我將一個 csv 檔案匯入到熊貓資料集(phyton)
| 引數ID | 設備ID | 設定值 | |
|---|---|---|---|
| 0 | 1 | 1號線 | 217.0 |
| 1 | 2 | 1號線 | 3.0 |
| 2 | 4 | 1號線 | 0.0 |
| 3 | 6 | 1號線 | 17.0 |
| 4 | 2 | 2號線 | 3.0 |
| 5 | 4 | 2號線 | 0.0 |
| 6 | 6 | 2號線 | 17.0 |
我想將其更改為另一個表,在那里我可以看到差異/行
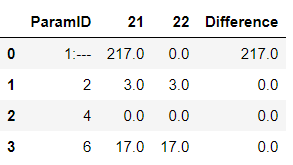
| 引數ID | LINE1 | LINE2 | 區別 | |
|---|---|---|---|---|
| 0 | 1:--- | 217.0 | / | 217.0 |
| 1 | 2 | 3.0 | 3.0 | 0 |
| 2 | 4 | 0.0 | 0.0 | 0 |
| 3 | 6 | 17.0 | 17.0 | 0 |
我試過了,pivot1=pd.pivot_table(new_df, index = 'Region')但這給出了一個錯誤:“KeyError: 'Region'”
關于給定解決方案的附加問題:如果第一個表中的“Line1”和“Line2”其中的數字(21 和 22)為什么會df1['Difference'] = (df1['21'].replace(np.nan,0) - df1['22'].replace(np.nan,0))在 21上給出 KeyError
uj5u.com熱心網友回復:
您可以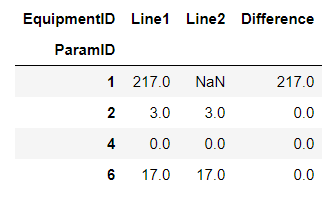
更新完整答案(修改表格):
df1 = df.pivot('ParamID','EquipmentID','SetValue').reset_index()
df1['Difference'] = (df1['Line1'].replace(np.nan,0) - df1['Line2'].replace(np.nan,0))
df1['ParamID'] = np.where((np.isnan(df1.Line1)) | (np.isnan(df1.Line2)), df1['ParamID'].astype(str) ':---' , df1['ParamID'])
df1.replace(np.nan,0,inplace=True)
df1.columns.name=''
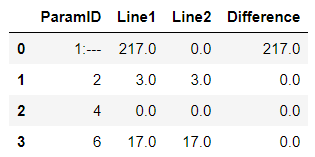
回答更新的問題
新資料:
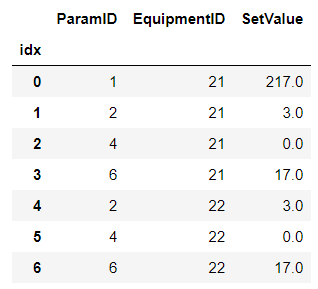
第1步:
df1 = df.pivot('ParamID','EquipmentID','SetValue').reset_index()
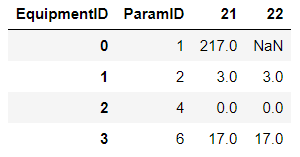
第2步:
df1['Difference'] = (df1.iloc[:,1].replace(np.nan,0) - df1.iloc[:,2].replace(np.nan,0))
df1['ParamID'] = np.where((np.isnan(df1.iloc[:,1])) | (np.isnan(df1.iloc[:,2])), df1['ParamID'].astype(str) ':---' , df1['ParamID'])
df1.replace(np.nan,0,inplace=True)
df1.columns.name=''
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/336101.html
上一篇:pd.read_csv有錯誤:第52行預期有2個欄位,看到3
下一篇:如何剝離列并合并?