問題是:如何提高這個查詢的速度?
SELECT
c.CategoryName,
sc.SubcategoryName,
pm.ProductModel,
COUNT(p.ProductID) AS ModelCount
FROM Marketing.ProductModel pm
JOIN Marketing.Product p
ON p.ProductModelID = pm.ProductModelID
JOIN Marketing.Subcategory sc
ON sc.SubcategoryID = p.SubcategoryID
JOIN Marketing.Category c
ON c.CategoryID = sc.CategoryID
GROUP BY c.CategoryName,
sc.SubcategoryName,
pm.ProductModel
HAVING COUNT(p.ProductID) > 1
架構:
我嘗試創建一些索引并重新組織 JOIN 的順序。這絲毫沒有提高生產率。也許我需要其他索引或不同的查詢?
我的解決方案:
CREATE INDEX idx_Marketing_Subcategory_IDandName ON Marketing.Subcategory (CategoryID)
CREATE INDEX idx_Marketing_Product_PMID ON Marketing.Product (ProductModelID)
CREATE INDEX idx_Marketing_Product_SCID ON Marketing.Product (SubcategoryID)
SELECT
c.CategoryName,
sc.SubcategoryName,
pm.ProductModel,
COUNT(p.ProductID) AS ModelCount
FROM Marketing.Category AS c
JOIN Marketing.Subcategory AS SC
ON c.CategoryID = SC.CategoryID
JOIN Marketing.Product AS P
ON SC.SubcategoryID = p.SubcategoryID
JOIN Marketing.ProductModel AS PM
ON P.ProductModelID = PM.ProductModelID
GROUP BY c.CategoryName,
sc.SubcategoryName,
pm.ProductModel
HAVING COUNT(p.ProductID) > 1
UPD:
結果:
使用我的索引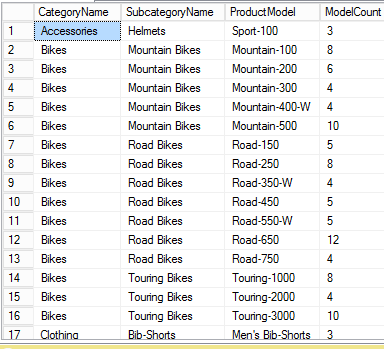
uj5u.com熱心網友回復:
您的查詢的成本為 0.12,這是微不足道的,行數也是如此,它以微秒為單位執行,行估計也相當接近,因此不清楚您要解決的問題是什么。
查看執行計劃,有一個鍵查找,ProductModelId估計成本為查詢的 44%,因此您可以通過在索引Product.idx_Marketing_Product_SCID 中包含該列,使用覆寫索引來消除這一點
Create index idx_Marketing_Product_SCID on Marketing.Product (SubcategoryID)
include (ProductModelId) with(drop_existing=on)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/362291.html
標籤:sql sql-server 查询语句
上一篇:T-SQL查詢以獲得所需的輸出