我的本地系統上有一個 git 存盤庫,位于/original/.git. 現在,我已經在/cloned_one/.git. 一切看起來都很好。在這里,我有與我相同的檔案,這些檔案/original非常好。我創建一個新檔案并提交它。現在,我克隆的 repo 是一次提交。我想推動更改,但不知道如何!
它變得更加棘手,因為我對以下命令的多樣性和確切用例感到有些困惑。我知道其中的一些并且實際上以某種方式與他們合作過,但我看到很多用戶在錯誤的地方使用它們,這就是讓我感到困惑的原因。不確定何時使用以下命令。
git fetchgit rebasegit pushgit mergegit --force push
謝謝。
uj5u.com熱心網友回復:
Git 的遠程倉庫可以來自 ssh、https 和目錄。
在你的例子中,
/original/.git具有遠程來源,它指向github上(通過ssh任一或https,例如:https://github.com/user/example.git)/cloned_one/.git具有指向目錄的遠程源(例如:/original/.git
這看起來像某種鏈表:
[/cloned_one/.git] --origin--> [/original/.git] --origin--> [github]
這是重現此類設定的示例命令:
$ cd /tmp
$ git clone https://github.com/schacon/example.git original
Cloning into 'original'...
remote: Enumerating objects: 4, done.
remote: Total 4 (delta 0), reused 0 (delta 0), pack-reused 4
Receiving objects: 100% (4/4), 18.52 KiB | 3.70 MiB/s, done.
$ mkdir cloned_one
$ git clone /tmp/original cloned_one
Cloning into 'cloned_one'...
done.
$ cd cloned_one/
$ echo newfile > newfile.txt
$ git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
newfile.txt
nothing added to commit but untracked files present (use "git add" to track)
$ git add newfile.txt
$ git commit -m 'add new file'
[master e45e780] add new file
1 file changed, 1 insertion( )
create mode 100644 newfile.txt
$ git remote -v
origin /tmp/original (fetch)
origin /tmp/original (push)
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
現在,cloned_one提前 1 次提交original
您可以將更改從cloned_oneto推送到originalwith(請記住cd /tmp/cloned_one首先):
git pushgit push origin mastergit push /tmp/original master
在這里,push 的語法是指定你想要推送的位置(例如:到 origin,或者到 /tmp/original 目錄),以及你想要推送的分支
$ cd /tmp/cloned_one/
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 333 bytes | 333.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote: error: refusing to update checked out branch: refs/heads/master
remote: error: By default, updating the current branch in a non-bare repository
remote: is denied, because it will make the index and work tree inconsistent
remote: with what you pushed, and will require 'git reset --hard' to match
remote: the work tree to HEAD.
remote:
remote: You can set the 'receive.denyCurrentBranch' configuration variable
remote: to 'ignore' or 'warn' in the remote repository to allow pushing into
remote: its current branch; however, this is not recommended unless you
remote: arranged to update its work tree to match what you pushed in some
remote: other way.
remote:
remote: To squelch this message and still keep the default behaviour, set
remote: 'receive.denyCurrentBranch' configuration variable to 'refuse'.
To /tmp/original
! [remote rejected] master -> master (branch is currently checked out)
error: failed to push some refs to '/tmp/original'
現在它說你無法推送到 /tmp/original 因為它不是一個裸倉庫。您可以通過將 /tmp/original 更改為裸倉庫來解決此問題,也可以將其配置為在推送到如下所示時更新其作業樹:
$ cd /tmp/original/
$ git config receive.denyCurrentBranch updateInstead
$ cd /tmp/cloned_one/
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 333 bytes | 333.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To /tmp/original
c3d5e92..e45e780 master -> master
現在,如果您想將更改推送回 github(的來源/tmp/original),您可以從/tmp/original或 從推送它/tmp/cloned_one:
cd /tmp/original ; git push origin mastercd /tmp/cloned_one ; git push https://github.com/username/example.git
Notice that when pushing from /tmp/original, you can specify the target as origin (since the origin of /tmp/original is from github). While when pushing from /tmp/cloned_one, you have to specify the target as full URL.
You can also change cloned_one's remote to point to github (search for git remote manual)
Further reading:
- what's a bare repo?
- Bare repository is just a normal repository, but without the file checked out (e.g.: just the .git directory),
在這里,這顯示了我的本地分支以及遠程分支(以紅色表示,表示它們是遠程的)
當你運行時
git pull,這實際上做了兩個步驟:- 首先,它運行
git fetch。這將根據您從中克隆的存盤庫中的任何內容更新所有遠程分支。請注意,此存盤庫實際上可能不在遠程服務器上;它可能在您的本地機器上,就像您的情況一樣。 - 其次,它運行
git merge或git rebase取決于您的配置選項。這會將您的遠程分支合并到您的本地分支中。
這就是您的存盤庫更新的方式。
但是你會在不合并的情況下獲取嗎?
在不合并的情況下獲取可能很有用,因為它允許您在遠程更改合并到本地分支之前檢查它們。這可以像這樣完成:
git fetch git diff <your branch> origin/<your branch>Running this in one of my repositories, I see the following changes have occured on the original repo I cloned from. (This uses
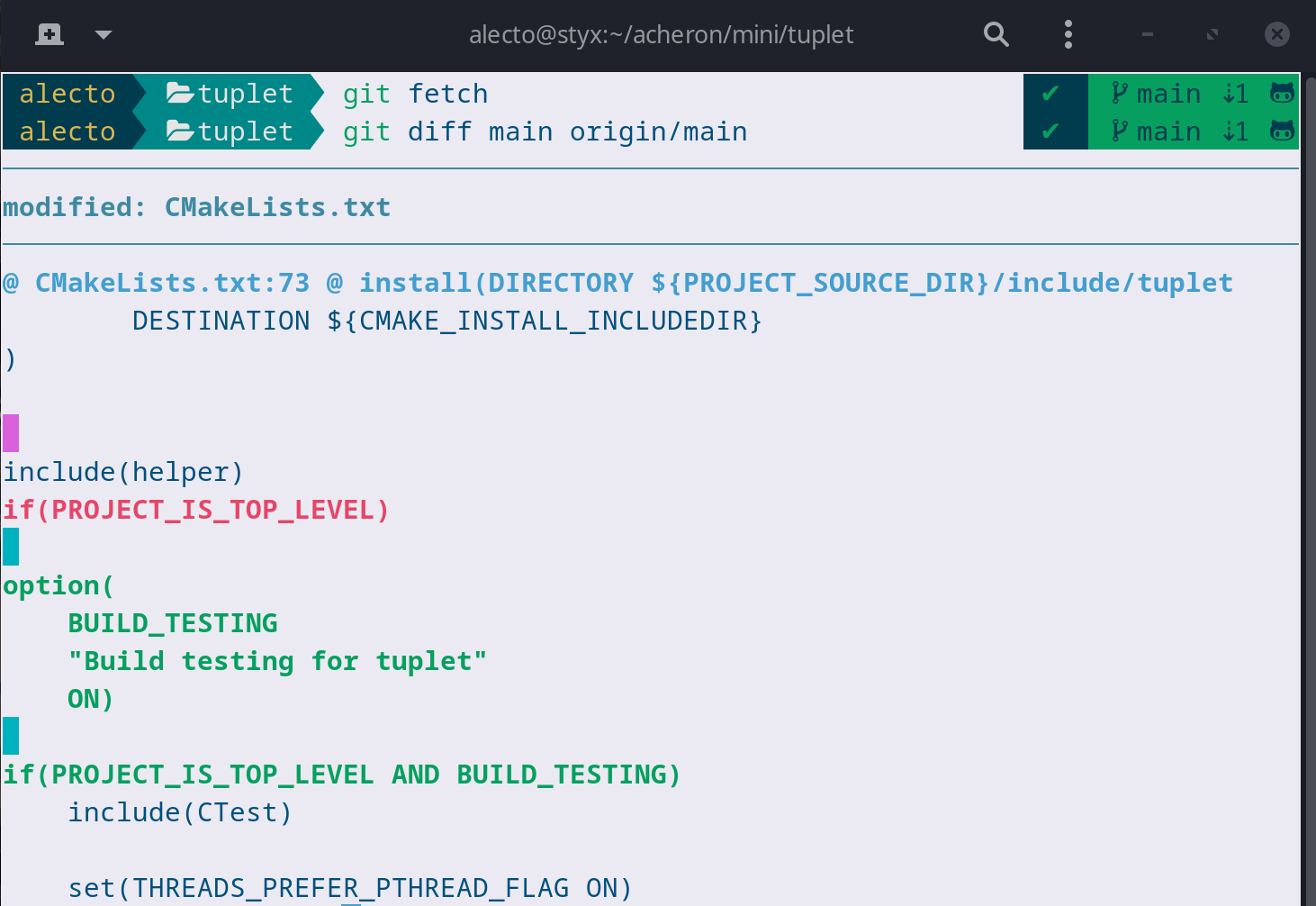
TL;DR: You don't usually need to fetch, but it's nice to view changes ahead of time
Merging vs Rebasing
Merging is when you take two separate histories, and join them together with a merge commit.
Most commits have a parent, but merge commits have two parents (or three or more, in the case of octopus merges). Initial commits have zero parents, but they're special because nothing comes before them.
We can take a look at the commit graph of one of the projects I'm working on to see an example of this. Here, I did work in several feature branches, before creating pull requests for them to be merged back into the main branch.
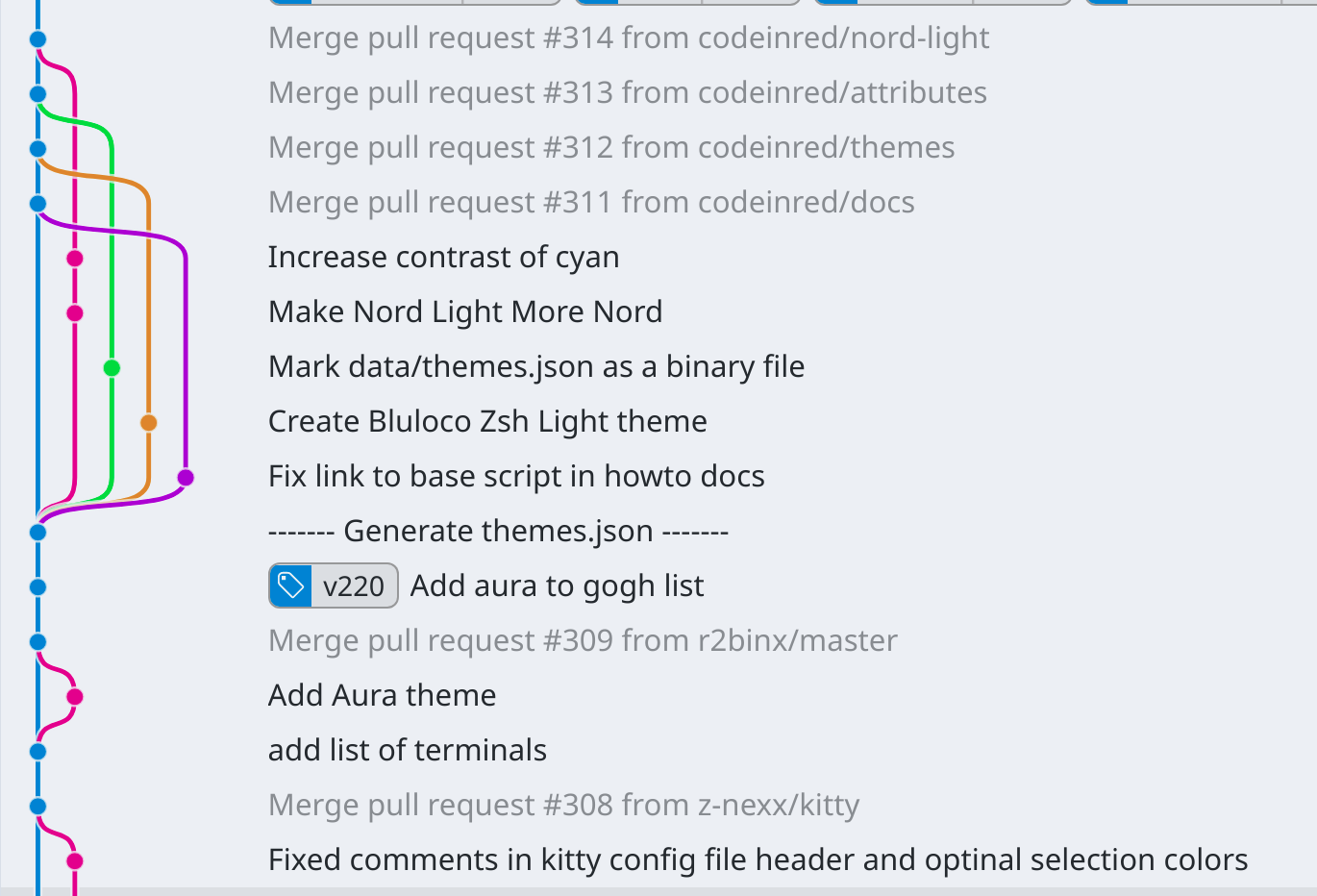
I think graphs like this are pretty, but some people prefer linear histories, and that's where re-basing comes in.
Instead of joining two branches together, it just breaks one branch off, and glues it on top of the other one. This is a good article that goes into detail about it.
What's pull with rebase?
If you have commits on your local branch (say,
main), AND there are new commits on the remote branch (say,origin/main), then normally, as the final step in of the pull, git will merge the two, so that your local branch will now have all the commits fromorigin/main.This is the one time I prefer rebasing to merging: it's nicer to just stick your local commits on top of the remote ones, so there aren't multiple branches in history.
I set rebasing as the default option using the following command:
git config --global pull.rebase mergesWhat this means is "rebase my local commits on top of the remote ones, but preserve any merges I did intentionally (like merging in a feature branch)". This is a good default to have, and it keeps me happy.
git push, and git push --force
This is how you get your local changes, to the cloned repository.
git pushwill upload your changes, but if the remote repository has changes you don't have (say, because a coworker pushed to it before you), it'll refuse to upload your changes since that would cause a conflict. Fixing this is simple:git pull git push- Pulling 通過合并或變基將您同事的更改與您的更改集成在一起,以便您可以上傳您的更改
- 推送然后上傳您的更改
那么 git push --force 呢?
使用此命令要非常小心。它的主要目的是重寫歷史記錄,如果將機密提交到 git 存盤庫,或者由于其他原因需要永久洗掉檔案,則偶爾需要重寫歷史記錄。
如果您的同事對遠程存盤庫進行了更改,則強制推送將覆寫這些更改。
如果你想覆寫你所做的提交,一個更安全的選擇是
--force-with-lease,這將確保唯一被覆寫的更改是你的。uj5u.com熱心網友回復:
我是這樣想的:存盤庫共享提交,但它們不共享分支名稱。
從本質上講,Git 存盤庫(邊緣變得雜亂無章)實際上是一對資料庫。兩個資料庫都是簡單的鍵值存盤:
其中之一——通常是迄今為止最大的——被大丑陋的哈希ID索引/訪問。這些是提交哈希 ID 和其他內部 Git 物件哈希 ID。所以這是物件資料庫(盡管 Git 通常不會以這種方式參考它)。
另一個將名稱(分支名稱、標簽名稱和所有其他型別的名稱)映射到那些丑陋的大哈希 ID。這讓我們窮人可以使用Git;哈希 ID 不可用。這是名稱資料庫,每個名稱都映射到一個哈希 ID。多個名稱可以映射到一個特定的哈希 ID,并且許多哈希 ID 沒有映射到它們的名稱,因此如果您習慣于從數學集合的角度進行思考,那么這是一種非內射、非滿射映射(見滿射函式)。
物件資料庫中的每個提交物件都有一個唯一的哈希 ID。任何物件的哈希 ID,無論是否提交,都是對構成該物件的資料運行加密哈希函式的結果(這就是 Git 進行一致性檢查和檔案內容重復資料洗掉的方式)。但是每個提交本身都是獨一無二的,這要歸功于提交的幾個屬性,因此每個提交都有一個唯一的哈希 ID。1 使用這些提交哈希 ID,然后,任何兩個不同的Git 存盤庫,使用兼容的 Git 軟體——我稱之為“兩個 Git”——這兩個 Git 可以立即判斷它們是否具有相同的提交,只需比較提交哈希 ID。2
這一切都歸結為,當我們將兩個 Git 相互掛鉤時,其中一個——發送者——說諸如I have commit 之
a123456...類的事情,你喜歡嗎?其他人的回答是請還是不要,謝謝,我已經有了那個,這允許發送者只向接收者發送發送者沒有的提交。這個程序——例如發送我有而你沒有的提交——是一個
git fetch或git push,這取決于誰開始對話。如果您開始對話以獲取我的提交,那么您正在使用git fetch. 如果我開始對話以向您發送提交,則我使用git push.
1任何熟悉鴿巢原理的人都會立即反對哈希函式,即使是具有 2 160范圍 (SHA-1) 或 2 256范圍 (SHA-256)的哈希函式,最終都必須產生碰撞。這是真的,當這種情況發生時,Git 停止運行,因此哈希值必須足夠大,以至于“最終”在幾十年或幾個世紀之后就不用擔心了。(由于生日問題,這比起初看起來更難。)
2由于提交形成的 DAG,我們可以做得比僅僅列出所有原始哈希 ID 好得多,但是如果我們有兩個相當小的存盤庫——比如每個有幾千個提交——那么只需列出所有的哈希 ID,以查看誰提交了哪些提交。
這就是使用多個 Git 存盤庫的大部分內容
說真的,這種傳輸是我們所需要的,也是原始 Git 中的全部,用于將兩個Git相互連接。通過比較哈希 ID 和發送提交,我有而你沒有,你最終會分享我的提交。如果我然后轉身從你那里得到你有而我沒有的任何提交,我們現在就我們擁有的一組提交而言是平等的。但這不是使用Git的便捷方式,因此我們現在添加一些額外功能。
分支名稱、標簽名稱、遠程跟蹤名稱等
人類不擅長哈希 ID:
e9e5ba39a78c8f5057262d49e261b42a8660d5b9. 說什么?可能有一些人可以向您重復一份 Git-repository-for-Git 標簽哈希 ID 串列,如果他們已經閱讀過它們,但我有時會轉置這些字符,并且不要費心去嘗試記住它們。這就是計算機的用途。我讓計算機為我記住哈希 ID:現在master可能會保留e9e5ba39a78c8f5057262d49e261b42a8660d5b9。稍后,master將持有一些其他哈希 ID。無論它持有什么哈希 ID,根據定義,就是這個 Git 存盤庫中我的分支上的最新提交。master當我們使用 時
git fetch,Git 以一種很好的方式為我們維護了所有這些東西。我們創建了一個遠程——一個類似的短名稱——origin我們在它下面存盤了一個傳統的 URL,比如ssh://[email protected]/path/to/repo.git,或者一個路徑名/absolute/path/to/dir/.git,或者任何合適的。3既然我們有了這個短名稱,
origin或者fred我們選擇的任何東西,我們的Git 就可以呼叫他們的Git——也就是說,我們的 Git 軟體可以使用 ssh 或 https 或其他任何方式來訪問他們的 Git 軟體;我們的 Git 將在我們的存盤庫中運行,而他們的 Git 將在他們的存盤庫中運行——一旦我們呼叫了他們的 Git,我們就可以使用git fetch它們來獲取提交。我們用一個簡單的方法來做到這一點:git fetch origin例如。
Their Git lists out their branch names and the corresponding commit hash IDs. Our Git inspects these hash IDs and uses that to figure out if they have commits that we don't. If we don't limit our Git,4 our Git now brings over all of their commits that we don't already have, so now we share their commits.
But: our branch names are stuff we use to find specific commits in our repository, that we like for some specific reason. Our
git fetchdoes not touch our branch names. Instead, our Git takes each of their branch names and changes these into remote-tracking names.5 Git does this by sticking the remote name—in this case,origin—in front of the branch name, plus a slash. So this is whereorigin/mainororigin/mastercomes from: that's our copy of their branch name. It's our Git's way of remembering their Git'smainormaster(whichever one they have).So,
git fetchgets us their commits, but does nothing with our own branches. Due to the hashing tricks that Git uses, all objects—including all commits—are completely read-only, so this update only adds new commits to our repository. We share their commits but not their branch names.
3A very short relative path like
../d/.gitisn't much longer or harder to type thanorigin, so for this kind of case, you might be tempted to leave out the remote name. But don't do it! Git needs that remote name to form the remote-tracking names. If you skip using a remote name, you're using the primeval mode, which Git still supports, it's just a pain in the <insert body part>.4You can deliberately limit your
git fetchto cut down on network traffic or whatever. This is mostly unnecessary most of the time, since Git is clever about only bringing over any needed objects. In some rare cases it can be useful, though.5Git calls these remote-tracking branch names. They're not branch names though, not in our repository anyway. They're our copies of someone else's branch names. So from our point of view these are non-branch names that merely happen to "track" someone else's (branch) names. Git over-uses both the verb track and the adjective branch, but we can cut down this overuse just a smidgen here.
From this point on, you work locally, at least until
git pushWhat you have at this point is:
- all the commits;
- your own branch names; and
- your copy / memory of their branch names.
You work with your repository by extracting specific commits (
git checkout) into your working tree and Git's index or staging area (two terms for the same thing). You eventually make new commits, which add on to the existing commits. When you do make a new commit, Git automatically updates your current branch name, so that your branch names automatically include your new commits.You've asked about merge and rebase, and these are both actually quite large topics, but they're pretty well covered elsewhere. Remember that
git mergemostly means combine work. Thoughgit mergeis full of exceptions to the usual ways of combining work, this mostly happens by making new commits. Meanwhile,git rebasemeans I'm sort of satisfied with some set of commits in my repository, but there is something I don't like about these commits. I'd like to copy them to a set of new-and-improved commits, with the option of doing special tricks along the way.Because you literally can't change any existing commit, the copying means that you get duplicates—or rather, near-duplicates, with the "near" part depending on what you're changing, given that you're changing something or you'd just use the originals. The goal of rebase is to stop using the originals and start using the near-duplicates instead. Since we generally find our commits using a branch name, Git achieves this by moving the name:
K--L <-- br2 (originals) / ...--F--G--H--I--J <-- br1 \ K'-L' <-- proposed new br2 <-- older ... newer -->We have Git copy
KtoK', improving the copy by usingJas the base commit, then we have Git copyLtoL', improving the copy by usingK'as the base forL'. That's the main part of the rebase in action. But now we have to stop usingK-L, and start usingK'-L'instead. Since we find commits through branch names, Git merely needs to "peel the label" off commitLand paste it onto commitL'instead. Git then works backwards—this is a general theme in Git, that it starts at the end and works its way backwards—fromL', so now you don't seeK-Lany more.Because commits are shared and branch names aren't, if you got commits
K-Lfrom some other Git repository, you now have a problem: their branch name still refers to commitL, not to your newL'.git pushis not just a reversedgit fetchWhen you run
git push, you:- have your Git call up some other Git;
- have your Git give that Git specific commits: not just everything I have that you don't but rather every commit on some branch that I have that you don't (commits I have that you don't, that are on some particular branch of my choice);
- and finally, once those commits have made it over, you politely request (regular
git push) or command (git push --force) that their Git should update their branch name.
When we use
git fetch, we have these friendly remote-tracking names by which our Git remembers their branch names. Thepushcommand doesn't bother with friendliness. We just propose to overwrite their branch name entirely, with some new hash ID.If the commits we send to them add on to their branch as they see it right then and there, this polite request—please set your branch name
developtoa123456...for instance—is probably OK. They had:...--G--H <-- developwhere
Hstands in for9876543...or whatever hash ID. We sent them commitsI-J:...--G--H <-- develop \ I--J <-- polite request to set "develop" to point to JIf they obey this polite request, their commit
Hremains findable, because Git works backwards from the branch name's commit.Jleads back toIwhich leads back toH, and hey, we haven't lost them any commits!After a
git rebase, though, we've taken some existing commits and thrown them out in favor of new-and-improved replacements. Suppose they had:I--J <-- br1 / ...--F--G--H <-- develop \ K--L <-- br2in their repository, and we now send them a pair of commits
K'-L'that add on to commitJ:K'-L' <-- please set br2 here / I--J <-- br1 / ...--F--G--H <-- develop \ K--L <-- br2This polite request, that they set their
br2to point toL'instead ofL, will not go over well. They will say: No! If I do that I lose commits! Of course, we want them to loseK-L, in favor ofK'-L'. But they don't know that unless we tell them.This is what
git push --forceis for. However, if their Git repository is highly active, maybe we gotK-Learlier, but now they have:K'-L' <-- please set br2 here / I--J <-- br1 / ...--F--G--H <-- develop \ K--L--N <-- br2We're proposing that they ditch the entire
K-L-Nchain in favor of ourK'-L'.The
--force-with-leaseoption is an attempt to improve this situation. It works pretty well in current Git, but there may be updates coming where it won't be quite right. (I think it should be kept "right", and there are proposals to do that too, so we'll see.)Bare repositories
When we use Git, we have some commit checked out. This commit is from our current branch and is our current commit. We may be in the middle of working on a new commit. In this state, Git literally can't receive an update to our current branch: that would mess things up.6 So Git will deny a push to the currently-checked-out branch.
To sidestep this problem, Git repositories that are meant to receive
git pushrequests are normally set up as bare repositories. A bare repository is one with no working tree. With no working tree, no one can do any work in the bare repository. This means there is nothing to get messed up, and the bare repository can always receive a push.There are other ways to deal with this (configuration settings for
receive.denyCurrentBranch), but another good way to sidestep the problem is to avoidgit push: usegit fetchwhen using two different repositories where you control both of them. By always fetching from B when you're in working in A, and always fetching from A when you're working in B, you can't step on yourself.
6In particular, Git's index contains an image of the current commit, as modified by any proposed replacement files we
git add-ed, new files we added, and/or files wegit rm-ed. Git will build the new commit from whatever is in the index, and the parent of the new commit will be the current commit, whose hash ID is stored in the branch name. So making an update to the branch name requires updating the index and working tree as well. If we're in the middle of doing something, that's a bad idea. Even if we're not, updating the branch name means that our new commit may go where we didn't expect. The whole situation is tough.A bottom line
In Git, you work locally, with commits. These are in your repository: there's just the one, which you're in right now, with the one working tree and Git's index.7 To get commits from some other Git, use
git fetchwith a remote: a short name likeorigin. Add more remotes, withgit remote add, to add more places to fetch from. Usegit remote set-urlto fiddle with the URL for one particular remote,git remote removeto remove a remote, andgit remote updateto make Git fetch from all remotes.8 Consider settingfetch.prunetotrueto work around what I consider a historical error in thefetchdefaults.9After you
git fetch, you have all the commits. Do whatever you like with them. Leave them in your repository, rebase them, whatever. Then, if the other Git is a bare Git that's set up to receivegit pushrequests, usegit pushto send your new commits and ask them to set one of their branch names to remember your commits:- If this creates a new name in their Git, they'll probably allow it.
- If this updates a name such that the old commits are still there, they'll probably allow it.
- If this updates a name so as to stop finding old commits on their side, they will reject it unless you use one of the
--forceoptions; use--force-with-leasefor safety.
If the other Git isn't bare, and/or you want to work directly in it, change where you're working so that you're now in the other repository, and use
git fetchto obtain the commits you made in the repository you were working in, a moment ago. Sincefetchitself is always safe,10 this will be safe.Always, always remember that if you haven't committed something, it's not in Git (yet). If you have committed it, it's in a commit, and even after mini-disasters, you can usually get it back.11
7
git worktree addcomplicates this picture, so let's just ignore it here. ??8Or, use
git fetch --all: this is what--allmeans, all remotes. Thegit remote updatecommand is fancier and lets you do more stuff here though.9That is, run:
git config --global fetch.prune trueonce, to set this in your global configuration, on this particular machine. When
git fetchfetches from some remote R, it creates or updatesR/branchfor each branch it sees on R. But if R had a branch namedfancy42yesterday and today that branch is gone, your Git doesn't do anything: it createdfancy42yesterday when you rangit fetch, and now there's nofancy42to create or update, so it doesn't create or update it. That leaves you with a "stale"fancy42.With pruning enabled,
git fetchandgit remote updatenotice that theirfancy42is gone now, and therefore you shouldn't haveR/fancy42either. Your Git will delete this. This isn't the default because, well, it wasn't the default originally, and now it's too late to change it. There may be people who like or even depend on it. If you like it yourself, leavefetch.pruneset tofalseand don't rungit remote prune.10You can configure or force
git fetchto be "unsafe", but unless you do that on purpose or usegit clone --mirrorto do that, you won't run into this.11The big exception to this rule is if the Git databases themselves get damaged. This tends to happen when:
- the repository is on a shared drive (Google Drive, iCloud, OneDrive, etc);
- the computer crashes or is shut down improperly so that the OS fails to write stuff to disk;
- the computer itself catches on fire (this was once a common laptop problem); or
- you use the OS to forcibly remove the Git repository database inside the
.gitdirectory.
Otherwise these things are really quite reliable.
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/349269.html標籤:混帐 存储库 当地的 git-push git-repo
- 首先,它運行