我最近發現了一個有趣的問題,看起來像這樣:
有一種枯燥的排序演算法,它從陣列中取第一個數字,它找到一個比第一個元素低 1 的元素(或者在沒有較低元素的情況下取最高元素),并將其放在最前面。將索引為 x(從 0 開始計數)的元素放在前面的成本等于其索引。它繼續這個程序,直到陣列被排序。任務是計算排序所有n的成本!從 1 到 n 的數字排列。答案可能很大,所以答案應該是模 m (n 和 m 在輸入中給出)
例子:
Input (n,m): 3 40
Answer: 15
There are permutations of numbers from 1 to 3. The costs of sorting them are:
(1,2,3)->0
(1,3,2)->5
(2,1,3)->1
(2,3,1)->2
(3,1,2)->4
(3,2,1)->3
sum = 15
我的程式生成所有可能的陣列并一一排序。它的復雜度是 O(n!*n^2),太高了。我被我所有的想法和這個蠻力解決方案困住了。
我還發現了一些有趣的事情:
- 當我按這些成本的數量對排列排序的成本進行分組時,我得到了一個奇怪的數字:n=7
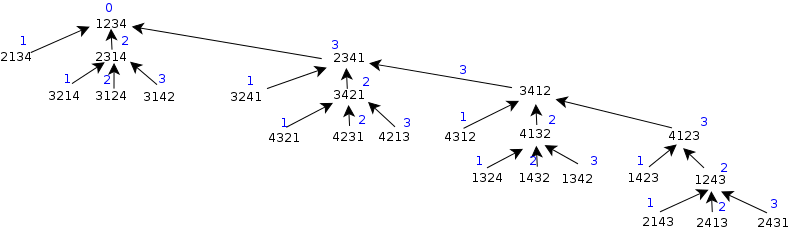
現在,請注意
如果節點==1234 那么成本(節點)= 0
如果 node!=1234 那么 cost(node) = blue_label(node) cost(parent)
您需要的是制定反向規則來生成樹。也許使用一些記憶技術來避免每次重新計算成本。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/347688.html