我正在處理包含經度和緯度值的資料集。
我使用 DBSCAN 將這些值轉換為集群。
然后我繪制了集群作為一個健全性檢查。
我明白了:
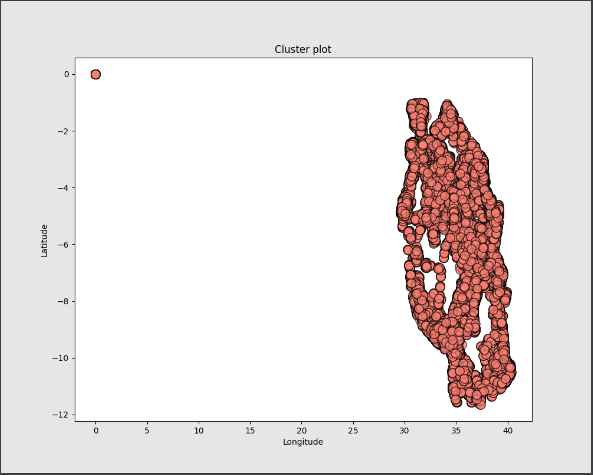
(0, 0) 處的點顯然是一個問題。
所以我運行這段代碼來捕獲哪些行有問題。
a = df3.loc[(df3['latitude'] < 0.01) & (df3['longitude'] < 0.01)].index
print(a) # 1812 rows with 0.0 longitude and -2e-08 latitude
我有 1812 行缺少資料,在源檔案中全部表示為 0.0 經度和 -2e-08 緯度。
我正在討論一些插補策略,但首先我想用 np.NA 或 np.nan 替換 0.0 和 -2e-08 值,以便我可以將 fillna() 用于我最終決定做的任何事情。
我都試過:
df3.replace((df3['longitude'] == 0.0), pd.NA, inplace=True)
df3.replace((df3['latitude'] == -2e-08), pd.NA, inplace=True)
print(df3['longitude'].value_counts(dropna=False), '\n')
print(df3['latitude'].value_counts(dropna=False))
和
df3.replace((df3['longitude'] < 0.01), pd.NA, inplace=True)
df3.replace((df3['latitude'] < 0.01), pd.NA, inplace=True)
print(df3['longitude'].value_counts(dropna=False), '\n')
print(df3['latitude'].value_counts(dropna=False))
在這兩種情況下,現有值保持不變,即沒有發生所需的 pd.NA 替換。
用 pd.NA 或 np.nan 替換緯度和經度列中不需要的 1812 值的正確程式是什么,因為我只是計劃估算某些東西來替換空值。
uj5u.com熱心網友回復:
試試這個:
df3['longitude'] = df3['longitude'].apply(lambda x:np.nan if x == 0.0 else x)
df3['latitude'] = df3['latitude'].apply(lambda x:np.nan if x==-2e-08 else x)
print(df3['longitude'].value_counts(dropna=False), '\n')
print(df3['latitude'].value_counts(dropna=False))
uj5u.com熱心網友回復:
舉個例子
import numpy as np
import pandas as pd
a = [1, 2, 0.0, -2e-08]
b = [1, 2, 0.0, -2e-08]
df = pd.DataFrame(zip(a, b))
df.columns = ['lat', 'long']
df.long = df.long.apply(lambda x:np.nan if x == 0.0 else x)
df.lat = df.lat.apply(lambda x:np.nan if x==-2e-08 else x)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/336071.html