我有兩個資料框df1和subdf.
df1 看起來像這樣:
from pandas import Timestamp, Timedelta
df = pd.DataFrame({'station_key': {1300234: 'CV000011', 1300235: 'CV000011'},'charger_key': {1300234: 'CV00001101', 1300235: 'CV00001101'},'cid': {1300234: '01', 1300235: '01'},'x': {1300234: '33.489125', 1300235: '33.489125'},'y': {1300234: '126.487631', 1300235: '126.487631'},'snm': {1300234: '????(??)', 1300235: '????(??)'},'addr': {1300234: '??????? ??? ?? 251-69? ',1300235: '??????? ??? ?? 251-69? '},'addr_jibun': {1300234: '-', 1300235: '-'},'started_at': {1300234: Timestamp('2020-11-03 20:56:31'),1300235: Timestamp('2020-11-03 23:10:12')},'ended_at': {1300234: Timestamp('2020-11-03 23:10:12'),1300235: Timestamp('2020-11-03 23:40:12')},'status': {1300234: '2', 1300235: '1'},'day': {1300234: 'Tuesday', 1300235: 'Tuesday'},'time_usage': {1300234: Timedelta('0 days 02:13:41'),1300235: Timedelta('0 days 00:30:00')},'start': {1300234: Timestamp('2020-11-03 00:00:00'),1300235: Timestamp('2020-11-03 00:00:00')},'end': {1300234: Timestamp('2020-11-03 00:00:00'),1300235: Timestamp('2020-11-03 00:00:00')},'start_hour': {1300234: 20, 1300235: 23},'end_hour': {1300234: 23, 1300235: 23},'start_minute': {1300234: 56, 1300235: 10},'end_minute': {1300234: 10, 1300235: 40}})
subdf 看起來像這樣:
subdf = pd.DataFrame({'start': {1300234: Timestamp('2020-11-03 00:00:00'),4849001: Timestamp('2020-11-03 00:00:00')},'station_key': {1300234: 'CV000011', 4849001: 'CV000271'},'charger_key': {1300234: 'CV00001101', 4849001: 'CV00027101'},'cid': {1300234: '01', 4849001: '01'},'x': {1300234: '33.489125', 4849001: '33.452903'},'y': {1300234: '126.487631', 4849001: '126.572552'},'snm': {1300234: '????(??)', 4849001: '????????(?????)'},'0_occupation': {1300234: 0, 4849001: 0},'1_occupation': {1300234: 0, 4849001: 0},'2_occupation': {1300234: 0, 4849001: 0},'3_occupation': {1300234: 0, 4849001: 0},'4_occupation': {1300234: 0, 4849001: 0},'5_occupation': {1300234: 0, 4849001: 0},'6_occupation': {1300234: 0, 4849001: 0},'7_occupation': {1300234: 0, 4849001: 0},'8_occupation': {1300234: 0, 4849001: 0},'9_occupation': {1300234: 0, 4849001: 0},'10_occupation': {1300234: 0, 4849001: 0},'11_occupation': {1300234: 0, 4849001: 0},'12_occupation': {1300234: 0, 4849001: 0},'13_occupation': {1300234: 0, 4849001: 0},'14_occupation': {1300234: 0, 4849001: 0},'15_occupation': {1300234: 0, 4849001: 0},'16_occupation': {1300234: 0, 4849001: 0},'17_occupation': {1300234: 0, 4849001: 0},'18_occupation': {1300234: 0, 4849001: 0},'19_occupation': {1300234: 0, 4849001: 0},'20_occupation': {1300234: 0, 4849001: 0},'21_occupation': {1300234: 0, 4849001: 0},'22_occupation': {1300234: 0, 4849001: 0},'23_occupation': {1300234: 0, 4849001: 0}})
該_occupation列代表小時所以有這樣的24列范圍從0_occupation到23_occupation
我試圖申請的功能df1如下:
def time_add(x):
s_date = x['start']
e_date = x['end']
s_hour = x['start_hour']
e_hour = x['end_hour']
s_min = x['start_minute']
e_min = x['end_minute']
if(s_date == e_date):
first_range = list(range(s_hour 1, e_hour))
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(s_hour) "_occupation"] =((60 - s_min)/60)*100
for i in first_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(i) "_occupation"] = 1
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(e_hour) "_occupation"] =(e_min/60)*100
else:
first_range = list(range(s_hour 1, 24))
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(s_hour) "_occupation"] =((60 - s_min)/60)*100
for i in first_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(i) "_occupation"] = 1
second_range = list(range(0, e_hour))
for i in second_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date 1), str(i) "_occupation"] = 1
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date 1), str(e_hour) "_occupation"] =(e_min/60)*100
但是,當我嘗試通過執行time_add(df1)錯誤來應用它時:
The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
我查了一下,這個錯誤似乎在使用andandor而不是&and時發生,|但在我的函式中不是這種情況。
錯誤的完整回溯如下
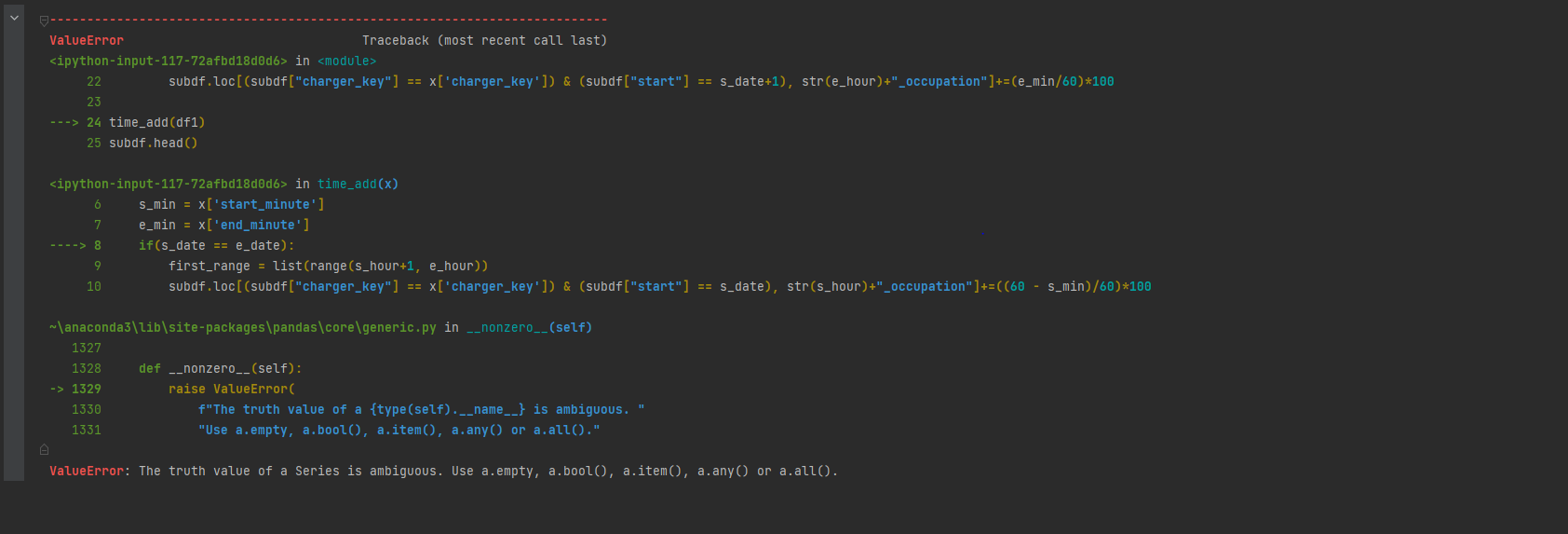
先感謝您!!
uj5u.com熱心網友回復:
在這一行:
if(s_date == e_date):
在s_date和e_date變數不是單一的值,但整個列從你的熊貓資料幀。當您比較它們時,這意味著什么?您想檢查一列中的所有值是否都等于另一列中的值嗎?或者您想檢查是否至少有一個值等于相應的值?或者你想根據這兩列中的對應值是否相等對行做不同的事情?
if (s_date == e_date).all():
# True if ALL values are equal.
或者,
if (s_date == e_date).any():
# True if AT LEAST ONE value is equal.
uj5u.com熱心網友回復:
正如 Dietrich 指出的,s_dateande_date以及在函式頂部宣告的所有其他變數都是Series's。它們是資料框中的整列。但我懷疑那不是你什么。您正在嘗試time_add為每一行運行。但你沒有這樣做,因為你正在呼叫time_add(df1). 它將在整個資料幀上執行,索引它將回傳一整列。
改變
time_add(df1)
到
df = df1.apply(time_add, axis=1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/363352.html