我正在使用 SQL Server 并試圖找出一起購買次數最多的前 2 款產品
這是產品表
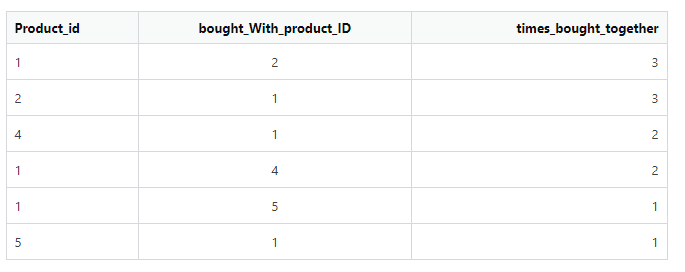
我希望它顯示如下:

我試過了
SELECT TOP 2 Product_Id, bought_with_Product_Id, times_bought_together
FROM PRODUCT
GROUP BY Product_Id, bought_with_Product_Id, times_bought_together
也試過這個
SELECT TOP 2 *
FROM Product
WHERE times_bought_together = (SELECT MAX(times_bought_together) FROM product)
AND Product_Id <> bought_with_Product_Id
它回傳

如何使 product_id 和 purchase_with_product_Id 行不重疊
uj5u.com熱心網友回復:
您可以使用NOT EXISTS測驗排除重復的行,例如
declare @Test table (id int, otherId int, times int);
insert into @Test (id, otherId, times)
values
(1,2,3),
(2,1,3),
(4,1,2),
(1,4,2),
(1,5,1),
(5,1,1);
select top 2 *
from @Test T1
where not exists (
select 1
from @Test T2
where T1.id = T2.otherId
and T1.otherId = T2.id
-- Keep the duplicate with the lower id
and T2.id < T1.id
);
回傳:
| ID | 其他ID | 次 |
|---|---|---|
| 1 | 2 | 3 |
| 1 | 4 | 2 |
注意:為您的測驗資料提供 DDL DML(如此處所示)使人們更容易回答您的問題。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/338944.html
標籤:sql sql-server 查询语句 重复