我有一個父表Orders和一個子表,Jobs其中包含以下示例資料
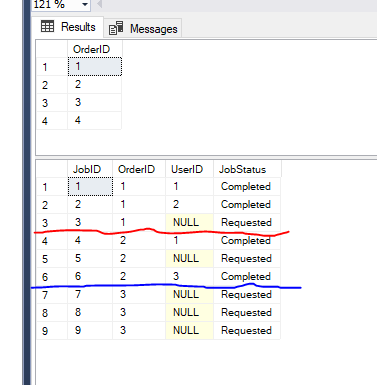
我想根據以下要求選擇訂單
1>每個訂單可能有0個或多個作業。如果沒有任何作業,請不要選擇訂單。
2> 一個用戶不能從事多個屬于同一訂單的作業。
例如用戶1不能屬于訂單1和2,因為他已經對就業作業的就業作業1,并4從相同的順序。
3>只選擇有作業Requested狀態的訂單
我有以下查詢,它給了我預期的結果
DECLARE @UserID INT = 2
SELECT O.OrderID
FROM Orders O
JOIN Jobs J ON J.OrderID = O.OrderID
WHERE
J.JobStatus = 'Requested' AND
NOT EXISTS
(
--Must not have worked this Order
SELECT 1 FROM Jobs J1
WHERE J1.OrderID = O.OrderID AND J1.UserID = @UserID
)
Group By o.OrderID
SQL 小提琴演示
查詢連接Jobs表兩次。我正在嘗試優化查詢并尋找一種方法,Jobs如果可能的話,只使用一次表來達到預期的結果。任何其他解決方案也值得贊賞。如果需要,我可以更改表架構。
作業表有近 2000 萬行,有時查詢顯示性能不佳。(是的,我們查看了索引)。我認為它的兩次掃描作業表導致了性能問題。
uj5u.com熱心網友回復:
如果目的只是“僅使用 Jobs 表一次”,我會嘗試以下操作:
DECLARE @UserID INT = 2
SELECT
O.OrderID
FROM
Orders O
INNER JOIN Jobs J ON J.OrderID = O.OrderID
GROUP BY
O.OrderID
HAVING
SUM(CASE WHEN J.JobStatus = 'Requested' THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN J.UserID = @UserId THEN 1 ELSE 0 END) = 0
SQL小提琴
為了進一步優化,我建議將列的varchar資料型別替換為一個(并創建一個表)。一旦你的表有 20M 記錄,然后給你 190 Mb,但是使用將列大小減少到 19 Mb - 這會給你更少的 IO-Read 操作。JobStatustinyintJobStatusesJobvarchar(10)tinyint
我會嘗試將孩子過濾與加入父母分開。這種方法可能會為單個操作使用更少的記憶體并贏得性能,因為:
DECLARE @UserID INT = 2
DECLARE @OrderIDs TABLE (OrderID INT NOT NULL PRIMARY KEY)
INSERT INTO @OrderIDs
SELECT
OrderID
FROM
Jobs
GROUP BY
OrderID
HAVING
SUM(CASE WHEN JobStatus = 'Requested' THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN UserID = @UserId THEN 1 ELSE 0 END) = 0
SELECT
O.*
FROM
Orders O
INNER JOIN @OrderIDs ids on ids.OrderID = O.OrderID
uj5u.com熱心網友回復:
您可以考慮將以下索引添加到Jobs表中:
CREATE INDEX idx_jobs ON Jobs (OrderID, UserID, JobStatus);
如果使用此索引,則應加速上述查詢中不存在的子查詢。此外,它還可用于外部頂級查詢中的from Ordersto連接Jobs(盡管 SQL Server 可能必須執行索引掃描)。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/362287.html
標籤:sql-server 查询语句 sql-server-2014 sql-server-2016 数据库性能
上一篇:在子查詢中使用WHERE子句查看