我有兩個DF,我想將它們組合在一起,但是我必須檢查資料是否在日期范圍內。我的第一個 DF:
ID <- c(111,222,333,444,555,666)
DT_START_HOSP <- as.Date(c('2021/01/07','2021/01/11','2021/01/21','2021/01/21','2021/01/21','2021/01/22'))
DT_END_HOSP <- as.Date(c('2021/01/10','2021/01/20','2021/01/25','2021/02/01','2021/01/29','2021/02/02'))
HOSP <- data.frame(ID,DT_START_HOSP,DT_END_HOSP)
我的第二個DF:
ID <- c(1010,1010,1010,222,222,5050,5050,666,666)
DT_START_OUT <- as.Date(c('2021/01/01','2021/01/11','2021/01/30','2021/01/02','2021/01/15','2021/03/15','2021/04/20','2021/01/25','2021/01/28'))
DT_END_OUT <- as.Date(c('2021/01/01','2021/01/11','2021/01/30','2021/01/02','2021/01/15','2021/03/20','2021/04/20','2021/01/25','2021/01/30'))
OUT <- data.frame(ID,DT_START_OUT,DT_END_OUT)
與列(DT_START_HOSP and DT_END_HOSP)相比,我只想選擇列范圍內的“ID” (DT_START_OUT and DT_END_OUT)。因此,我期望的結果是:
ID <- c(111,222,333,444,555,666,666)
DT_START_HOSP <- as.Date(c('2021/01/07','2021/01/11','2021/01/21','2021/01/21','2021/01/21',' 2021/01/22','2021/01/22'))
DT_END_HOSP <- as.Date(c('2021/01/10','2021/01/20','2021/01/25','2021/02/01','2021/01/29',' 2021/02/02','2021/02/02'))
DT_START_OUT <- as.Date(c('','2021/01/15','','','','2021/01/25','2021/01/28'))
DT_END_OUT <- as.Date(c('','2021/01/15','','','','2021/01/25','2021/01/30'))
HOSP <- data.frame(ID,DT_START_HOSP,DT_END_HOSP,DT_START_OUT,DT_END_OUT)
但是,我使用了此代碼(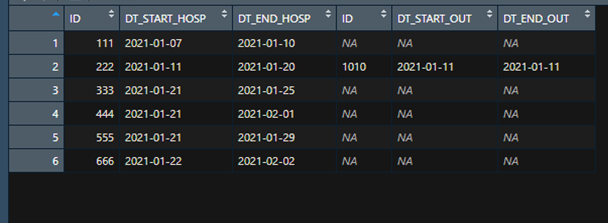
是否可以根據日期范圍執行此連接?
uj5u.com熱心網友回復:
您的邏輯不像“之間”那么簡單,因為您似乎想要任何型別的重疊,無論是超集還是其他。為此,我們需要一個稍微不同的查詢(并且應該包括ID在左連接中,我推斷)。
sqldf::sqldf("
select h.*, o.DT_START_OUT, o.DT_END_OUT
from HOSP h
left join OUT o on h.ID = o.ID
and h.DT_START_HOSP < o.DT_END_OUT
and h.DT_END_HOSP > o.DT_START_OUT")
# ID DT_START_HOSP DT_END_HOSP DT_START_OUT DT_END_OUT
# 1 111 2021-01-07 2021-01-10 <NA> <NA>
# 2 222 2021-01-11 2021-01-20 2021-01-15 2021-01-15
# 3 333 2021-01-21 2021-01-25 <NA> <NA>
# 4 444 2021-01-21 2021-02-01 <NA> <NA>
# 5 555 2021-01-21 2021-01-29 <NA> <NA>
# 6 666 2021-01-22 2021-02-02 2021-01-25 2021-01-25
# 7 666 2021-01-22 2021-02-02 2021-01-28 2021-01-30
(感謝您修復上一個問題和本問題初稿中的資料。為了記錄,您可能需要這個,一些方便的代碼,可以很好地處理不一致/不同格式的日期向量。)
uj5u.com熱心網友回復:
如果您只要求獲取間隔(開始-結束日期)重疊的樣本,則此解決方案可能對您有所幫助。但是,我使用了 dplyr 和 lubridate 包而不是 sqldf。Dplyr 和 sqldf 包的作業原理非常相似,因此您可以調整解決方案。
library(dplyr)
library(lubridate)
HOSP <- HOSP %>% mutate(INT = interval(DT_START_HOSP,DT_END_HOSP))
OUT <- OUT %>% mutate(INT = interval(DT_START_OUT,DT_END_OUT))
df <- left_join(HOSP,OUT,by='ID') %>%
filter(!is.na(DT_START_OUT),
INT.y %within% INT.x) %>%
select(ID,DT_START_HOSP,DT_END_HOSP,DT_START_OUT,DT_END_OUT)
如果不應用select(),可以看到流程。我為采用開始和結束日期的兩個資料幀創建了間隔,然后檢查與管道 %within% 的重疊以及過濾與 !is.na() 不匹配的 id。OUT df 的間隔看起來比 HOSP 的小,所以我在 HOSP (INT.x) 中檢查了它們 (INT.y)。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/338777.html
標籤:r