我是深度學習的新手,我制作了一個模型,假裝將 14x14 影像放大到 28x28。為此,我使用 MNIST 存盤庫訓練了 newtork 作為解決這個問題的第一次嘗試。
為了制作模型結構,我遵循了這篇論文: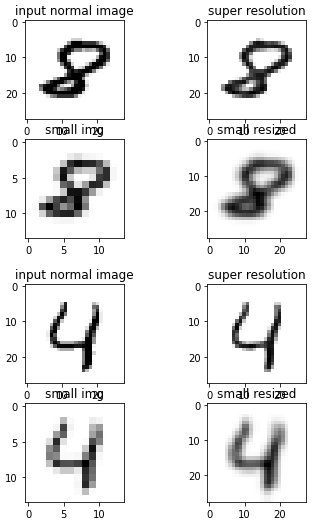
這是繪制數字的代碼:
def plot_images(num_img):
fig, axs = plt.subplots(2, 2)
my_normal_image = test_normal_array[num_img, :, :, 0]
axs[0, 0].set(title='input normal image')
axs[0, 0].imshow(my_normal_image, cmap=plt.cm.binary)
axs[1, 0].set(title = 'small img')
my_resized_image = resize(my_normal_image, anti_aliasing=True, output_shape=(14, 14))
axs[1, 0].imshow(my_resized_image, cmap=plt.cm.binary)
axs[0, 1].set(title='super resolution')
my_super_res_image = model.predict(my_resized_image[np.newaxis, :, :, np.newaxis])[0, :, :, 0]
axs[0, 1].imshow(my_super_res_image, cmap=plt.cm.binary)
axs[1, 1].set(title='small resized')
my_rr_image = resize(my_resized_image, output_shape=(28, 28), anti_aliasing=True)
axs[1, 1].imshow(my_rr_image, cmap=plt.cm.binary)
plt.show()
index = 8
plot_images(np.argwhere(y_test==index)[0][0])
index = 4
plot_images(np.argwhere(y_test==index)[0][0])
此外,這也是我構建資料集的方式:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
train_normal_array = np.expand_dims(x_train, axis=3)
test_normal_array = np.expand_dims(x_test, axis=3)
train_small_array = np.zeros((train_normal_array.shape[0], 14, 14, 1))
for i in tqdm.tqdm(range(train_normal_array.shape[0])):
train_small_array[i, :, :] = resize(train_normal_array[i], (14, 14), anti_aliasing=True)
test_small_array = np.zeros((test_normal_array.shape[0], 14, 14, 1))
for i in tqdm.tqdm(range(test_normal_array.shape[0])):
test_small_array[i, :, :] = resize(test_normal_array[i], (14, 14), anti_aliasing=True)
training_data = []
training_data.append([train_small_array.astype('float32'), train_normal_array.astype('float32') / 255])
testing_data = []
testing_data.append([test_small_array.astype('float32'), test_normal_array.astype('float32') / 255])
請注意,我不會分裂train_small_array和test_small_array由255調整大小做這項作業。
uj5u.com熱心網友回復:
我認為你的資料是不平衡的,所以如果模型只預測空白他最終會有一個很好的分數,所以在這種情況下準確度不適合判斷模型的性能。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/361882.html