給定 2 個資料幀,如何僅將唯一行附加到第二個 df 的主 df 中?
例如,給定這兩個資料幀:
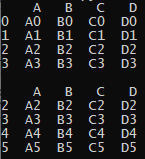
...我怎樣才能得到這個結果?:
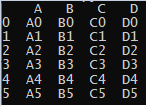
我想以某種方式涉及索引,因為我的應用程式將使用 datetimeindex。一個可重現的代碼,我的連接嘗試如下:
import pandas as pd
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
print(df1)
print()
df2 = pd.DataFrame(
{
"A": ["A2", "A3", "A4", "A5"],
"B": ["B2", "B3", "B4", "B5"],
"C": ["C2", "C3", "C4", "C5"],
"D": ["D2", "D3", "D4", "D5"],
},
index=[2, 3, 4, 5],
)
print(df2)
print()
result = pd.concat([df1, df2], join="inner", ignore_index=False)
print(result)
uj5u.com熱心網友回復:
只是merge在你的情況下
out = df1.merge(df2,how='outer')
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
uj5u.com熱心網友回復:
連接后,您可以使用 drop_duplicate() 函式洗掉重復項。
import pandas as pd
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
print(df1)
print()
df2 = pd.DataFrame(
{
"A": ["A2", "A3", "A4", "A5"],
"B": ["B2", "B3", "B4", "B5"],
"C": ["C2", "C3", "C4", "C5"],
"D": ["D2", "D3", "D4", "D5"],
},
index=[2, 3, 4, 5],
)
print(df2)
print()
result = pd.concat([df1, df2], join="inner", ignore_index=False)
result = result.drop_duplicates()
print(result)
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/336090.html
上一篇:如何隨機填充分類資料的NaN?