我正在嘗試使用 selenium 對資訊進行網路報廢,代碼適用于單個專案,但是當我通過串列時,我得到了以下輸出,
實際產量

預期輸出
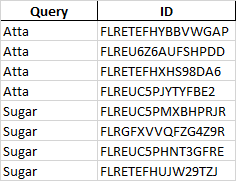
term=["Atta","Sugar"]
def get_link(term,page):
for term in term:
pin(Pincode)
grocery="https://www.flipkart.com/search?q={}&otracker=search&otracker1=search&marketplace=GROCERY&as-show=on&as=off"
term = term.replace(' ', ' ')
stem = grocery.format(term)
url_template = stem '&as-pos=1&as-type=HISTORY&as-backfill=on&page='
next=url_template str(page)
#print(next)
return next
def PID():
for page in range(1,5):
path=get_link(term,page)
driver.get(path)
id=driver.find_elements_by_xpath('//div[@data-id]')
for i in id:
results=i.get_attribute('data-id')
#print(results)
PIDs.append(results)
Search_Term.append(term)
PID()
ID={'Query':Search_Term,'PID_s':PIDs}
Output=pd.DataFrame(ID)
print(Output)
uj5u.com熱心網友回復:
將for loopforterm放在PID函式內部可能會更好。像下面這樣嘗試一次:
terms = ["Atta", "Sugar"]
def get_link(term, page):
# Not sure what pin(Pincode) line is doing
grocery = "https://www.flipkart.com/search?q={}&otracker=search&otracker1=search&marketplace=GROCERY&as-show=on&as=off"
term = term.replace(' ', ' ')
#print(term)
stem = grocery.format(term)
url_template = stem '&as-pos=1&as-type=HISTORY&as-backfill=on&page='
next = url_template str(page)
# print(next)
return next
def PID():
for term in terms:
for page in range(1, 5):
path = get_link(term, page)
driver.get(path)
id = driver.find_elements_by_xpath('//div[@data-id]')
for i in id:
results = i.get_attribute('data-id')
print(f"{term}:{results}")
# PIDs.append(results)
# Search_Term.append(term)
PID()
Atta:FLRFDPRFNGYJ95KD
Atta:FLRETEFHENWKNJQE
...
Sugar:SUGG4SFGSP6TCQ48
Sugar:SUGEUD25B6YCCNGM
...
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/338313.html
下一篇:從抓取的資料中洗掉頁眉和頁腳部分