我在資料框中有 4D 資料。我需要將它轉換為 3D Numpy 陣列。我可以用 for 回圈來做,但有沒有更有效的方法?
# Data:
df = pd.DataFrame()
df['variable'] = ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'A',
'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'D', 'D', 'D']
df['date'] = [101,102,103]*8
df['itemID'] = ['item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item2',
'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2']
df['value1'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12]
df['value2'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12]
df['value3'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12]
df['value4'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12]
# Pivoting:
pivoted = df.pivot(index=['itemID', 'date'], columns='variable', values=[*df.columns[df.columns.str.startswith('value')]])
pivoted.index.levshape
級別形狀為:(2, 3)
它看起來像這樣:
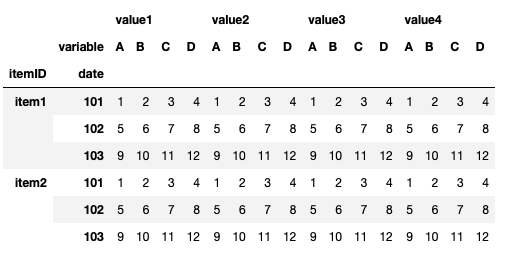
# To Numpy:
pivoted2array = pivoted.to_numpy()
pivoted2array.shape
現在的形狀是:(6, 16)
# Reshaping to 3D:
pivoted2array3d = pivoted2array.reshape(*pivoted.index.levshape,-1)
pivoted2array3d.shape
形狀現在是:(2, 3, 16)
它看起來像這樣:
array([[[ 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4],
[ 5, 6, 7, 8, 5, 6, 7, 8, 5, 6, 7, 8, 5, 6, 7, 8],
[ 9, 10, 11, 12, 9, 10, 11, 12, 9, 10, 11, 12, 9, 10, 11, 12]],
[[ 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4],
[ 5, 6, 7, 8, 5, 6, 7, 8, 5, 6, 7, 8, 5, 6, 7, 8],
[ 9, 10, 11, 12, 9, 10, 11, 12, 9, 10, 11, 12, 9, 10, 11, 12]]])
這是我使用 for 回圈轉換(重新排序)值的麻煩部分:
dimension3 = []
for k in range(pivoted2array3d.shape[0]): # unique items
for j in range(pivoted2array3d.shape[1]): # unique dates
for i in range(pivoted2array3d.shape[2])[0:pivoted2array3d.shape[2]:4]:
element = pivoted2array3d[k][j][i]
dimension3.append(element)
for l in range(pivoted2array3d.shape[2])[0 1:pivoted2array3d.shape[2]:4]:
element = pivoted2array3d[k][j][l]
dimension3.append(element)
for m in range(pivoted2array3d.shape[2])[0 2:pivoted2array3d.shape[2]:4]:
element = pivoted2array3d[k][j][m]
dimension3.append(element)
for n in range(pivoted2array3d.shape[2])[0 3:pivoted2array3d.shape[2]:4]:
element = pivoted2array3d[k][j][n]
dimension3.append(element)
len(dimension3)
結果我有一個長度為 96 的串列。
然后我將它重塑回 3D Numpy 陣列:
final = np.array(dimension3).reshape(*pivoted2array3d.shape)
final.shape
它再次具有形狀:(2, 3, 16)
最終結果如下所示:
array([[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]],
[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]]])
是否有計算上更優雅的方法來重新排序我的陣列?有沒有辦法減少重塑步驟?我真的很想學習如何使用 Numpy 操作!
我的真實資料包括數千個專案、數百個日期、數十個變數和值變數。
測驗建議的解決方案
感謝 Shubham Sharma、Quang Hoang 和 mathfux 提供的解決方案。我只為 item1 添加了一個日期,并需要為 item2 填充缺失的日期,從而使初始資料變得更加復雜。建議的解決方案仍然有效。
新資料:
df = pd.DataFrame()
df['variable'] = ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'A',
'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'A', 'B', 'C', 'D']
df['date'] = [101,102,103]*8 [104,104,104,104]
df['itemID'] = ['item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item1', 'item2',
'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2', 'item2']
df['value1'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12,13,13,13,13]
df['value2'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12,13,13,13,13]
df['value3'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12,13,13,13,13]
df['value4'] = [1,5,9,2,6,10,3,7,11,4,8,12,1,5,9,2,6,10,3,7,11,4,8,12,13,13,13,13]
旋轉和重新索引:
pivoted = df.pivot(index=['itemID', 'date'], columns='variable', values=[*df.columns[df.columns.str.startswith('value')]])
m = pd.MultiIndex.from_product([df['itemID'].unique(),df['date'].unique()], names=pivoted.index.names)
pt = pivoted.reindex(m, fill_value = 0)
解決方案1:
%%time
pt.sort_index(level=1, axis=1)\
.values.reshape(*pivoted.index.levshape[:2], -1)
CPU 時間:用戶 895 微秒,系統:135 微秒,總計:1.03 毫秒掛墻時間:930 微秒
解決方案2:
%%time
pt.stack(level=0).unstack().to_numpy().reshape(-1, df.date.nunique(), pt.shape[1])
CPU 時間:用戶 6.53 毫秒,系統:1.62 毫秒,總計:8.15 毫秒掛墻時間:6.58 毫秒
解決方案3:
%%time
pivoted2array3d = pt.to_numpy().reshape(*pivoted.index.levshape,-1)
pivoted2array3d.reshape(2,df.date.nunique(),4,4).swapaxes(2,3).reshape(2,df.date.nunique(),16)
CPU 時間:用戶 421 μs,系統:27 μs,總計:448 μs 掛墻時間:435 μs
uj5u.com熱心網友回復:
看起來您只需要交換 的列級別pivoted:
a = df.pivot(index=['itemID','date'], columns=['variable']).stack(level=0).unstack()
a.to_numpy().reshape(-1, df.date.nunique(), a.shape[1])
輸出:
array([[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]],
[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]]])
uj5u.com熱心網友回復:
我們可以嘗試對列進行排序,然后reshape使用索引級別
pivoted.sort_index(level=1, axis=1)\
.values.reshape(*pivoted.index.levshape[:2], -1)
array([[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]],
[[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4],
[ 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8],
[ 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 12, 12, 12, 12]]])
uj5u.com熱心網友回復:
看起來np.swapaxes你需要的技巧是: arr.reshape(2,3,4,4).swapaxes(2,3).reshape(2,3,16)
主要思想是交換最內部資料中的軸:
[ 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4] ->
[[ 1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]] ->
[ 1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]] ->
[ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/365846.html
下一篇:如果不在物件陣列內觸發