更新添加了讀/寫吞吐量、IOPS 和佇列深度圖表指標,并在我所說的錯誤開始的時間位置標記圖表
注意:您好,只是從經驗豐富的 DBA 或資料庫開發人員(或任何了解這方面知識的人)那里尋找可能導致此問題的建議。我擁有的一些日志/資料是敏感的,因此我無法在此處重新發布,但我已盡力提供螢屏截圖和除錯資料,以便人們可以幫助我。謝謝你。
您好,我有一個托管在 Amazon (AWS) 上的Postgres RDS 資料庫(版本 12.7 引擎)。該資料庫每小時被 API 客戶端(Spring Boot/Web/Hibernate/JPA Java API)“命中”或呼叫數千次。它僅在后端執行一個 1 hibernate sql 查詢,該查詢位于跨 5 個表的 Postgres 視圖上。queryDB 實體(class = db.m5.2xlarge)規格是:
8 vCPU
32 GB RAM
Provisioned IOPS SSD Storage Type
800 GiB Storage
15000 Provisioned IOPS
我看到的問題是在星期六我醒來看到許多JDBCConnectionExceptions日志,我注意到我的 API Docker 容器(在 ECS 上定義為服務任務)托管在 AWS 彈性容器服務 (ECS) 上將開始失敗并回傳HTTP 503錯誤,例如
org.springframework.dao.DataAccessResourceFailureException: Unable to acquire JDBC Connection; nested exception is org.hibernate.exception.JDBCConnectionException: Unable to acquire JDBC Connection
在檢查 AWS RDS 資料庫狀態時,我還可以看到會話/連接急劇增加,如下圖所示,大約有 600 個連接。它會不斷增加,似乎不會停止。

當我開始獲取所有這些 JDBCConnectionExceptions 并且 DB Connections 跳到大約 400(在這個特定時間)時檢查 postgres 資料庫pg_locks和pg_stat_activity表時,我確實看到我的許多 API 查詢記錄了有趣的狀態。我將資料匯出到 CSV 并在下面包含了一個摘錄:
wait_event_type wait_event state. query
--------------- ------------ --------------------------------------------- -----
IO DataFileRead active (480 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFileRead idle (13 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFilePreFetch active (57 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFilePreFetch idle (2 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
Client ClientRead idle (196 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
Client ClientRead active (10 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
LWLock BufferIO idle (1 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
LWLock BufferIO active (7 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
如果我在pg_stats_activityAPI 和 DB 運行且穩定時查看我的表,API 查詢中的大多數行只是Client ClientRead idle狀態,所以我覺得這里有問題。
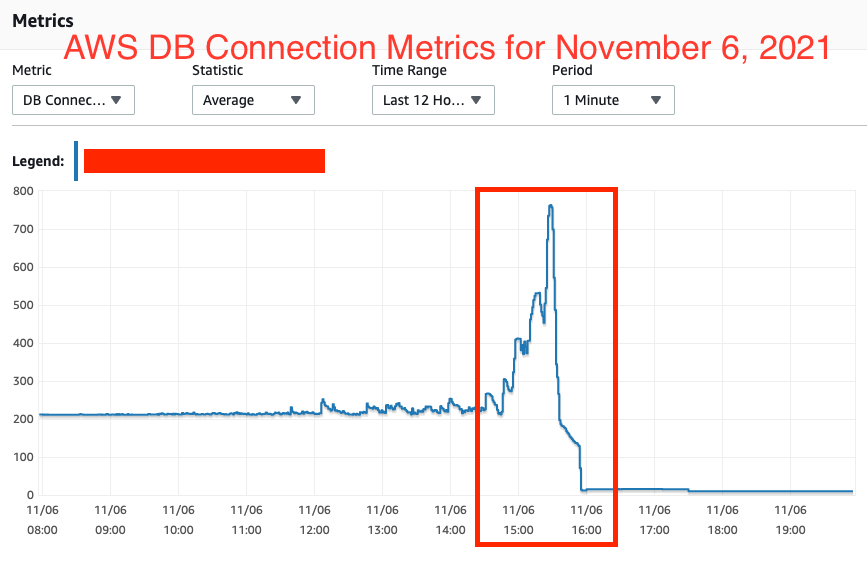
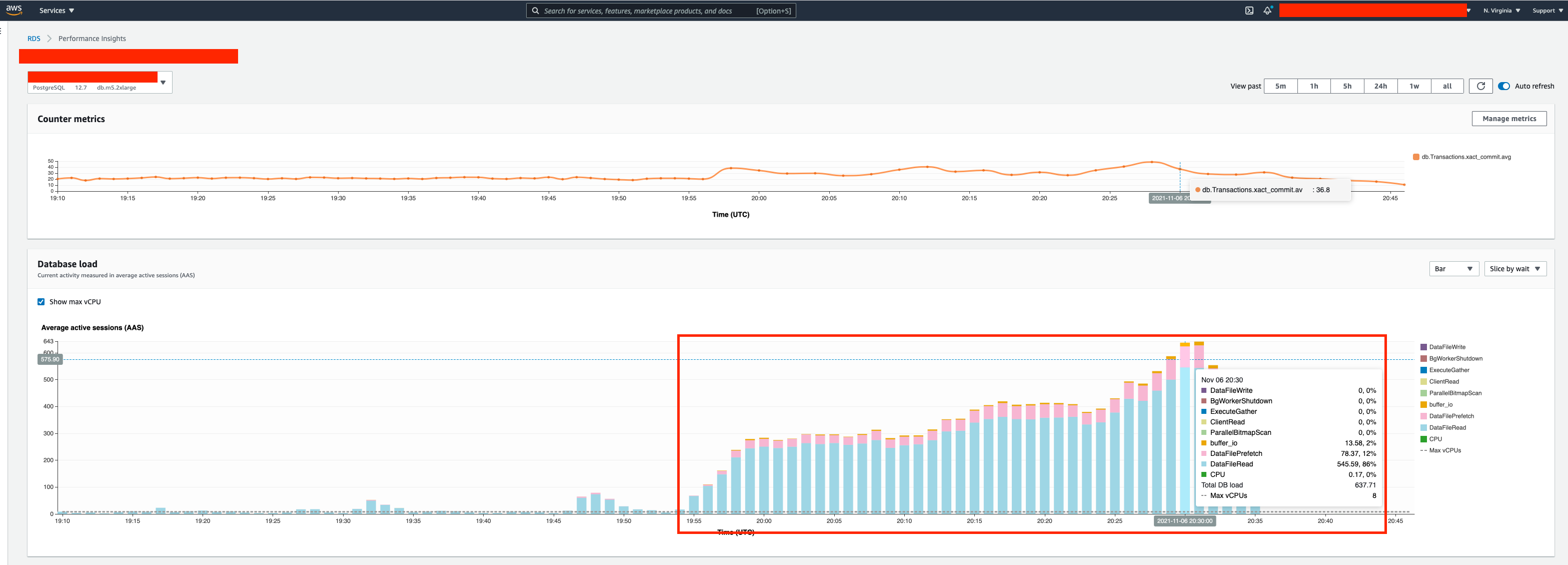
You can see the below "performance metrics" on the DB at the time this happened (i.e. roughly 19:55 UTC or 2:55PM CST), the DataFileRead and DataFilePrefetch are astronomically high and keep increasing, which backs up the pg_stat_activity data I posted above. Also, as I stated above, during normal DB use when it is stable, the API queries will simply be in Client ClientRead Idle status in pg_stat_activity table, the the numerous DataFileRead/Prefetches/IO and ExclusiveLocks confuses me.
I don't expect anyone to debug this for me, though I would appreciate it if a DBA or someone who has experienced similiar could narrow down the issue possibly for me. I honestly wasn't sure if it was an API query taking too long (wouldn't make sense, because API has ben running stable for years), something running on the Postgres DB without my knowledge on Saturday (I really think something like this is going on), or a bad postgresql Query coming into the DB that LOCKS UP the resources and causes a deadlock (doesn't completely make sense to me as I read Postgres resolves deadlocks on its own). Also, as I stated before, all the API calls that make an SQL query on the backend are just doing SELECT ... FROM ... on a Postgres VIEW, and from what I understand, you can do concurrent SELECTS with ExclusiveLocks so.....
Would take any advice here or suggestions for possible causes of this issue
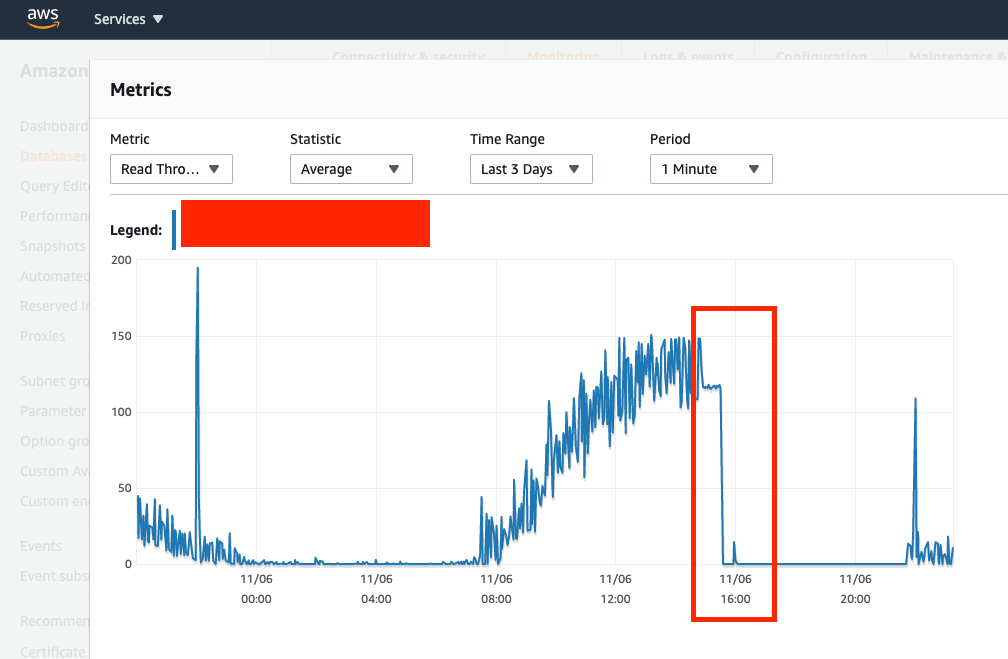
Read-Throughput (first JdbcConnectionException occured around 2:58PM CST or 14:58, so I marked the graph where READ throughput starts to drop since the DB queries are timing out and API containers are failing)
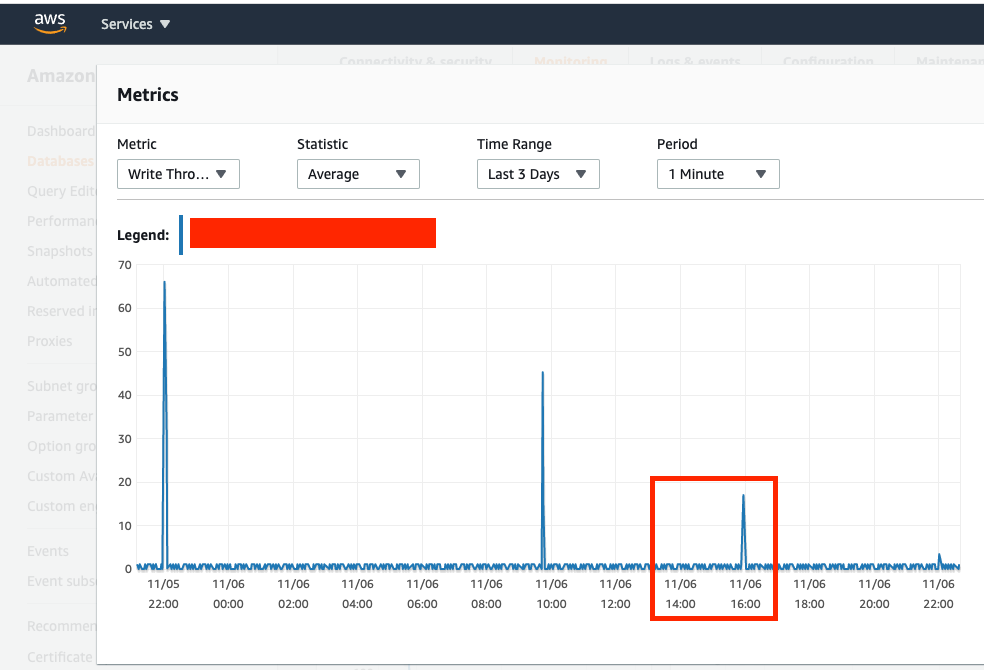
Write-Throughput (API only READS so I'm assuming spikes here are for writing to Replica RDS to keep in-sync)
Total IOPS (IOPS gradually increasing from morning i.e. 8AM, but that is expected as API calls were increasing, but these total counts of API calls match other days when there are 0 issues so doesn't really point to cause of this issue)
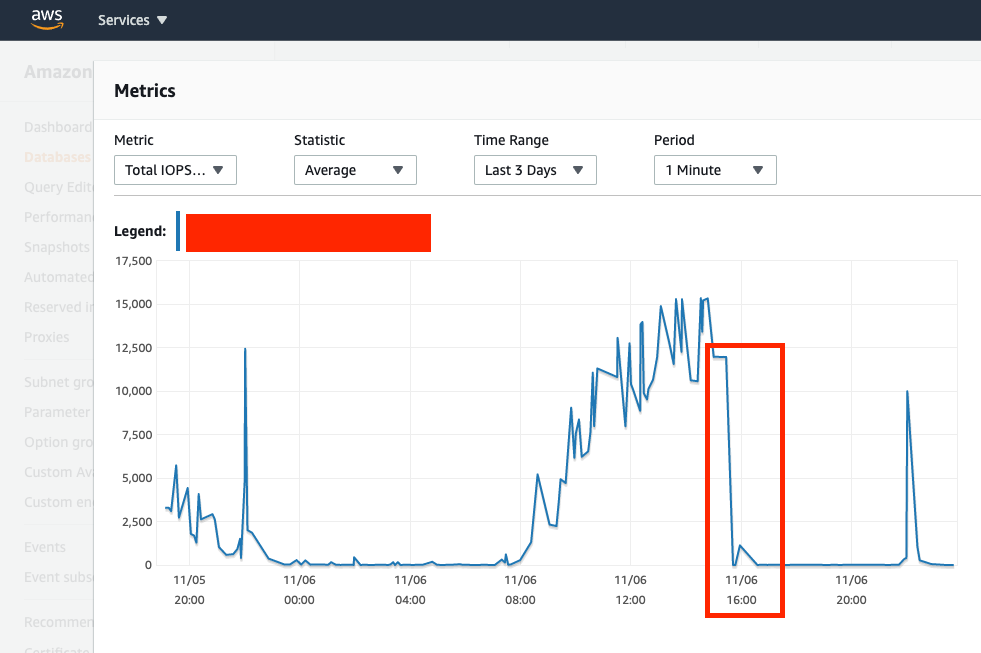
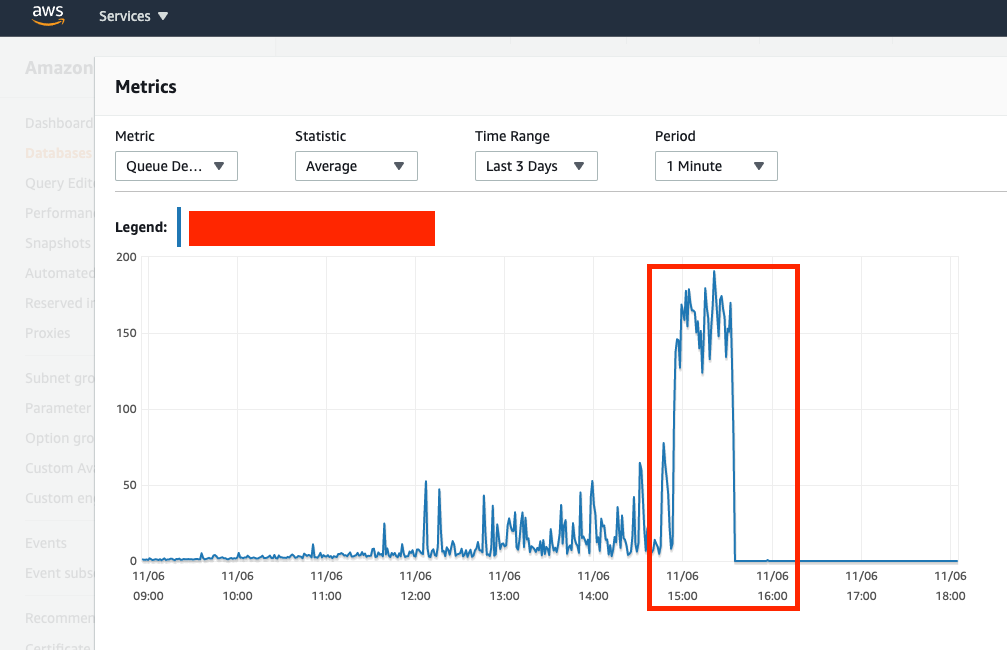
Queue-Depth (you can see where I marked graph and where it spikes is exactly around 14:58 or 2:58PM where first JdbcConnectionExceptions start occuring, API queries start timing out, and Db connections start to increase exponentially)
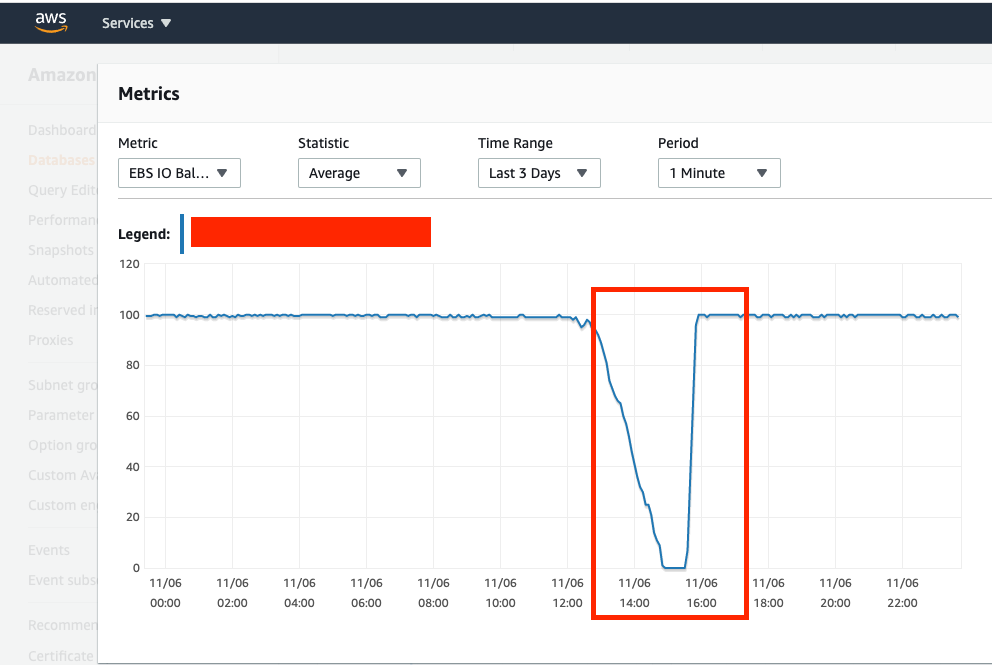
EBS IO Balance (burst balance basically dropped to 0 at this time as-well)
Performance Insights (DataFileRead, DataFilePrefetch, buffer_io, etc)
uj5u.com熱心網友回復:
這只是看起來您的應用服務器要求越來越高,而資料庫跟不上。您其余的大多數觀察結果只是其自然結果。為什么會發生這種情況最好從應用程式服務器而不是資料庫服務器進行調查。要么它發出越來越多的請求,要么每個請求都需要更多的 IO 來完成。(您可以通過提高資料庫效率來解決此問題,例如添加缺失的索引,但這需要您共享查詢和/或其執行計劃)。
看起來您的應用服務器配置為始終保持 200 個連接,即使幾乎所有連接都處于空閑狀態。所以,這就是它的作用。
這就是ClientReadwait_event 的含義,它只是坐在那里空閑,試圖讀取來自客戶端的下一個請求,但沒有收到任何請求。可能還有一些其他連接正在積極接收和處理請求,完成所有實際作業,但只占用 pg_stat_activity 的一小部分。所有這些額外的空閑連接都沒有任何好處。但它們可能也沒有造成任何真正的傷害,除了使 pg_stat_activity 看起來不整潔,并使您感到困惑。
但是,一旦應用服務器開始生成請求的速度超過了可以提供服務的速度,進行中的請求就會開始堆積,并且應用服務器被配置為不斷添加越來越多的連接。但是你不能僅僅通過打開更多的連接來強迫磁盤驅動器提供更多的吞吐量(至少當你達到一個完全飽和的閾值時)。因此,您擁有的活動連接越多,它們就越需要在它們之間分配相同數量的 IO,并且每個連接的速度越慢。讓這 700 個額外的連接全部等待不會使資料到達更快。擁有更多的連接沒有任何好處,而且可能會造成一些傷害,因為它會產生爭用,而處理爭用本身就是一種資源消耗。
您提到的 ExclusiveLocks 可能是每個活動會話對其自己的事務 ID 的鎖。它們不會成為問題的原因,只是表明您有很多活動會話。
當兩個會話同時需要完全相同的資料時,您會得到 BufferIO。一個請求資料 (DataFileRead),另一個請求在第一個完成時得到通知 (BufferIO)。
uj5u.com熱心網友回復:
根據您分享的內容,我猜您的連接沒有正確關閉。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/353515.html
標籤:java postgresql session amazon-rds dbconnection
上一篇:從foreach回圈ASP.NETCore5.0回傳變數
下一篇:使用執行緒凍結UI