請任何人都可以幫助我,我對用于抓取網頁的 Beautiful Soup 非常陌生。我想提取網頁上的第一個表格,但是表格中有不規則的列,如附圖所示。前 3 行/ 3 列后跟一行 1 列。請注意,前三行將來可能會更改為多于或少于 3 行。單行/1 列后跟一些行和 4 列,然后是單行/列。有沒有辦法可以撰寫 Beautiful Soup python 腳本來提取列跨度為 6 的 td 標記之前的前 3 行,然后提取列跨度為 6 的 td 標記之后的下一行?
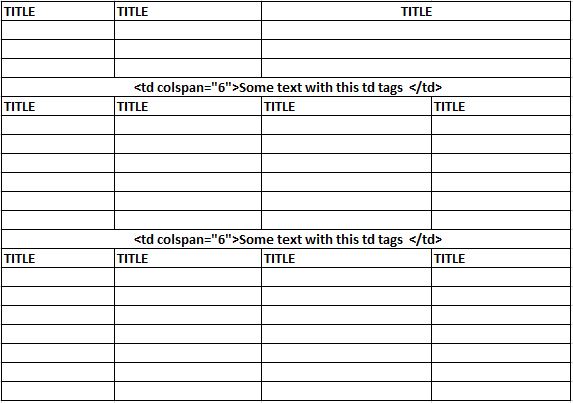
到目前為止,我的 Python 代碼(#### 給了我帶有不規則列的整個表格,但不是我想要的):
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
url = " "
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
rows = []
for child in soup.find_all('table')[1].children:
row = []
for td in child:
try:
row.append(td.text.replace('\n', ''))
except:
continue
if len(row) > 0:
rows.append(row)
pd.DataFrame(rows[1:])
uj5u.com熱心網友回復:
一旦擁有 table 元素,我會為沒有 colspan = 6 的 td 的 tr 孩子選擇
這是 colspan 3 的示例
from bs4 import BeautifulSoup as bs
html = '''<table id="foo">
<tbody>
<tr>
<th>A</th>
<th>B</th>
<th>C</th>
</tr>
<tr>
<td>D</td>
<td>E</td>
<td>F</td>
</tr>
<tr>
<td colspan="3">I'm not invited to the party :-(</td>
</tr>
<tr>
<td>G</td>
<td>H</td>
<td>I</td>
</tr>
</tbody>
</table>'''
soup = bs(html, 'lxml')
for tr in soup.select('#foo tr:not(:has(td[colspan="3"]))'):
print([child.text for child in tr.select('th, td')])
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/354337.html