我想變異一列 h,如果它包含 1,它包含各自的列名 [A,B,C,D]
import pandas as pd
dfz = pd.DataFrame({'A' : [1,0,0,1,0,0],
'B' : [1,0,0,1,0,1],
'C' : [1,0,0,1,3,1],
'D' : [1,0,0,1,0,0]})
dfz['h'] = dfz.loc[:, 'A':'D'].replace(1,pd.Series(dfz.columns,dfz.columns))
預期輸出
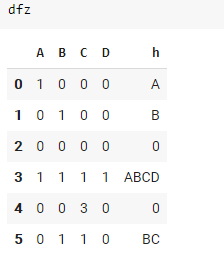
uj5u.com熱心網友回復:
使用DataFrame.dot帶有過濾列,并通過比較值1,最后使用Series.replace與空間:
#filtered columns
dfz['h'] = dfz.loc[:, 'A':'D'].eq(1).dot(dfz.loc[:, 'A':'D'].columns).replace('', '0')
#filtered by list
cols = ['A','B','C','D']
dfz['h'] = dfz[cols].eq(1).dot(pd.Index(cols)).replace('', '0')
print (dfz)
A B C D h
0 1 1 1 1 ABCD
1 0 0 0 0 0
2 0 0 0 0 0
3 1 1 1 1 ABCD
4 0 0 3 0 0
5 0 1 1 0 BC
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/336069.html