
HAVING STRING_AGG(type, ',') = 'su1';
哦,是的,那好多了:

- db<>fiddle示例
uj5u.com熱心網友回復:
我不完全確定你為什么有,Having Count(*) = 1因為它似乎沒有反映在要求中。
但是這個查詢更好寫如下
SELECT COUNT(*)
FROM (
SELECT id
FROM [table] t
GROUP BY id
HAVING COUNT(CASE WHEN t1.type <> 'su1' THEN 1 END) = 0
) t;
為此,您需要以下索引
[table] (id) INCLUDE (type)
uj5u.com熱心網友回復:
也許我遺漏了一些東西,但COUNT DISTINCT在過濾掉除帶有type='su1'. 在那種情況下,我們只有:
WITH tbl (tableid, id, type) AS (
select * from values (1,1,'su1'), (2,2,'su1'), (3,2,'su2'), (4,3,'su3'), (5,4,'su1')
)
SELECT COUNT(DISTINCT id) FROM tbl
WHERE id NOT IN (SELECT id FROM tbl WHERE type != 'su1')
-- 2
這是 SQL Fiddle,我洗掉了COUNT DISTINCT以便您可以查看單個結果,并且更容易在此處檢查。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/332837.html
標籤:sql sql-server 查询语句 sql性能
下一篇:加速磁區ROW_NUMBER()