我試圖想出一種以特定方式可視化一些李克特量表資料的方法。我什至不確定如何偽造它的樣子,所以我希望我的解釋就足夠了。
我有以下(假)資料:
n題,每題5個答案(非常同意、同意、不同意、非常不同意、不知道)
我想沿著中心軸可視化資料(理想情況下使用 ggplot),這樣兩個“同意”的答案在左邊,兩個“不同意”的答案在右邊,然后在一個單獨的塊上一邊,一個代表“不知道”的塊。它應該大致如下所示:
Q1: ***** |------!! ?????
Q2: **** |----!!!!!! ???????
Q3: ** |---!!! ??????????
*: strongly agree, : agree, -: don't agree, !:strongly disagree, ?: don't know
如您所見,這種表示允許比較同意和不同意的實際數量,而無需隱藏“不知道”的數量。我遇到的問題是如何為不知道的人創建第二個元素。有任何想法嗎?
下面是一些假資料:
structure(list(Q = structure(1:3, .Label = c("Q1", "Q2", "Q3"
), class = "factor"), SA = c(25, 18, 12), A = c(30, 25, 15),
DA = c(25, 20, 25), SDA = c(10, 18, 25), DK = c(10, 19, 23
)), row.names = c(NA, -3L), class = "data.frame")
uj5u.com熱心網友回復:
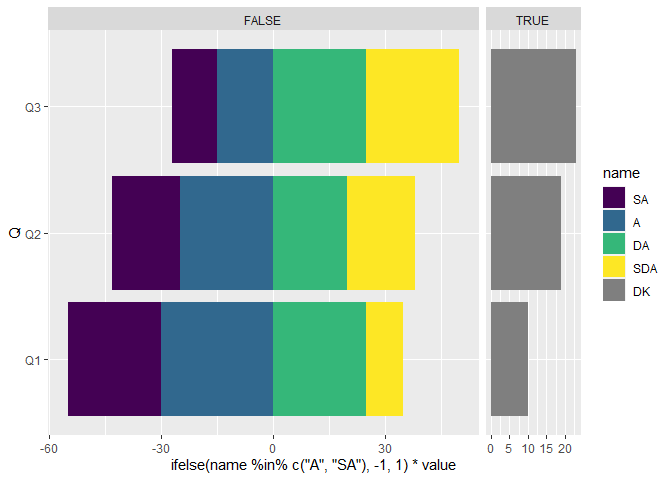
正如評論中所建議的,您可以將“DK”類別排除在外。
library(ggplot2)
library(tidyr)
library(scales)
df <- structure(list(Q = structure(1:3, .Label = c("Q1", "Q2", "Q3"
), class = "factor"), SA = c(25, 18, 12), A = c(30, 25, 15),
DA = c(25, 20, 25), SDA = c(10, 18, 25), DK = c(10, 19, 23
)), row.names = c(NA, -3L), class = "data.frame")
lvls <- colnames(df)[c(2,3,5,4,6)]
ggplot(
pivot_longer(df ,-1),
aes(y = Q, fill = name, group = factor(name, lvls),
x = ifelse(name %in% c("A", "SA"), -1, 1) * value)
)
geom_col()
facet_grid(~ name == "DK", scales = "free_x", space = "free_x")
scale_fill_manual(
values = c(viridis_pal()(4), "grey50"),
limits = colnames(df)[-1]
)
由reprex 包(v2.0.1)于 2021 年 11 月 4 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/349196.html
下一篇:驗證JavaPOJO中的欄位值