我有一個包含此類資料的 csv 檔案:
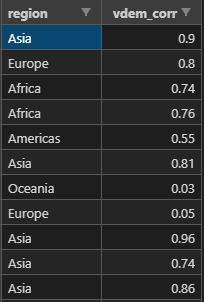
但我想在它下面有所有相應的“vdem_corr”值的列美洲、亞洲、歐洲、非洲等。如何在 python 中更改它?
uj5u.com熱心網友回復:
我的解決辦法是:
result = df.groupby('region').apply(lambda grp: pd.Series(
grp.vdem_corr.values)).unstack(level=1).T
與Prahken的回答相比,我的結果的NaN值要少得多。
自己嘗試并比較。
uj5u.com熱心網友回復:
df = pd.read_csv(...)
df.pivot(columns='region', values='vdem_corr')
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/355109.html