我正在嘗試創建一個餅圖來可視化 9 個屬的豐度百分比。然而,標簽都聚集在一起。我該如何補救?代碼包含如下:
generaabundance2020 <- c(883, 464, 1948, 1177, 2607, 962, 2073, 620, 2670)
genera2020 <- c("Andrena", "Ceratina", "Halictus",
"Hesperapis", "Lasioglossum", "Melissodes",
"Osmia", "Panurginus", "Other")
generabreakdown2020 <- data.frame(group = genera2020, value = generaabundance2020)
gb2020label <- generabreakdown2020 %>%
group_by(value) %>% # Variable to be transformed
count() %>%
ungroup() %>%
mutate(perc = `value` / sum(`value`)) %>%
arrange(perc) %>%
mutate(labels = scales::percent(perc))
generabreakdown2020 %>%
ggplot(aes(x = "", y = value, fill = group))
geom_col()
coord_polar("y", start = 0)
theme_void()
geom_label_repel(aes(label = gb2020label$labels), position = position_fill(vjust = 0.5),
size = 5, show.legend = F, max.overlaps = 50)
guides(fill = guide_legend(title = "Genera"))
scale_fill_manual(values = c("brown1", "chocolate1",
"darkgoldenrod1", "darkgreen",
"deepskyblue", "darkslateblue",
"darkorchid4", "hotpink1",
"lightpink"))
產生以下結果:
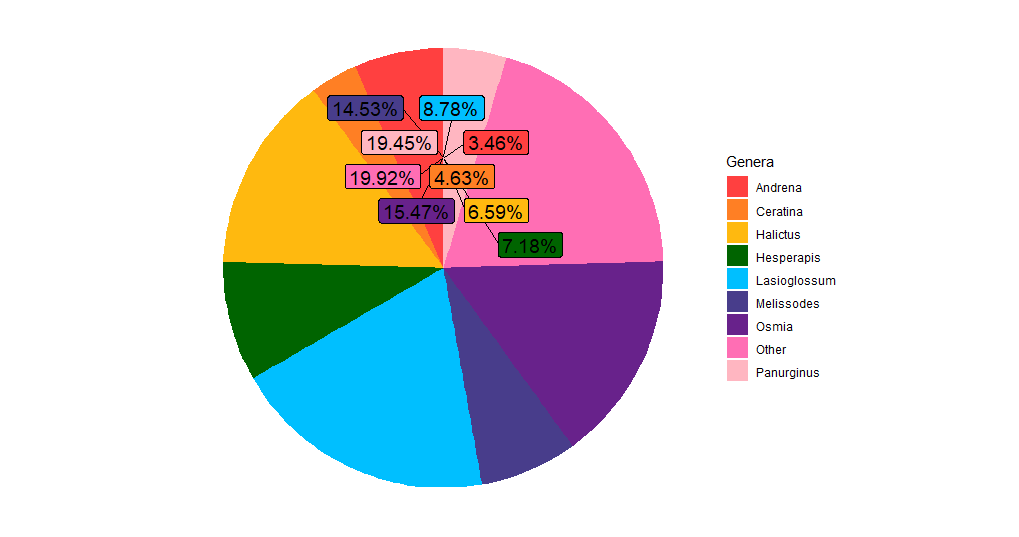
uj5u.com熱心網友回復:
您沒有向我們提供您要使用的資料,所以我在ggplot2::mpg這里使用。
library(tidyverse)
library(ggrepel)
mpg_2 <-
mpg %>%
slice_sample(n = 20) %>%
count(manufacturer) %>%
mutate(perc = n / sum(n)) %>%
mutate(labels = scales::percent(perc)) %>%
arrange(desc(manufacturer)) %>%
mutate(text_y = cumsum(n) - n/2)
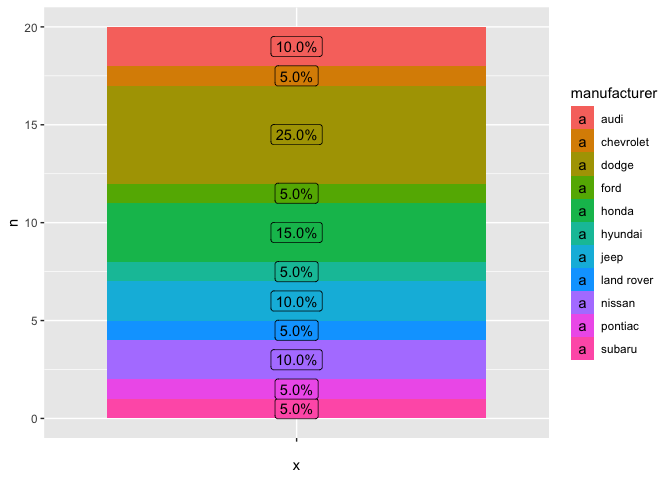
沒有極坐標的圖表
mpg_2 %>%
ggplot(aes(x = "", y = n, fill = manufacturer))
geom_col()
geom_label(aes(label = labels, y = text_y))
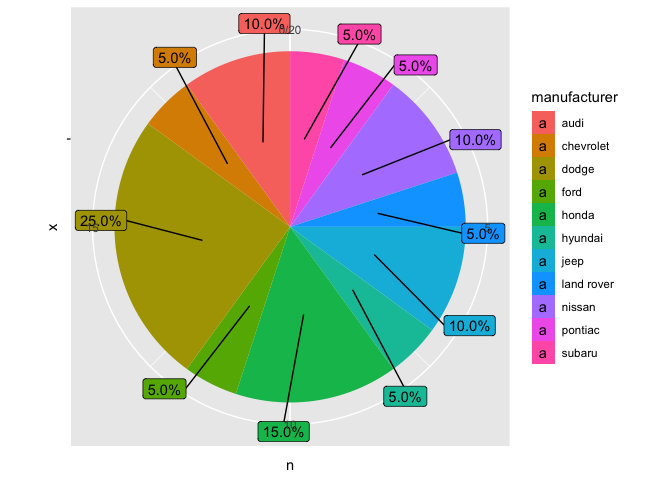
帶有極坐標的圖表和 geom_label_repel
mpg_2 %>%
ggplot(aes(x = "", y = n, fill = manufacturer))
geom_col()
geom_label_repel(aes(label = labels, y = text_y),
force = 0.5,nudge_x = 0.6, nudge_y = 0.6)
coord_polar(theta = "y")
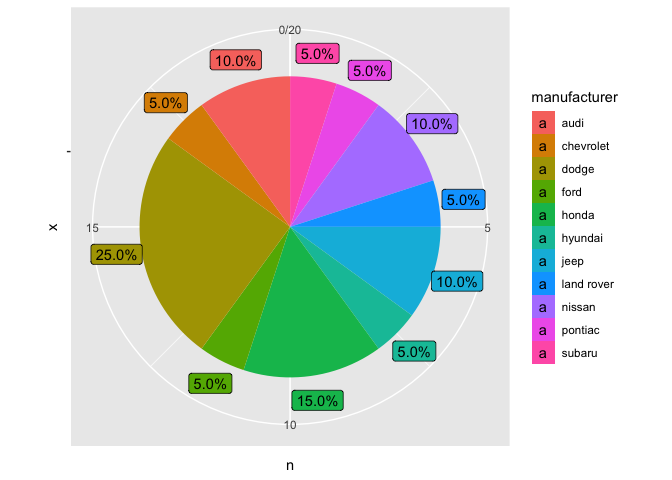
但也許您的資料不夠密集,需要排斥?
mpg_2 %>%
ggplot(aes(x = "", y = n, fill = manufacturer))
geom_col()
geom_label(aes(label = labels, y = text_y), nudge_x = 0.6)
coord_polar(theta = "y")
由reprex 包(v2.0.1)于 2021 年 10 月 26 日創建
uj5u.com熱心網友回復:
感謝您添加資料。
您的代碼中有一些錯誤。主要的一點是您沒有預先計算放置標簽的位置(在text_y變數中完成)。該變數需要作為 y 美學傳遞geom_label_repel。
第二個是您不再需要,
group_by(value) %>% count() %>% ungroup()因為您提供的資料已經匯總。
library(tidyverse)
library(ggrepel)
generaabundance2020 <- c(883, 464, 1948, 1177, 2607, 962, 2073, 620, 2670)
genera2020 <- c("Andrena", "Ceratina", "Halictus", "Hesperapis", "Lasioglossum", "Melissodes", "Osmia", "Panurginus", "Other")
generabreakdown2020 <- data.frame(group = genera2020, value = generaabundance2020)
gb2020label <-
generabreakdown2020 %>%
mutate(perc = value/ sum(value)) %>%
mutate(labels = scales::percent(perc)) %>%
arrange(desc(group)) %>% ## arrange in the order of the legend
mutate(text_y = cumsum(value) - value/2) ### calculate where to place the text labels
gb2020label %>%
ggplot(aes(x = "", y = value, fill = group))
geom_col()
coord_polar(theta = "y")
geom_label_repel(aes(label = labels, y = text_y),
nudge_x = 0.6, nudge_y = 0.6,
size = 5, show.legend = F)
guides(fill = guide_legend(title = "Genera"))
scale_fill_manual(values = c("brown1", "chocolate1",
"darkgoldenrod1", "darkgreen",
"deepskyblue", "darkslateblue",
"darkorchid4", "hotpink1",
"lightpink"))
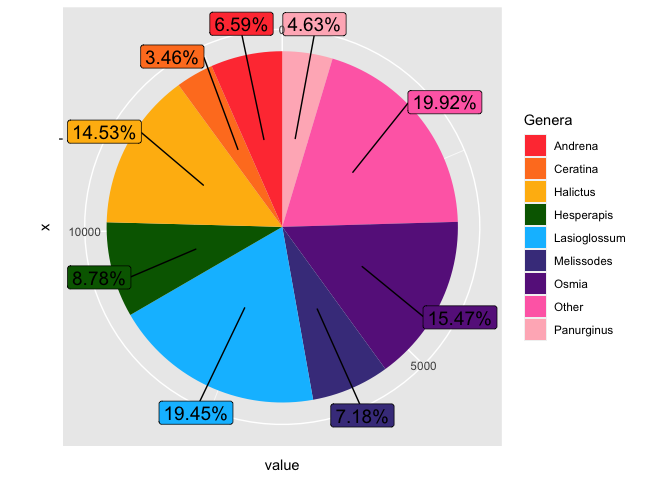
如果你想按照頻率的降序排列,你應該記住也要將組變數的因子水平設定為相同的順序。
gb2020label <-
generabreakdown2020 %>%
mutate(perc = value/ sum(value)) %>%
mutate(labels = scales::percent(perc)) %>%
arrange(desc(perc)) %>% ## arrange in descending order of frequency
mutate(group = fct_rev(fct_inorder(group))) %>% ## also arrange the groups in descending order of freq
mutate(text_y = cumsum(value) - value/2) ### calculate where to place the text labels
gb2020label %>%
ggplot(aes(x = "", y = value, fill = group))
geom_col()
coord_polar(theta = "y")
geom_label_repel(aes(label = labels, y = text_y),
nudge_x = 0.6, nudge_y = 0.6,
size = 5, show.legend = F)
guides(fill = guide_legend(title = "Genera"))
scale_fill_manual(values = c("brown1", "chocolate1",
"darkgoldenrod1", "darkgreen",
"deepskyblue", "darkslateblue",
"darkorchid4", "hotpink1",
"lightpink"))
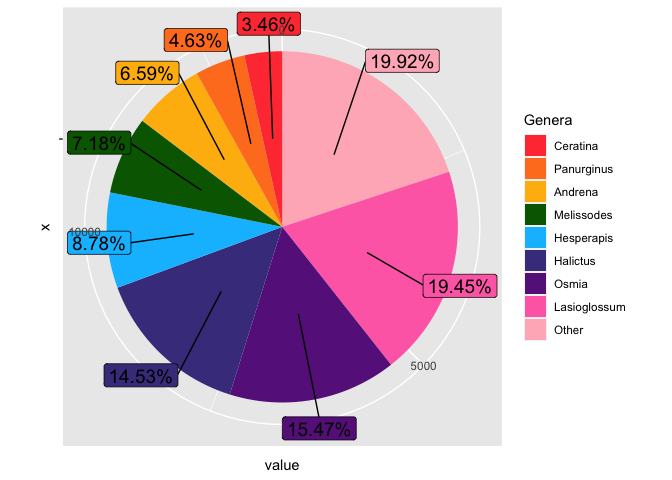
由reprex 包(v2.0.1)于 2021 年 10 月 27 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/341820.html
上一篇:geom_line不顯示線