我想從library(drc). 特別是,我正在努力如何準備好我的 y 軸。
我制作了一個資料框(df)來幫助澄清我想做的事情。
df <- read.table("https://pastebin.com/raw/TZdjp2JX", header=T)
為今天的練習打開必要的庫
library(drc)
library(ggplot2)
讓我們假設我喜歡蜂鳥,并用不同濃度的糖進行實驗,目的是看看哪種濃度最適合蜂鳥。因此,我在封閉環境(此處為“房間”列)中進行了一項實驗,其中有 4 種不同的糖濃度(列濃度),每個濃度有 10 只鳥。我還并行運行每個實驗 4 個重復,這就是為什么有 4 個“房間”。36 小時后(“時間”列),我進入房間,檢查有多少只鳥幸存下來,創建一個“是/否”變數,或 1 & 0(這里,這是我的“狀態”列),其中 1= =生存,0==死亡。
有了這個資料集,我特意讓大多數人在濃度 0 下存活,50% 在濃度 1 下存活,25% 在濃度 2 下存活,只有 10% 在濃度 3 下存活。
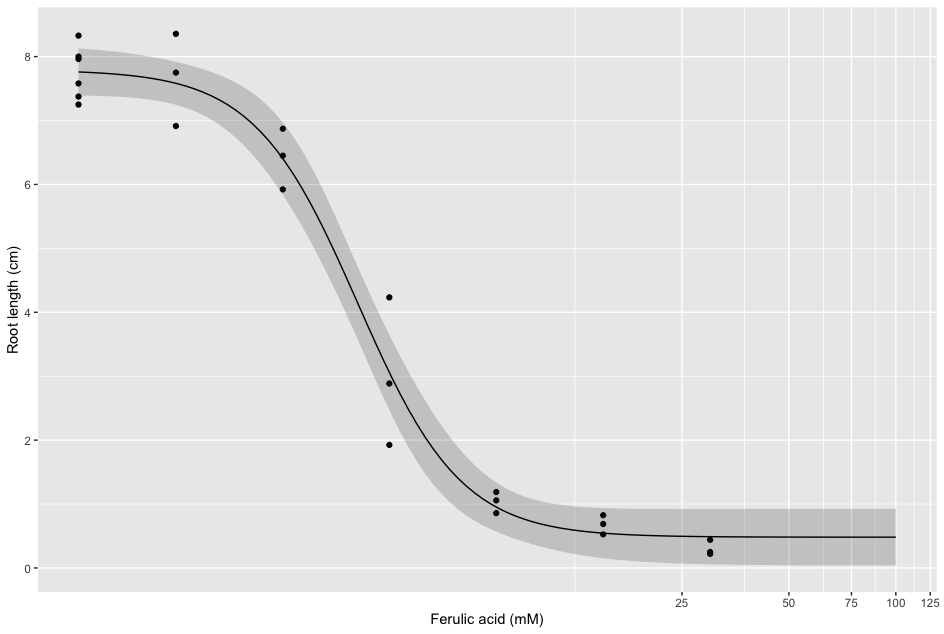
我遇到的第一個問題是:如何將從“狀態”列生成的 y 軸轉換為百分比?我在做 kaplan-meier 生存曲線時已經這樣做了,但不幸的是,這在這里不起作用。顯然,這應該列應該從 0% 到 100%(我們可以將列稱為“死亡率”)。成功后,我想做一個如下圖的劑量反應曲線(我在網上找到了這個例子,這里直接復制來使用一個例子。它來自R中包含的黑麥草資料集)
ryegrass.LL.4 <- drm(rootl ~ conc, data = ryegrass, fct = LL.3())
我必須承認,接下來的代碼步驟讓我有點困惑。
# new dose levels as support for the line
newdata <- expand.grid(conc=exp(seq(log(0.5), log(100), length=100)))
# predictions and confidence intervals
pm <- predict(ryegrass.LL.4, newdata=newdata, interval="confidence")
# new data with predictions
newdata$p <- pm[,1]
newdata$pmin <- pm[,2]
newdata$pmax <- pm[,3]
# plot curve
# need to shift conc == 0 a bit up, otherwise there are problems with coord_trans
ryegrass$conc0 <- ryegrass$conc
ryegrass$conc0[ryegrass$conc0 == 0] <- 0.5
# plotting the curve
ggplot(ryegrass, aes(x = conc0, y = rootl))
geom_point()
geom_ribbon(data=newdata, aes(x=conc, y=p, ymin=pmin, ymax=pmax), alpha=0.2)
geom_line(data=newdata, aes(x=conc, y=p))
coord_trans(x="log")
xlab("Ferulic acid (mM)") ylab("Root length (cm)")
In the end, I would like to generate a similar curve, but with mortality on the y-axis, from 0-100 (starting low, going high) and also display the confidence intervals in a shaded grey area around the regression line. Meaning, my first step of code should like something like the following:
model <- drc(mortality ~ Concentration, data=df, fct = LL.3()) But I'm lost on the "mortality" creation part, and a little bit on the next step with ggplot
Could anyone help me achieve this? From the example from ryegrass, I'm perplexed how to translate this to be helpful for my pretend dataset. I hope someone here is able to help me solve this issue! Many thanks, and I appreciate any feedback if there are other ways I should have my dataset structured, etc.
-Andy
uj5u.com熱心網友回復:
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(ggplot2)
library(drc)
#> Loading required package: MASS
#>
#> Attaching package: 'MASS'
#> The following object is masked from 'package:dplyr':
#>
#> select
#>
#> 'drc' has been loaded.
#> Please cite R and 'drc' if used for a publication,
#> for references type 'citation()' and 'citation('drc')'.
#>
#> Attaching package: 'drc'
#> The following objects are masked from 'package:stats':
#>
#> gaussian, getInitial
df <- read.table("https://pastebin.com/raw/sH5hCr2J", header=T)
制作mortalityor 就像我在這里survival所做的那樣,可以通過dplyr包裝輕松完成。這將有助于執行許多計算。您似乎對計算四個房間(或重復)中每個濃度的存活百分比感興趣。所以第一步就是按這些列對資料進行分組,然后計算我們想要的統計量。
df_calc <- df %>%
group_by(Concentration, room) %>%
summarise(surv = sum(Status)/n())
#> `summarise()` has grouped output by 'Concentration'. You can override using the `.groups` argument.
我不知道濃度是否代表任意濃度水平,所以我繼續進行以下假設:
- 1 == 較高水平的糖分,2 == 較低水平的糖分
- 濃度在對數空間中編碼 - 所以我轉換為線性空間
df_calc <- mutate(df_calc, conc = exp(-Concentration))
需要明確的是,該conc變數只是我試圖獲得接近實驗中真實已知濃度的東西。如果您的資料具有真實濃度,則不要介意此計算。
df_calc
#> # A tibble: 12 x 4
#> # Groups: Concentration [3]
#> Concentration room surv conc
#> <int> <int> <dbl> <dbl>
#> 1 1 1 0.5 0.368
#> 2 1 2 0.4 0.368
#> 3 1 3 0.5 0.368
#> 4 1 4 0.6 0.368
#> 5 2 1 0 0.135
#> 6 2 2 0.4 0.135
#> 7 2 3 0.2 0.135
#> 8 2 4 0.4 0.135
#> 9 3 1 0.2 0.0498
#> 10 3 2 0 0.0498
#> 11 3 3 0 0.0498
#> 12 3 4 0.2 0.0498
mod <- drm(surv ~ conc, data = df_calc, fct = LL.3())
創建新的conc資料點
newdata <- data.frame(conc = exp(seq(log(0.01), log(10), length = 100)))
編輯
為了回應您的評論,我將解釋上述代碼塊。同樣,conc變數預計為單位濃度。在這個假設的情況下,我們有三個濃度水平c(0.049, 0.135, 0.368)。為簡潔起見,假設單位為mg of sugar/ml of water。我們的模型適合這三個劑量水平,每個劑量水平有 4 個資料點。如果我們愿意,我們可以繪制這些級別之間的曲線c(0.049, 0.368),但在這個例子中,我選擇了c(0.01, 10) mg/ml as the domain to plot on. This was just so that we could visualize where the curve would end up based on the model fit. In short, you choose the range that you are interested in most. As I show later - even though we can choose data points outside the range of the experimental data, the confidence intervals are extremely large indicating the model will be unhelpful for those points.
The reason behind casting these values with the log() function is to ensure that we are sampling points that look evenly distributed on a log10 scale (most does response curves are plotted with this transformation). Once we get the sequence of 100 points, we use exp() to return back to the linear space (which our model was fit on). These values are then used in the predict function as the new dose levels in conjunction with the fitted model.
All this is saved into newdata variable which allows for the plotting of the line and the confidence intervals.
Use the model and the generated data points to
predict a new surv value as well as the upper and lower bound
newdata <- cbind(newdata,
suppressWarnings(predict(mod, newdata = newdata, interval="confidence")))
plot with ggplot2
ggplot(df_calc, aes(conc))
geom_point(aes(y = surv))
geom_ribbon(aes(ymin = Lower, ymax = Upper), data = newdata, alpha = 0.2)
geom_line(aes(y = Prediction), data = newdata)
scale_x_log10()
coord_cartesian(ylim = c(0, 1))
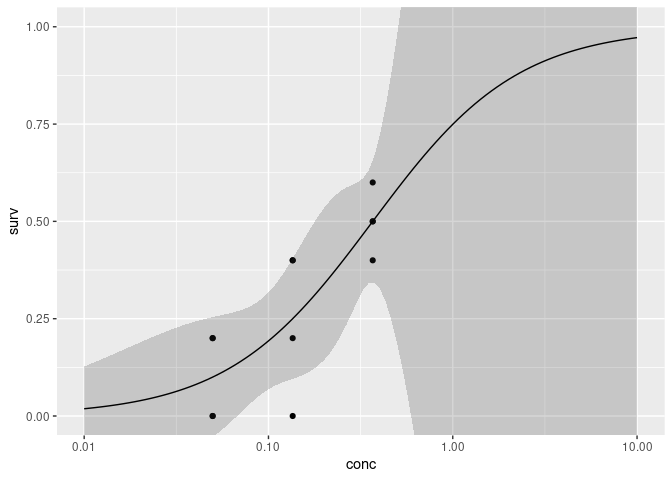
As you may notice, the confidence intervals increase greately when we try and predict ranges that has no data.
由reprex 包(v1.0.0)于 2021 年 10 月 27 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/341816.html