該
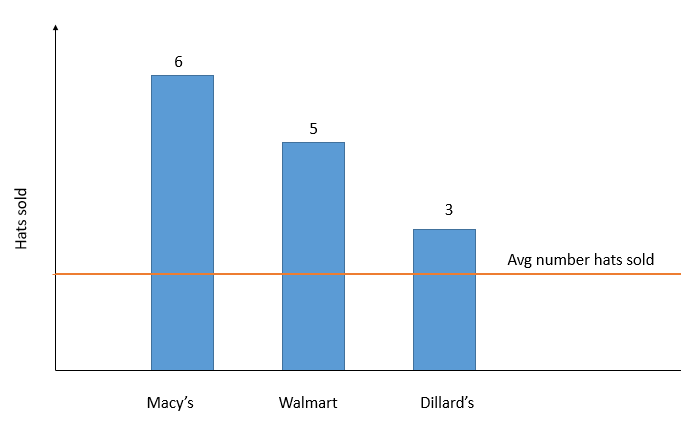
如果我們這樣做,讓 Vega 計算平均值:
{
"$schema": "https://vega.github.io/schema/vega-lite/v2.json",
"title": "Hat Sales",
"data": {
"url": {
"index": "hat-sales",
"body": {
"size": 0,
"query": {"match_all": {}},
"aggs": {"stores": {"terms": {"field": "store.keyword", "size": 3}}}
}
},
"format": {"property": "aggregations.stores.buckets"}
},
"transform": [
{"calculate": "datum.key", "as": "store"},
{"calculate": "datum.doc_count", "as": "count"}
],
"layer": [
{
"name": "Sales of top 3 stores",
"mark": "bar",
"encoding": {
"x": {"type": "nominal", "field": "store", "sort": "-y"},
"y": {"type": "quantitative", "field": "count"}
}
},
{
"name": "Average number of sales over all stores",
"mark": {"type": "rule", "color": "red"},
"encoding": {"y": {"aggregate": "mean", "field": "count"}}
}
]
}
看起來像這樣:
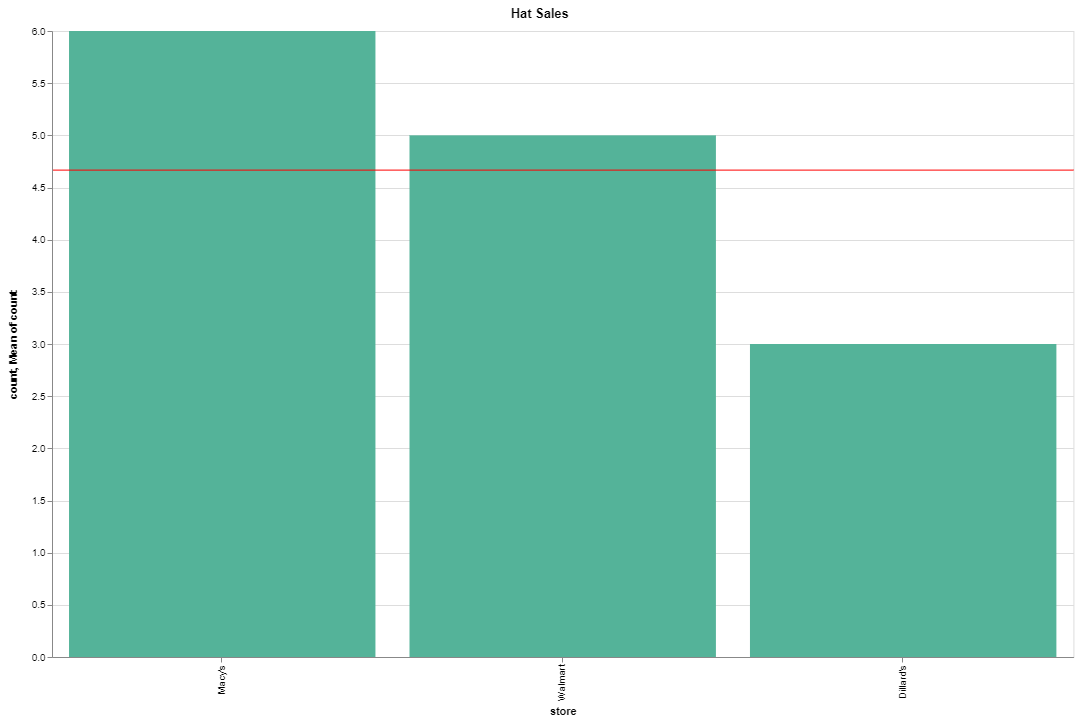 那么水平規則將僅是前 3 家商店的平均值。相反,我們需要向 Elasticsearch 請求添加另一個指標聚合,該請求計算商店出售的帽子的全球平均值 (
那么水平規則將僅是前 3 家商店的平均值。相反,我們需要向 Elasticsearch 請求添加另一個指標聚合,該請求計算商店出售的帽子的全球平均值 ( 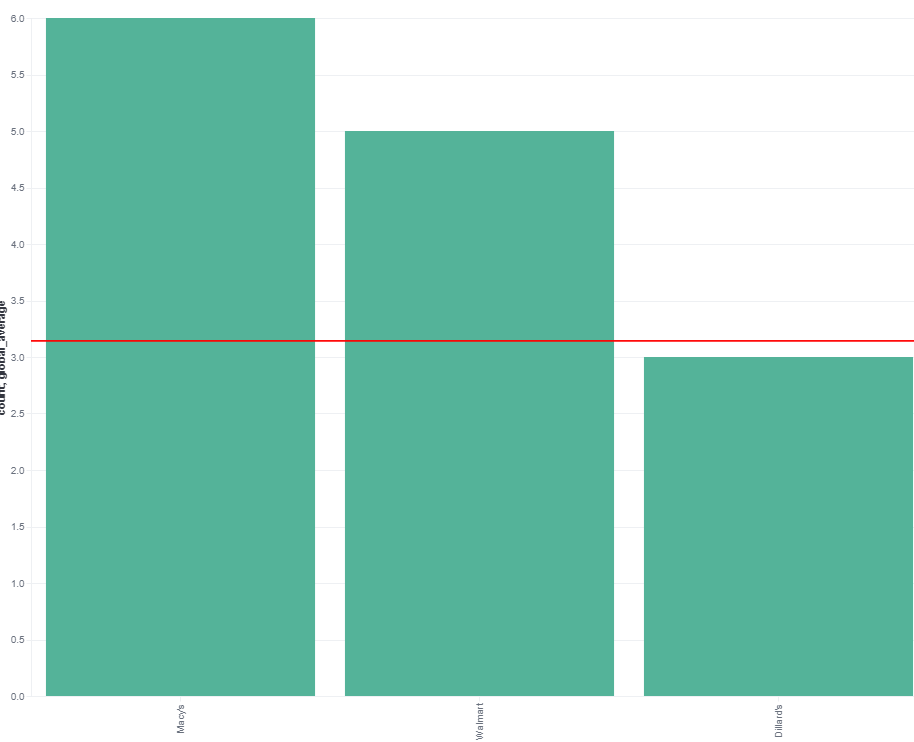
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/335860.html
上一篇:在KibanaDevTools中創建一個欄位屬性標記為“未分析”的新索引
下一篇:Kibana搜索模式問題